当前位置:网站首页>regular expression
regular expression
2022-07-19 07:06:00 【W_ chuanqi】
Personal profile
Author's brief introduction : Hello everyone , I am a W_chuanqi, A programming enthusiast
Personal home page :W_chaunqi
Stand by me : give the thumbs-up + Collection ️+ Leaving a message.
May you and I share :“ If you are in the mire , The heart is also in the mire , Then all eyes are muddy ; If you are in the mire , And I miss Kun Peng , Then you can see 90000 miles of heaven and earth .”

List of articles
Regular expressions
We are using requests Library to get the source code of web pages , obtain HTML Code . But the data we really want is contained in HTML In the code , How can we get from HTML Get the information you want from the code ? Regular expression is one of the effective methods .
Now let's learn about the usage of regular expressions . Regular expressions are a powerful tool for handling strings , It has its own specific grammatical structure , With it , Achieve string retrieval 、 Replace 、 Match verification is no problem .
Of course , For reptiles , With it , from HTML It's very convenient to extract the information you want .
1. Instance Introduction
Let's take a look at its usage with several examples .
Open the regular expression testing tool provided by open source China http://tool.oschina.net/regex/, Enter the text to be matched , Then select the regular expression that is commonly used , You can get the corresponding matching results . for example , Enter the following text to match here .
Hello, my phone number is 010-86432100 and email is [email protected].com,and my website is https://123456abc.com
This string contains a phone number 、 One E-mail Address and a URL, Next, try to extract these contents with regular expressions .
Select... On the right side of the page “ matching Email Address bar ”, You can see that... Appears in the text below E-mail, As shown in the figure below .

If you choose “ Match URL URL”, You can see that... Appears in the text below URL, As shown in the figure below .

