Project A: WebScraper
A script that prints out a list of all EXTERNAL references in the HTML response to an HTTP/S request.
Installing all dependencies
pip install -r requirements.txt or pip3 install -r requirements.txt
Executing the script
python3 external_link.py [URL] \ URL be http://www.abc.com or https://www.abc.com
Example of code USAGE
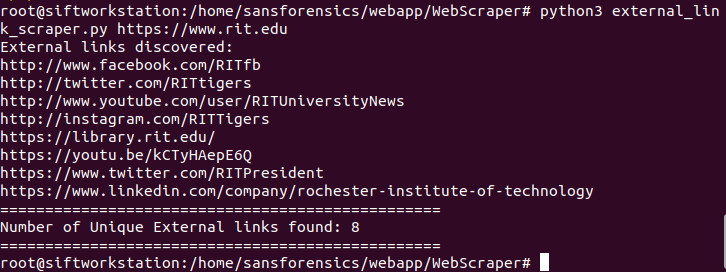
python3 external_link_scraper.py https://www.rit.edu

 512 Jan 03, 2023
512 Jan 03, 2023
 2.6k Dec 31, 2022
2.6k Dec 31, 2022
 38 Nov 05, 2022
38 Nov 05, 2022
 1 Dec 30, 2021
1 Dec 30, 2021
 6 Nov 21, 2022
6 Nov 21, 2022
 1 Nov 14, 2021
1 Nov 14, 2021
 45.5k Jan 07, 2023
45.5k Jan 07, 2023
 5 Jan 04, 2022
5 Jan 04, 2022
 5 Nov 22, 2022
5 Nov 22, 2022
 1 Dec 20, 2021
1 Dec 20, 2021
 1 Nov 17, 2022
1 Nov 17, 2022
 2 Jun 06, 2022
2 Jun 06, 2022
 15.7k Jan 04, 2023
15.7k Jan 04, 2023
 229 Dec 12, 2022
229 Dec 12, 2022
 31 Apr 17, 2022
31 Apr 17, 2022
 1 Nov 26, 2021
1 Nov 26, 2021
 27 Dec 18, 2022
27 Dec 18, 2022
 2 Dec 22, 2021
2 Dec 22, 2021
 5 Oct 29, 2021
5 Oct 29, 2021
 2 Jul 22, 2022
2 Jul 22, 2022