hop
Simple archive format designed for quickly reading some files without extracting the entire archive. Possibly will be used in Bun.
25x faster than unzip and 10x faster than tar at reading individual files (uncompressed)

| Format | Random access | Fast extraction | Fast archiving | Compression | Encryption | Append |
|---|---|---|---|---|---|---|
| hop | |
|
|
|
|
|
| tar | |
|
|
|
|
|
| zip | |
|
|
|
|
|
Features:
- Faster at printing individual files than
tar&zip(compression disabled) - Faster extraction than
zip, comparable totar(compression disabled) - Faster archiving than
zip, comparable totar(compression disabled)
Anti-features:
- Single-threaded (but doesn't need to be)
- I wrote it in about 3 hours and there are no tests
- No checksums yet. Probably not a good idea to use this for untrusted data until that's fixed.
- Ignores symlinks
- Can't be larger than 4 GB
- Archives are read-only and file names are not normalized across platforms
Usage
Download the binary from /releases
To create an archive:
hop ./path-to-folder
To extract an archive:
hop archive.hop
To print one file from the archive:
hop archive.hop package.json
Why?
Why can't software read many tiny files with similar performance characteristics as individual files?
- Reading and writing lots of tiny files incurs significant syscall overhead, and (npm) packages often have lots of tiny files. Zip files are unacceptably slow to read from like a directory. tar files extract quickly, but are slow at non-sequential access.
- Reading directory entries (
ls) in large directory trees is slow
Some benchmarks
On macOS 12 with an M1X
Using tigerbeetle github repo as an example
Extracting:
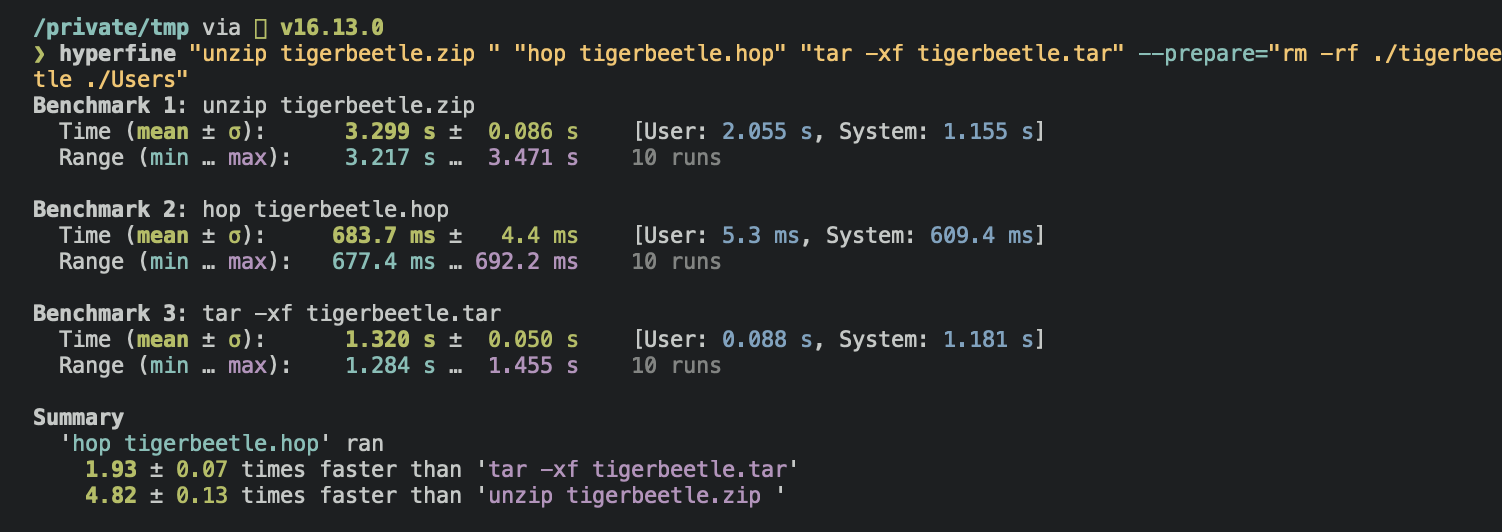
Archiving:

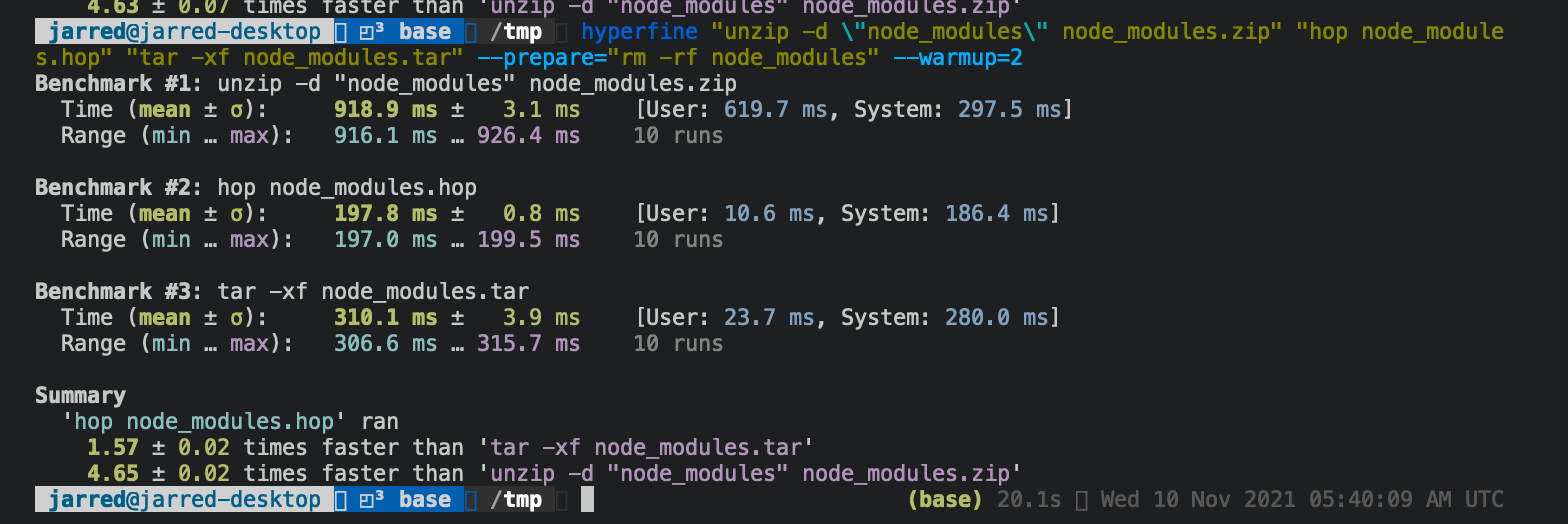
On an Ubuntu AMD64 server
Extracting a node_modules folder
Why faster?
- It stores an array of hashes for each file path and the list of files are sorted lexigraphically. This makes non-sequential access faster than tar, but can make creating new archives slower.
- Does not store directories, only files
- .hop files are read-only (more precisely, one could append but would have to rewrite all metadata)
copy_file_rangepacked structmakes serialization & deserialization very fast because there is very little encoding/decoding step.
How does it work?
- File contents go at the top, file metadata goes at the bottom
- This is the metadata it currently stores:
package Hop;
struct StringPointer {
uint32 off;
uint32 len;
}
struct File {
StringPointer name;
uint32 name_hash;
uint32 chmod;
uint32 mtime;
uint32 ctime;
StringPointer data;
}
message Archive {
uint32 version = 1;
uint32 content_offset = 2;
File[] files = 3;
uint32[] name_hashes = 4;
byte[] metadata = 5;
}

 2 Feb 7, 2022
2 Feb 7, 2022
 12 Jan 1, 2023
12 Jan 1, 2023
 1 Dec 14, 2021
1 Dec 14, 2021
 38 Dec 31, 2022
38 Dec 31, 2022
 2 Nov 20, 2022
2 Nov 20, 2022
 1 Nov 25, 2021
1 Nov 25, 2021
 2 Apr 17, 2022
2 Apr 17, 2022

 1 Nov 9, 2021
1 Nov 9, 2021
 82 Nov 24, 2022
82 Nov 24, 2022



 0 Dec 03, 2022
0 Dec 03, 2022
 4 Oct 17, 2022
4 Oct 17, 2022
 1 Feb 05, 2022
1 Feb 05, 2022
 1 Jan 13, 2022
1 Jan 13, 2022
 3 Apr 28, 2022
3 Apr 28, 2022
 2 Feb 21, 2022
2 Feb 21, 2022
 1.5k Jan 01, 2023
1.5k Jan 01, 2023
 15 Dec 18, 2022
15 Dec 18, 2022
 3 Feb 09, 2022
3 Feb 09, 2022
 53 Nov 07, 2022
53 Nov 07, 2022
 4 Jun 07, 2022
4 Jun 07, 2022
 2 Nov 20, 2021
2 Nov 20, 2021
 506 Dec 29, 2022
506 Dec 29, 2022
 14 Dec 30, 2022
14 Dec 30, 2022
 2 Jun 20, 2022
2 Jun 20, 2022
 497 Jan 05, 2023
497 Jan 05, 2023
 32 Dec 14, 2022
32 Dec 14, 2022
 1 Feb 02, 2022
1 Feb 02, 2022
 1 Nov 12, 2021
1 Nov 12, 2021
 8 Nov 02, 2022
8 Nov 02, 2022