Actually , Here is the regular expression matching , That is to extract specific text with certain rules . for example ,E-mail The address begins with a string , And then a @ Symbol , Finally, a domain name , This has a specific composition format . in addition , about URL, The protocol type starts with , Then a colon and a double slash , Finally, the domain name plus path .
about URL Come on , You can use the following regular expression to match .
[a-zA-z]+://[^\s]*
Use this regular expression to match a string , If this string contains something like URL The text of , Then this part will be extracted .
Regular expressions look like a mess , But there are specific grammatical rules in it . for example ,a-z Represents matching any lowercase letter ,\s Represents matching any white space character ,* Represents matching any number of preceding characters , That long string of regular expressions is the combination of so many matching rules .
After writing the regular expression , You can use it to find a match in a long string . Whatever's in this string , As long as it complies with the rules we write , You can find it all . For web pages , If you want to find out how many pages are in the source code URL, Just match URL Just match the regular expression of .
The following table lists some common matching rules .
| Pattern | describe |
|---|---|
| \w | Match the letter 、 Numbers and underscores |
| \W | Match is not a letter 、 Numbers and underlined characters |
| \s | Match any white space character , Equivalent to [\t\n\r\f] |
| \S | Match any non null character |
| \d | Match any number , Equivalent to [0-9] |
| \D | Match any non numeric character |
| \A | Match the beginning of a string |
| \Z | Match string end . If there is a newline , Matches only the ending string before the line break |
| \z | Match string end . If there is a newline , It also matches the newline character |
| \G | Match where the last match is done |
| \n | Match a line break |
| \t | Match a tab |
| ^ | Match the beginning of a line of string |
| $ | Match the end of a line of string |
| . | Match any character , Except for line breaks , When re.DOTALL When the mark is specified , It can match any character including newline |
| […] | Used to represent a set of characters , List... Separately , for example [amk] To match a、m or k |
| [^…] | The match is not in [] The characters in , For example, match except a、b、c Other characters |
| * | matching 0 One or more expressions |
| + | matching 1 One or more expressions |
| ? | matching 0 Or 1 A fragment defined by the previous regular expression , Not greedy |
| {n} | Exactly match π The previous expression |
| {n,m} | matching n To m The fragment defined by the previous regular expression , Greedy way |
| a|b | matching a or b |
| () | Match the expression in brackets , It also means a group |
Regular expressions are not Python alone possess , It can also be used in other programming languages . however Python Of re The library provides the implementation of the whole regular expression , Using this library , Can be in Python Regular expressions are easily used in . use Python This library is almost always used when writing regular expressions , Now let's take a look at some common methods .
2. match
Here we first introduce the first common matching method ——match, Pass it the string to match and the regular expression , You can check whether the regular expression matches the string .
match Method will try to match the regular expression starting from the beginning of the string , If the match , It returns the result of successful matching ; If it doesn't match , Just go back to None. Examples are as follows :
import re
content = 'Hello 123 4567 World_This is a Regex Demo'
print(len(content))
result = re.match('^Hello\s\d\d\d\s\d{4}\s\w{10}', content)
print(result)
print(result.group())
print(result.span())
The operation results are as follows :
[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-wP5Kq6zi-1657853391825)(https://s2.loli.net/2022/07/14/eu86J57qorvSkDN.png)]
This example first declares a string , It contains English letters 、 Blank character 、 Numbers etc. . Then I wrote a regular body expression :
^Hello\s\d\d\d\s\d{4}\s\w{10}
Use it to match the declared long string . At the beginning ^ Represents the beginning of a matching string , That is to say Hello start ; Ran Shi \s Means match white space characters , Used to match the target string Hello Space after ;\d Means match number ,3 individual \d Use it to match 123; The next 1 individual \s Indicates a matching space ; The target string is followed by 4567, We can still use 4 individual d matching , But it's cumbersome to write so , So it can be used \d Followed by {4} The form of represents matching 4 Subnumeral ; And then 1 Blank characters , Last \w{10} Match 10 Letters and underscores . We noticed that , In fact, the target characters are not matched here , However, this can still be matched , It's just that the matching result is a little shorter .
stay match In the method , The first parameter is the regular expression , The second parameter is the string to be matched .
Print out the output , It turns out that re.Match object , Prove that the match is successful . This object contains two methods :
- group Method can output the matched content , The result is Hello 123 4567 World_This, This is exactly what regular expressions match according to rules ;
- span Method can output a matching range , The result is (0,25), This is the position range of the matched result string in the original string .
Through the example above , We basically know how to Python Use regular expressions to match a paragraph of text .
Match the target
use match Method can realize matching , If you want to extract part of the string , What to do ? Just like the example in the previous section , Extract from a piece of text E-mail Address or telephone number .
Brackets can be used () Enclose the substring you want to extract .() It actually marks the beginning and end of a subexpression . Each marked sub expression corresponds to each group in turn , call group The method passes the index of the group to get the extraction result . Examples are as follows :
import re
content = 'Hello 1234567 World_This is a Regex Demo'
result = re.match('^Hello\s(\d+)\sWorld', content)
print(result)
print(result.group())
print(result.group(1))
print(result.span())
Through this example , We put 1234567 It's extracted , You can see that the regular expression of the number part is enclosed . And then call group(1) Got matching results . The operation results are as follows :

You can see , We succeeded in getting 1234567. It's used here group(1), It is associated with group() Somewhat different , The latter will output the complete matching result , The former will output the first one () Surrounding matching results . If regular expressions are followed by () Enclosed content , Then you can use group(2)、group(3) Etc .
Universal matching
The regular expression we just wrote is actually more complex , As long as there are blank characters, you need to write \s matching , When numbers appear, you need to write \d matching , It's a lot of work . There's no need to do this at all , Because there is a universal match that can be used , Namely .*.
among , Can match any character ( Except for line breaks ), Represents matching the preceding character an infinite number of times , So they can be combined to match any character . With it , We don't have to match character by character .
Next, let's take the example above , We make use of . Rewrite the regular expression :
import re
content = 'Hello 123 4567 World_This is a Regex Demo'
result = re.match('^Hello.*Demo$', content)
print(result)
print(result.group())
print(result.span())
Here we omit the middle part directly , All use .* Instead of , And add an ending string at the end . The operation results are as follows :

