wxee


What is wxee?
wxee was built to make processing gridded, mesoscale time series weather and climate data quick and easy by integrating the data catalog and processing power of Google Earth Engine with the flexibility of xarray, with no complicated setup required. To accomplish this, wxee implements convenient methods for data processing, aggregation, downloading, and ingestion.
Features
- Time series image collections to xarray, NetCDF, or GeoTIFF in one line of code
- Climatological means and temporal aggregation
- Parallel processing for fast downloads
Install
Pip
pip install wxee
Conda
conda install -c conda-forge wxee
From Source
git clone https://github.com/aazuspan/wxee
cd wxee
make install
Quickstart
Setup
Once you have access to Google Earth Engine, just import and initialize ee and wxee.
import ee
import wxee
ee.Initialize()
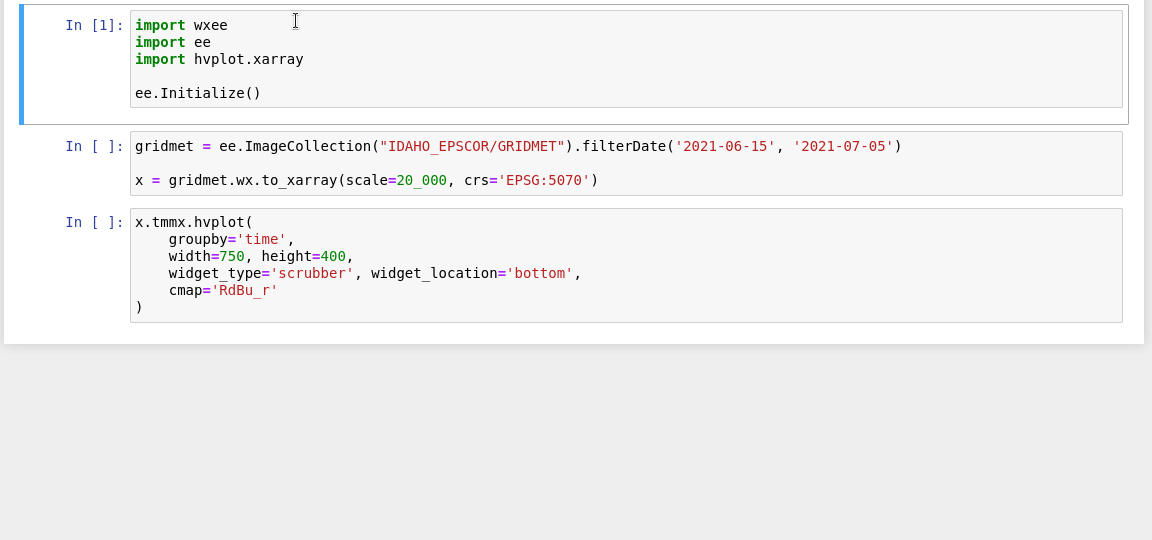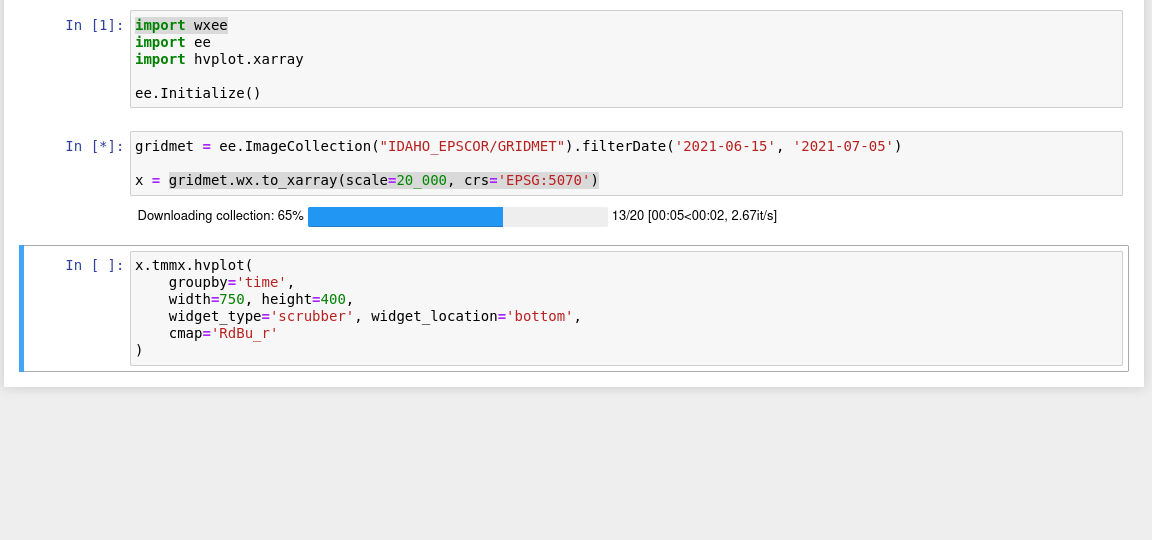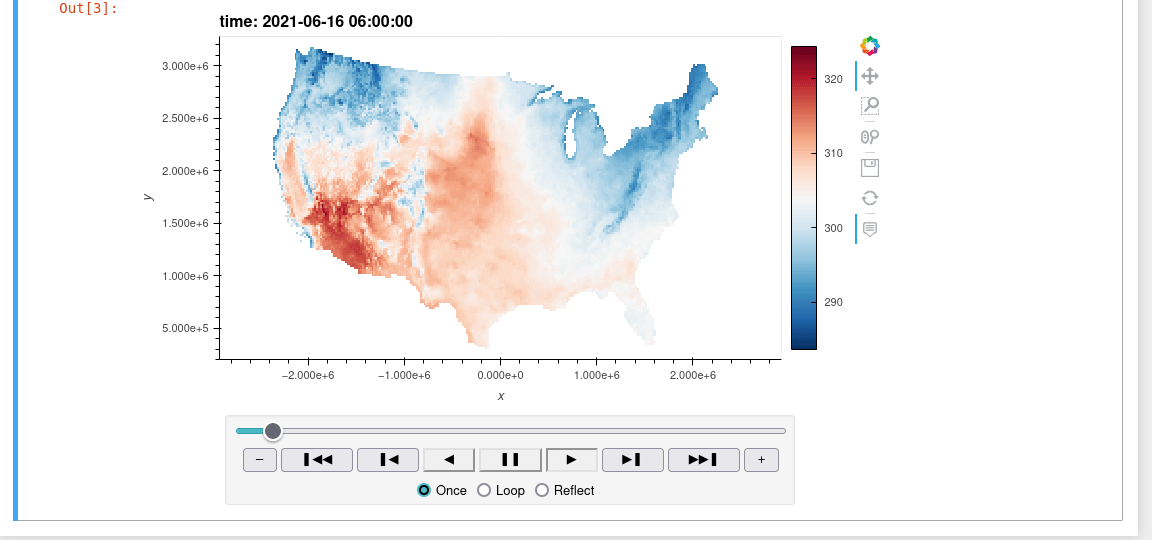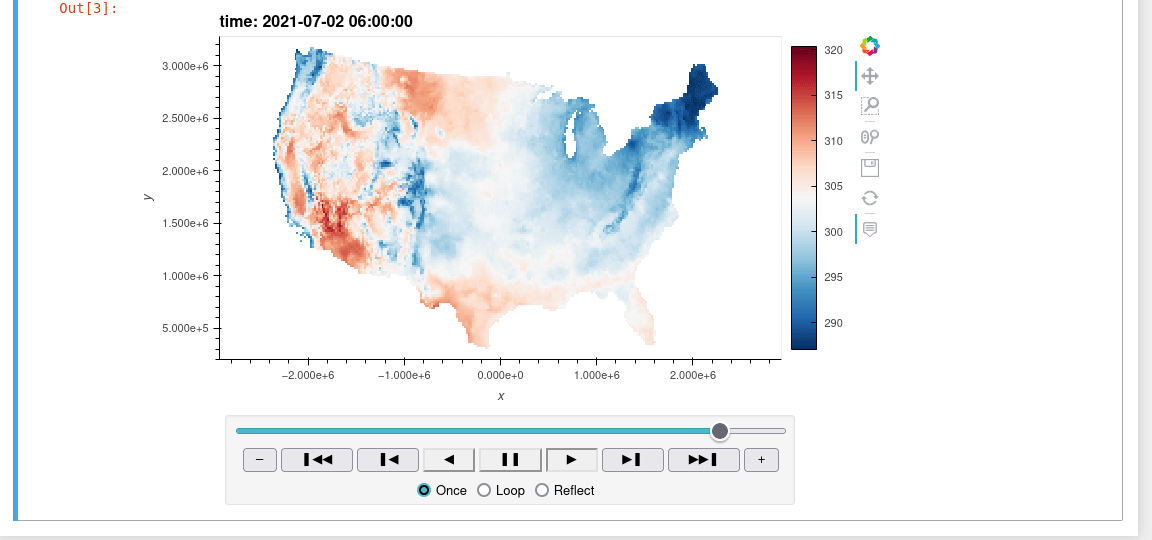
Download Images
Download and conversion methods are extended to ee.Image and ee.ImageCollection using the wx accessor. Just import wxee and use the wx accessor.
