当前位置:网站首页>HiBench生成基准数据集【WordCount为例】
HiBench生成基准数据集【WordCount为例】
2022-07-16 21:21:00 【Huang3stone】
1.下载HiBench
官网地址:https://github.com/Intel-bigdata/HiBench/tree/HiBench-7.1

2.上传服务器
过程略
3.解压文件
由于压缩包是.zip文件,无法使用tar解压,需要下载unzip
yum install unzip
unzip xxx.zip
4.修改配置文件
- 进入到conf目录
cp hadoop.conf.template hadoop.conf
- 修改 hadoop.conf(根据自己节点情况配置)
# Hadoop home
hibench.hadoop.home /usr/local/hadoop-3.1.1
# The path of hadoop executable
hibench.hadoop.executable ${hibench.hadoop.home}/bin/hadoop
# Hadoop configraution directory
hibench.hadoop.configure.dir ${hibench.hadoop.home}/etc/hadoop
# The root HDFS path to store HiBench data
hibench.hdfs.master hdfs://192.168.152.109:9820/hibench
# Hadoop release provider. Supported value: apache, cdh5, hdp
hibench.hadoop.release apache
~
- 进入conf/workloads/micro/,wordcount.conf文件配置的是生成的数据量大小
这里我自定义了一个1G大小的数据集
#datagen
#hibench.wordcount.tiny.datasize 32000
#hibench.wordcount.small.datasize 320000000
#hibench.wordcount.large.datasize 3200000000
#hibench.wordcount.huge.datasize 32000000000
#hibench.wordcount.gigantic.datasize 320000000000
#hibench.wordcount.bigdata.datasize 1600000000000
hibench.wordcount.large.datasize 1073741824
hibench.workload.datasize ${hibench.wordcount.${hibench.scale.profile}.datasize}
# export for shell script
hibench.workload.input ${hibench.hdfs.data.dir}/Wordcount/Input
hibench.workload.output ${hibench.hdfs.data.dir}/Wordcount/Output
- 配置conf/hibench.conf
注意标记处类型要与上面wordcount.conf定义的大小名称相同!

7. 执行测试脚本
在bin/run_all.sh 该脚本为测试所有的测试基准模块(将运行所有在conf/benchmarks.lst和conf/frameworks.lst中的workloads);
这里还是以wordcount为例,
①生成测试数据 bin/workloads/micro/wordcount/prepare/prepare.sh
②运行wordcount测试例子 bin/workloads/micro/wordcount/hadoop/run.sh
③生成的测试数据在conf/hadoop.conf中hibench.hdfs.master项配置,我的是在/user/hibench/HiBench目录下
执行命令①
生成成功!
边栏推荐
- Quickly build an e-commerce platform based on Amazon cloud technology server free service - Deployment
- [development tutorial 3] crazy shell arm function mobile phone - Introduction to the whole board resources
- How does go ensure the order of concurrent reads and writes Memory model
- C # find perfect numbers, output daffodils and use of classes
- 【决策树】使用决策树进行乳腺癌的诊断
- Picasso, an efficient search generalization sparse training solution
- npm 和 npx 的区别
- 11、摸清JVM对象分布
- Generate multiple databases at the same time based on multiple data sources and zero code, add, delete, modify and check restful API interfaces - mysql, PostgreSQL, Oracle, Microsoft SQL server multip
- ADB常用入门指令
猜你喜欢