You can see ,group Method outputs all matching strings , In other words, the regular expression we wrote matches all the contents of the target string ;span Method output (o,41), This is the length of the entire string . therefore , Use .* It can simplify the writing of regular expressions .
Greed and non greed
Use universal matching .* Sometimes the matched content is not the result we want . See the following example :
import re
content = 'Hello 1234567 World_This is a Regex Demo'
result = re.match('He.*(\d+).*Demo$', content)
print(result)
print(result.group(1))
Here we still want to get the number in the middle of the target string , So the middle of the regular expression is still (\d+). The content on both sides of the number is messy , So I want to omit to write , So they are written .*. Last , form “He.*(\d+).*Demo$, There seems to be no problem . But let's look at the running results :

Something strange happened , Only got 7 This number , What's going on ?
This involves greedy matching and non greedy matching . Under greedy matching ,.* Will match as many characters as possible . In regular expressions * And then \d+, That is, at least one number , And there is no specific number , therefore ,.* Will match as many characters as possible , Here you go 123456 It all matches , Only to \d+ Leave a number that satisfies the condition 7, Therefore, the final content is only numbers 7.
But this will obviously bring us great inconvenience . occasionally , The matching result will be inexplicably less . Actually , Just use non greedy matching here . Non greedy matching is written as .*?, One more than universal matching ?, So what effect can it play ? Let's take another example :
import re
content = 'Hello 1234567 World_This is a Regex Demo'
result = re.match('^He.*?(\d+).*Demo$', content)
print(result)
print(result.group(1))
Here we will just be the first . Changed to ?, Greedy matching turns into non greedy matching . give the result as follows :

At this point, you can successfully obtain 1234567 了 . The reason can be imagined , Greedy matching is to match as many characters as possible , Non greedy matching is to match as few characters as possible . When .*? Match to Hello When the following white space character , The next character is the number , and \d+ It just matches , So here .*? No more matching , It is to hand over to \d+ To match . Last .*? Matching as few characters as possible ,\d+ The result is that 1234567.
So , When making a match , Try to use non greedy matching in the middle of the string , Also is to use .*? Instead of .*, To avoid missing matching results .
But we need to pay attention here , If the matching result is at the end of the string ,.*? It may not match anything , Because it matches as few characters as possible . for example :
import re
content = 'http://weibo.com/comment/kEraCN'
result1 = re.match('http.*?comment/(.*?)', content)
result2 = re.match('http.*?comment/(.*)', content)
print('result1', result1.group(1))
print('result2', result2.group(1))
The operation results are as follows :

Can be observed .*? No match to any result , and .* Try to match as much as possible , Successfully got the matching result .
Modifier
In regular expressions , Some optional flag modifiers can be used to control the matching pattern . The modifier is specified as an optional flag . Let's take a look at :
import re
content = '''Hello 1234567 World_This is a Regex Demo '''
result = re.match('^He.*?(\d+).*?Demo$', content)
print(result.group(1))
Similar to the above example , We added a newline character to the string , Regular expressions are the same , To match the numbers . So let's see what happens :

If an error is found during operation, it will be reported directly , That is, the regular expression does not match the string , The return result is None, And we called group Method , Lead to AttributeError.
that , Why add a newline character , It won't match ? This is because the matching content is any character except the newline character , When encountering a newline ,.*? There's no match , So it leads to matching failure . Just add a modifier here re.S, You can fix this mistake :
result = re.match('^He.*?(\d+).*?Demo$', content,re.S)
The function of this modifier is to match all characters including line breaks . The running results are as follows: :

This re.S It is often used in web page matching . because HTML Nodes often have line breaks , Add it , You can match the newline between nodes .
| Modifier | describe |
|---|---|
| re.I | Make match match case insensitive |
| re.L | Realize localized recognition (locale-aware) matching |
| re.M | Multi-line matching , influence ^ and $ |
| re.S | Make the matching content include all characters including line breaks |
| re.U | according to Unicode Character set parsing characters . This sign will affect \w、\W、\b and \B |
| re.X | This logo can give you a more flexible format , In order to make regular expressions easier to understand |
In web page matching , More commonly used are re.S and re.I.
Escape match
We know that regular expressions define many matching patterns , Such as . Used to match any character except newline . But if the target string contains . This character , So what should we do ?
You need to use escape matching , Examples are as follows :
import re
content = '( Baidu ) www.baidu.com'
result = re.match('\( Baidu \) www\.baidu\.com', content)
print(result)
When a special character used as a regular matching pattern is encountered in the target string , Precede this character with a backslash \ Just escape . for example \. Can be used to match ., The operation results are as follows :