xarray
ee.ImageCollection("IDAHO_EPSCOR/GRIDMET").wx.to_xarray()
NetCDF
ee.ImageCollection("IDAHO_EPSCOR/GRIDMET").wx.to_xarray(path="data/gridmet.nc")
GeoTIFF
ee.ImageCollection("IDAHO_EPSCOR/GRIDMET").wx.to_tif()
Create a Time Series
Additional methods for processing image collections in the time dimension are available through the TimeSeries subclass. A TimeSeries can be created from an existing ee.ImageCollection...
col = ee.ImageCollection("IDAHO_EPSCOR/GRIDMET")
ts = col.wx.to_time_series()
Or instantiated directly just like you would an ee.ImageCollection!
ts = wxee.TimeSeries("IDAHO_EPSCOR/GRIDMET")
Aggregate Daily Data
Many weather datasets are in daily or hourly resolution. These can be aggregated to coarser resolutions using the aggregate_time method of the TimeSeries class.
ts = wxee.TimeSeries("IDAHO_EPSCOR/GRIDMET")
monthly_max = ts.aggregate_time(frequency="month", reducer=ee.Reducer.max())
Calculate Climatological Means
Long-term climatological means can be calculated using the climatology_mean method of the TimeSeries class.
ts = wxee.TimeSeries("IDAHO_EPSCOR/GRIDMET")
mean_clim = ts.climatology_mean(frequency="month")
Contribute
Bugs or feature requests are always appreciated! They can be submitted here.
Code contributions are also welcome! Please open an issue to discuss implementation, then follow the steps below. Developer setup instructions can be found in the docs.







 12 Aug 16, 2021
12 Aug 16, 2021
 2 Oct 10, 2021
2 Oct 10, 2021
 12 Jul 21, 2022
12 Jul 21, 2022
 9 Sep 27, 2022
9 Sep 27, 2022
 39 Oct 30, 2022
39 Oct 30, 2022
 1 Jan 08, 2022
1 Jan 08, 2022
 2 Apr 08, 2022
2 Apr 08, 2022
 2 Dec 11, 2022
2 Dec 11, 2022
 1 Feb 12, 2022
1 Feb 12, 2022
 121 Jan 01, 2023
121 Jan 01, 2023
 450 Dec 27, 2022
450 Dec 27, 2022
 73 Dec 12, 2022
73 Dec 12, 2022
 14 Nov 16, 2022
14 Nov 16, 2022
 9 Mar 10, 2022
9 Mar 10, 2022
 27 May 13, 2022
27 May 13, 2022
 8 Nov 22, 2022
8 Nov 22, 2022
 7 Dec 18, 2022
7 Dec 18, 2022
 1 Jun 19, 2021
1 Jun 19, 2021
 2.9k Jan 01, 2023
2.9k Jan 01, 2023
 0 Mar 25, 2022
0 Mar 25, 2022