Buffer Pool 核心原理
![Collaboration process [simple summary]](/img/ee/12679490e540dc5897c9e84b14473b.png)
Collaboration process [simple summary]
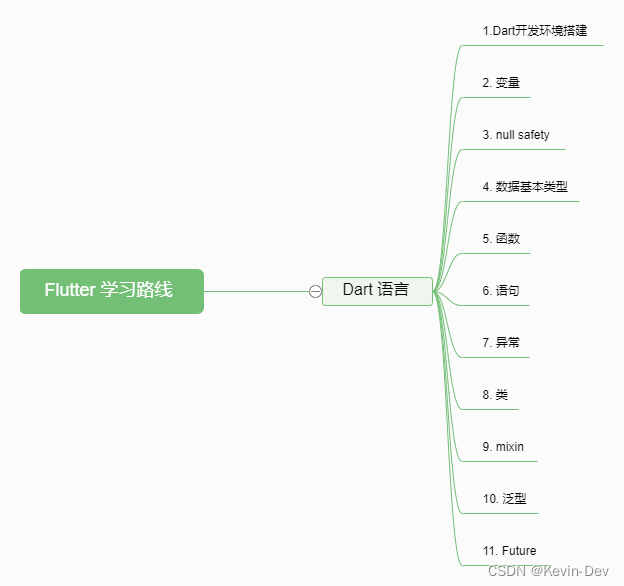
【Flutter--实战】Dart 语言快速入门
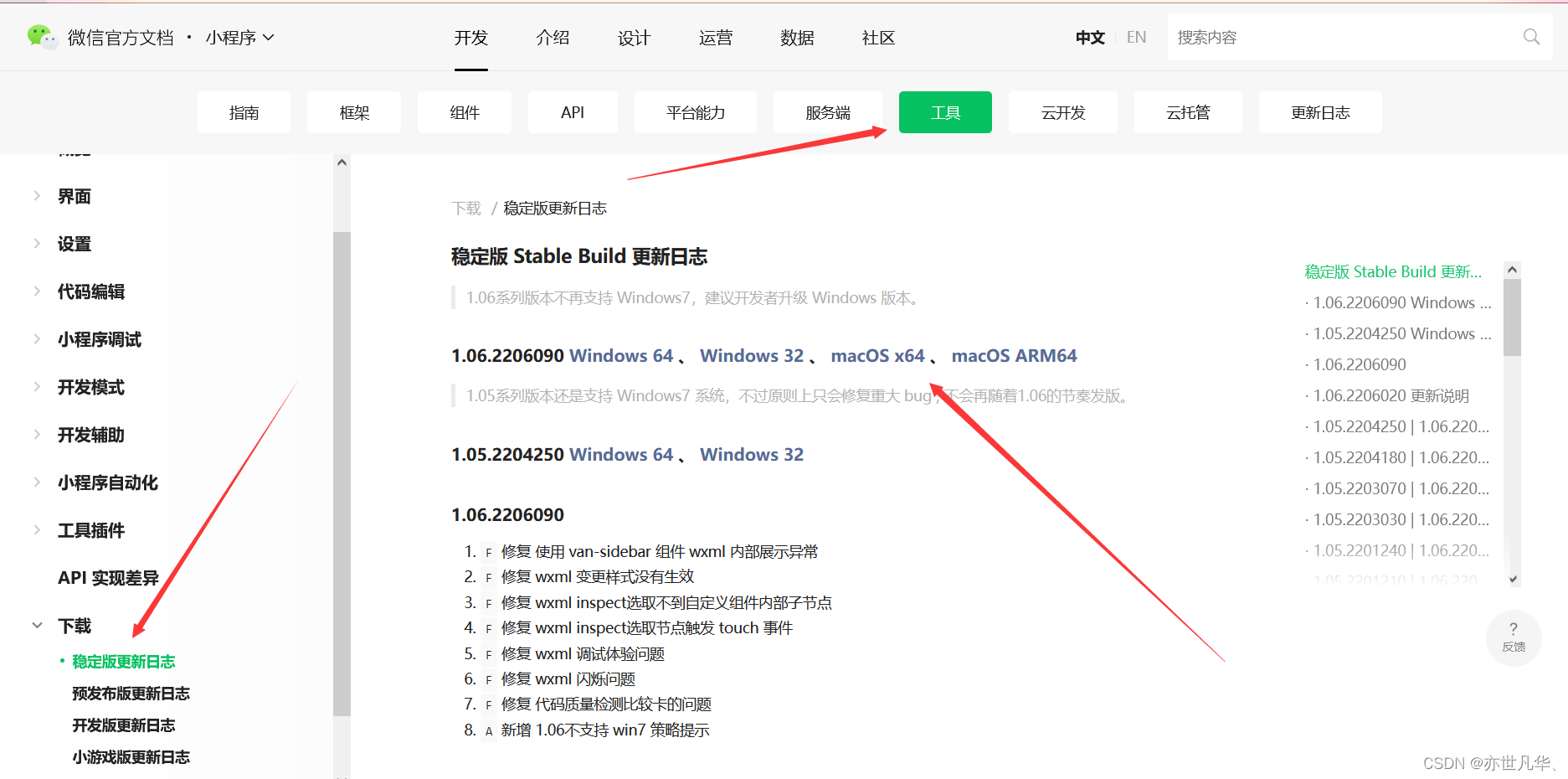
微信小程序--》小程序简介与工具安装配置

Cloud native: docker's practical experience (IV) deploying redis three master and three slave clusters on docker