You can see , Here, the original string is successfully matched .
3. search
match The method starts from the beginning of the string , It means that once the beginning doesn't match , The whole match failed . Let's look at the following example :
import re
content = 'Extra stings Hello 1234567 World_This is a Regex Demo Extra stings'
result = re.match('Hello.*?(\d+).*?Demo', content)
print(result)
The string here is in the form of Extra start , Regular expressions start with Hello start , In fact, the whole regular expression is part of the string , But such matching fails . The operation results are as follows :

because match Method needs to consider the content at the beginning of the target string , Therefore, it is not convenient to match . It is more suitable for detecting whether a string conforms to the rules of a regular expression .
Here's another way search, It will scan the whole character when matching , Then return the first successful matching result . in other words , A regular expression can be part of a string . In the match ,search Method will scan the string starting with each character in turn , Until you find the first string that matches the rule , Then return the matching content ; If no string matching the rule is found after scanning , Just go back to None.
Let's put the match Method modified to search, Look at the results :

Then the matching result is obtained . therefore , For the convenience of matching , Use as much as possible search Method . Let's take a few more examples search Method usage .
First , Here's a paragraph to match HTML Text , Next, write several regular expression examples to extract the corresponding information :
html = '''<div id-"songs-list">
<h2 class="title"> Classic old songs </h2>
<p class="introduction"> List of classic songs </p>
<ul id="list" class="list-group">
<li data-view="2"> Simon Birch </li>
<li data-view="7">
<a href="/2.mp3" singer=" Ren Xianqi "> sea — Laugh </a>
</li>
<li data-view="4" class="active">
<a href="/3.mp3" singer=" Chyi Chin "> The past with the wind </a>
</li>
<li data-view="6"><a href="/4.mp3" singer="beyond"> Glorious years </a></li>
<li data-view="5"><a href="/5.mp3" singer=" Chen Huilin "> Notepad </a></li>
<li data-view="5">
<a href="/6.mp3" singer=" Teresa Deng "> May man last </a>
</li>
</ul>
</div>'''
Can be observed ,u1 There are many in the node li node , these li Some nodes contain a node , Some do not include .a Nodes also have some corresponding properties —— Hyperlinks and singer names .
First , We try to extract class by active Of li The hyperlink inside the node contains the singer name and song name , That is to say, we need to extract the third li Under the node a Node singer Properties and text .
At this point, the regular expression can be li start , Then look for a flag active, The middle part can be used .*? To match the next , Because it is necessary to extract singer This property value , So we need to write about people singer=“(.*?)”, Here, the part to be extracted is enclosed in parentheses , In order to use group Method to extract , The parentheses are surrounded by double quotation marks . Then you need to match a The text of the node , The left boundary of this text is >, The right boundary is . Then the target content is still used (.*?) To match , So the final regular expression becomes :
<li.*?active.*?singer="(.*?)">(.*?)</a>
Call again search Method , It will search the whole HTML Text , Find the first content that matches the above regular expression and return .
in addition , Because there are line breaks in the code , therefore search The third parameter of the method needs to be passed re.S. So the whole matching code is as follows :
result = re.search('<li.*?active.*?singer="(.*?)">(.*?)</a>', html, re.S)
if result:
print(result.group(1), result.group(2))
Because the singers and song names that need to be obtained have been enclosed in parentheses , So it can be used group Method to get . The operation results are as follows :

You can see , That's exactly what it is. class by active Of li The hyperlink inside the node contains the singer name and song name .
If the regular expression does not add active( That is, match without class by active The node content of ), What will happen? ? We'll use... In regular expressions active Get rid of , The code is rewritten as follows :
result = re.search('<li.*?singer="(.*?)">(.*?)</a>', html, re.S)
if result:
print(result.group(1), result.group(2))
because search Method will return the first matching target that meets the criteria , So this place changed :

hold active After the label is removed , Search from the beginning of the string , At this point, the qualified node becomes the second li node , The latter will no longer match , So the running result becomes the second li Content in node .
Be careful , In the above two matches ,search The third parameter of the method is added re.S, This makes .*?, Can match newline , So with line breaks li Nodes are matched to . If we take it out , What will be the result ? Get rid of re.S The code for is as follows :
result = re.search('<li.*?singer="(.*?)">(.*?)</a>', html)
if result:
print(result.group(1), result.group(2))
The operation results are as follows :

You can see , It turned out to be the fourth li Content of node . This is because the second and third li Nodes contain line breaks , Get rid of re.S after ,.*? Can't match newline , So regular expressions don't match these two li node , And the fourth one li The node does not contain a newline character , You can match it successfully .
Because most HTML The text contains line breaks , So we need to add re.S Modifier , In order to avoid the problem of mismatch .
4.findall
The introduction is over. search Method usage , It can return the first string that matches the regular expression . If you want to get all the strings that match the regular expression , How to deal with it ? This requires the aid of findall The method .
It's still on top HTML Text , If you want to get all of them a Hyperlinks to nodes 、 Singer and title , Can be search Method instead findall Method . The return result is list type , You need to traverse to get each group of content in turn . The code is as follows :
results = re.findall(
'<li.*?href="(.*?)".*?singer="(.*?)">(.*?)</a>', html, re.S)
print(results)
print(type(results))
for result in results:
print(result)
print(result[0], result[1], result[2])
The operation results are as follows :

You can see , Each element in the returned list is of tuple type , We use the index to take out each entry in turn .
summary , If you only want to get the first string that matches , It can be used search Method ; If you need to extract multiple contents , It can be used findall Method .
5. sub
In addition to using regular expressions to extract information , Sometimes you need to use it to modify the text . for example , Want to remove all numbers from a string of text , If only string replace Method , It's too cumbersome , You can use sub Method . Examples are as follows :
import re
content = '54aK54yr5oiR54ix5L2g'
content = re.sub('\d+', '', content)
print(content)
The operation results are as follows :

Go here sub The first parameter of the method is passed \ d+ To match all the numbers , Pass the string that replaces the number into the second parameter ( If you remove this parameter , Can be assigned to null ), The third parameter is the original string .
Above HTML In the text , If you want to get all li The song name of the node , It may be trivial to extract regular expressions directly . for example , Written in this way :
results = re.findall('<li.*?>\s*?(<a.*?>)?(\w+)(</a>)?\s*?</li>', html, re.S)
print(re)
for result in results:
print(result[1])
The operation results are as follows :

At this time, with the help of sub It's easier . You can use first sub Methods will a The nodes are removed , Leave only the text , And then reuse it findall Just extract :
html = re.sub('<a.*?>|</a>', '', html)
print(html)
results = re.findall('<li.*?>(.*?)</li>', html, re.S)
for result in results:
print(result.strip())
The operation results are as follows :

You can see , after sub Method after treatment ,a There are no nodes , And then through findall The method can be extracted directly . You can find , At an appropriate time with sub Method , Can achieve twice the result with half the effort .
6. compile
The methods mentioned above are all used to process strings , Finally, I'd like to introduce compile Method , This method can compile regular strings into regular expression objects , In order to reuse... In later matching .
The example code is as follows :
import re
content1 = '2022-5-29 12:00'
content2 = '2022-6-03 12:55'
content3 = '2022-6-29 13:21'
pattern = re.compile('\d{2}:\d{2}')
result1 = re.sub(pattern, '', content1)
result3 = re.sub(pattern, '', content2)
result2 = re.sub(pattern, '', content2)
print(result1, result2, result3)
In this example 3 Date , We want to separate these 3 Remove the time from the date , You can use sub Method . The first argument to this method is the regular expression , But there is no need to repeat 3 The same regular expression , At this time, we can use compile Method compiles a regular expression into a regular expression object , For reuse .
The operation results are as follows :

in addition ,compile You can also pass in modifiers , for example re.S Equal modifier , In this way search、findall There is no need for extrafrontal transmission in other methods . therefore , so to speak compile The method is to encapsulate the regular expression , So that we can better reuse .
边栏推荐
- m基于Simulink的高速跳频通信系统抗干扰性能分析
- Quickly master the sort command and tr command
- Review summary of MySQL
- C语言编译器的下载、配置和基本使用
- Évaluation des performances de la machine virtuelle Tianyi Cloud Hangzhou (VPS)
- 快速学会cut命令,uniq命令的使用
- Configure raspberry pie 3b+ build a personal website
- 字典、元組和列錶的使用及區別,
- Regular expression, generator, iterator
- 剑指Offer刷题记录——Offer 05. 替换空格
猜你喜欢