开发者必看 | DevWeekly 第1期:什么是时间复杂度?
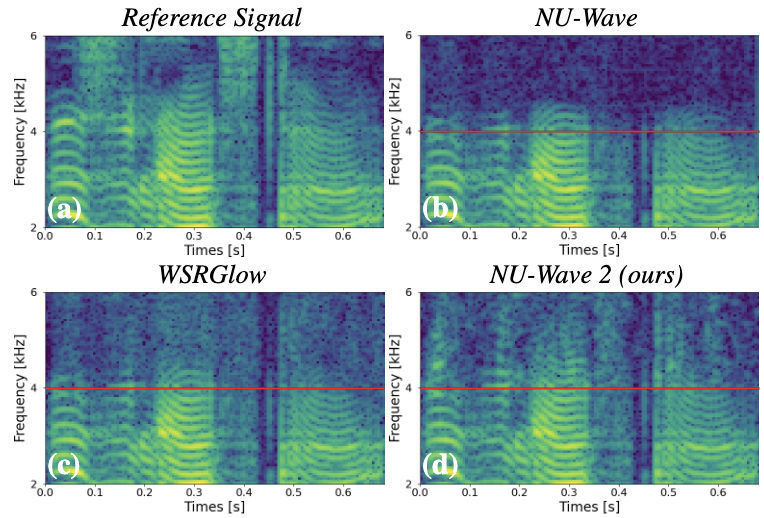
嘘!摸鱼神器,别让老板知道!| 语音实时转文本,时序快速出预测,YOLOv6在就能用,一行命令整理CSV | ShowMeAI资讯日报
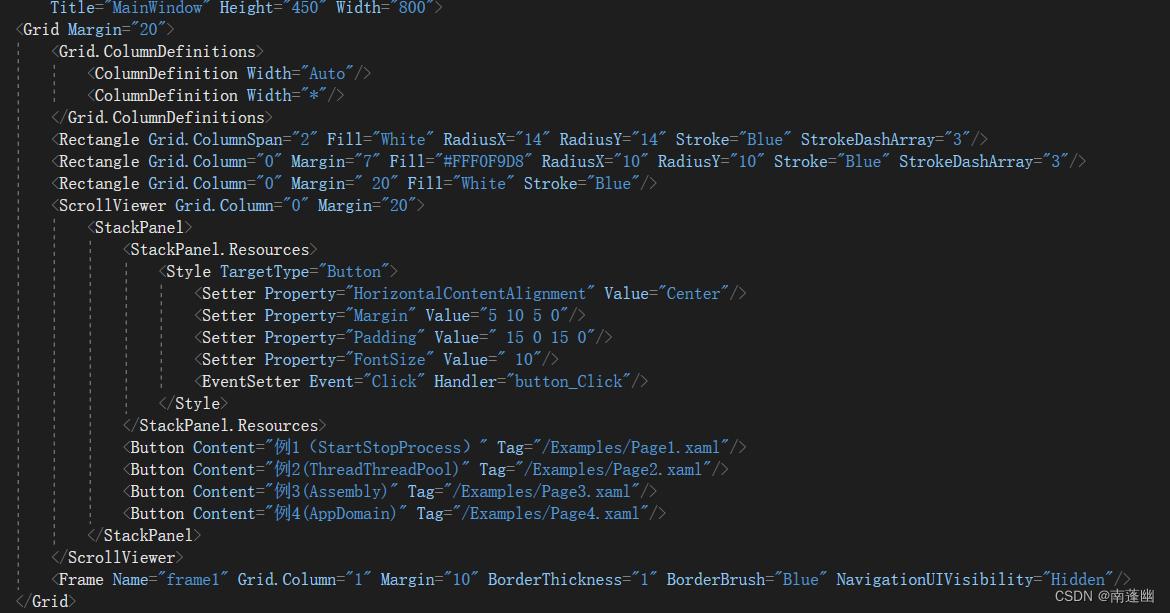
C # network application programming, experiment 7: asynchronous programming practice

Mysql存储模型
Mysql的锁机制
随机推荐
C # network application programming, experiment 1: WPF exercise
VI editor sets custom shortcut keys to automatically generate the main function of C language
Progress [detailed summary]
Supervised learning week 3: logistic regression option_ Lab harvest record
Three scenarios take you to unit testing
[Ji Zhong] July 13, 2022 3058 Torchbearer
深入剖析斐波拉契数列
6. JVM generational model -- garbage collection in the old age
Send papers! AI, machine learning, CV boss scientific research project enrollment!
[CVPR2019] On Stabilizing Generative Adversarial Training with Noise
10、摸清JVM运行状况
剑指 Offer II 119. 最长连续序列
Wanzi detailed C language document
Siemens module 6dd1661-0ae1
Summer study matlab notes
Deep analysis of fiboracci sequence
Dameng database table SQL statement
面试官:说一下你工作中发现的最有价值的bug
【开发教程1】开源蓝牙心率防水运动手环-套件检测教程
ASP. Net printing industry printing management system, source code free sharing