基于simulink的转速反馈单闭环直流调速系统

cookie、session的配置和使用

Xiaodi network security - Notes (4)

What do you need to build a website
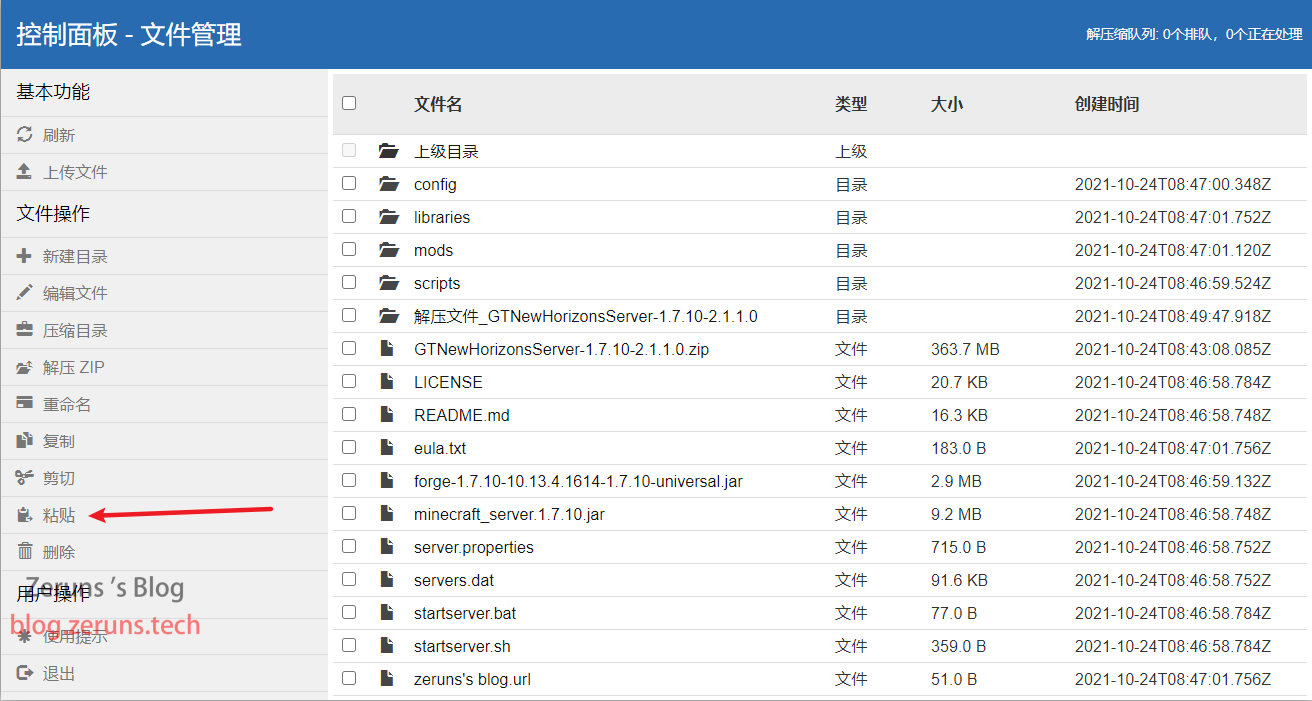
我的世界1.12.2 神奇宝贝(精灵宝可梦) 开服教程

SYN洪水攻击的原理,syn洪水攻击的解决办法

How to set primary key self growth in PostgreSQL database
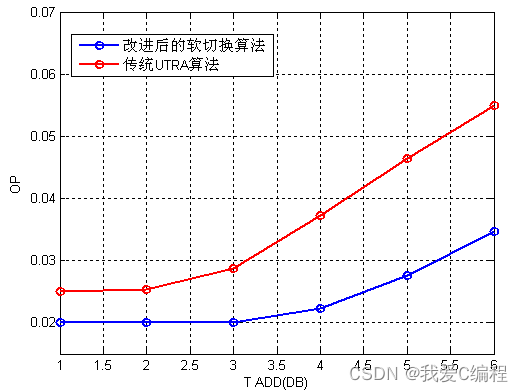
wcdma软切换性能matlab仿真m,对比平均激活集数(MASN)、激活集更新率(ASUR)及呼叫中断概率(OP)三个性能指标
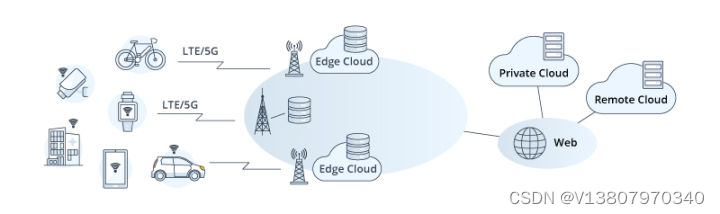
What role does 5g era server play in this?
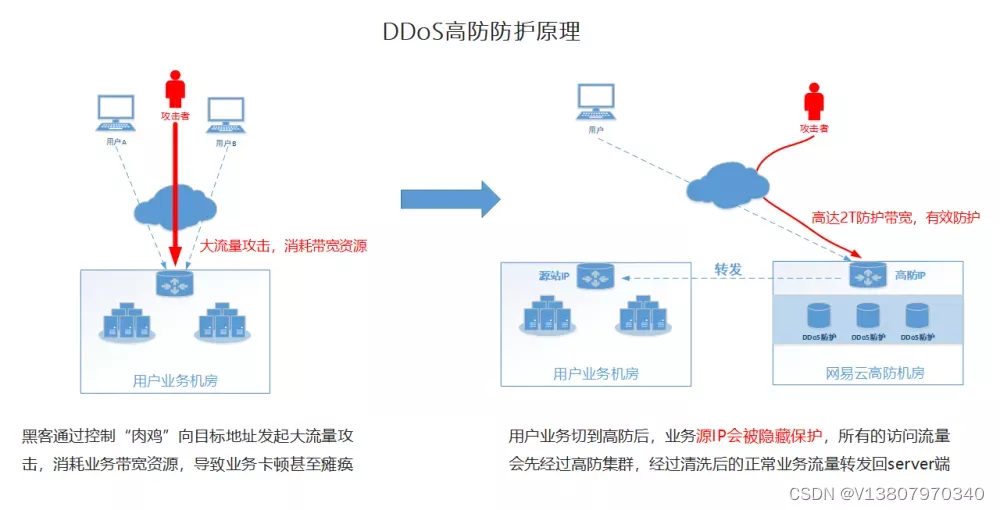
高防服务器是如何确认哪些是恶意IP/流量?ip:103.88.32.XXX
随机推荐
IP103.53.125. XXX IP address segment details
FreeBSD 12 domestic source speed up PKG and ports take a note
ArraysList方法
Xiaodi network security - Notes (5)
Good partner of single chip microcomputer - CS Genesis SD NAND flash
How to set primary key self growth in PostgreSQL database
linxu下调试微信调一跳(Fedora 27)
ARM服务器搭建 我的世界(MC) 1.18.2 版私服教程
企业或个人域名备案怎么弄
How to download free papers from CNKI
Debug wechat one hop under linxu (Fedora 27)
Class is coming. Roll call is needed
Escape from the center of the lake (math problem)
Filter过滤器
我的世界 1.18.1 Forge版 开服教程,可装MOD,带面板
What does IP fragment mean? How to defend against IP fragment attacks?
m基于matlab的协作mimo分布式空时编码技术的仿真
mysql的复习总结
m基于matlab的DQPSK调制解调技术的仿真
How to open the service of legendary mobile games? How much investment is needed? What do you need?