当前位置:网站首页>[MySQL] understand the important architecture of MySQL (I)
[MySQL] understand the important architecture of MySQL (I)
2022-07-26 09:26:00 【new hilbert()】
1.Mysql Architecture

MySQL Server The architecture can be roughly divided from top to bottom Network connection layer 、 Core service layer 、 Storage engine layer and System file layer
Network connection layer :
Mainly responsible for connection processing 、 Authentication 、 Safety and so on , commonly C/S Architecture will have this layer .

- Client connection pool :
Multiple threads will get a database connection to access the database . You can't create a new database connection every time , Use it up and destroy it , It's very inefficient , Therefore, the client needs a database connection pool , Take one connection from the connection pool at a time to process SQL request , Put it back into the connection pool after use , Avoid frequent creation and destruction of database connections .
Common database connection pools are DBCP、C3P0、Druid etc.
- mysql The connector :
When the client requests to connect to the database , The connector will be responsible for establishing a connection with the client 、 Access permissions 、 Maintaining and managing connections .MySQL There will also be a connection pool on the server side , Because there are usually multiple systems and MySQL Make a lot of connections ,MySQL Maintain the database connection with the client through this connection pool .
When the connection is complete , If there is no follow-up action , This connection is idle . If the client does not move for a long time , The connector will automatically disconnect it . This time is determined by the parameter
wait_timeout The control of the , The default value is 8 Hours
Core service layer :
MySQL The core services of are implemented in this layer . It mainly includes permission judgment 、 The query cache 、 Parser 、 Query optimizer 、 Caching and execution plans .
- Permission judgment can audit whether a user has access to a library 、 A table , Or the permission of a row of data in the table .
- Cache through Query Cache To operate , If the data is in Query Cache in , Return the result to the client directly , There is no need to query and parse 、 Optimization and implementation process .
- Parser for SQL Statement parsing , Judge whether the grammar is correct .
- Optimizer on SQL Rewrite and optimize accordingly , And generate the optimal execution plan , You can call the program's API Interface , Access data through the storage engine layer .

Storage engine layer :
MySQL One of the most important features of database is its plug-in table storage engine , Storage engine is the realization of the underlying physical structure , Responsible for data storage and extraction . Each storage engine has its own characteristics , Different storage engine tables can be established according to specific applications .
Common storage engines are InnoDB、MyISAM、Memory etc. , The most common storage engine is InnoDB, It is from MySQL 5.5.8 Version began to become the default storage engine .
System file layer :
The system file storage layer is mainly responsible for storing the database data and logs in the system files , Simultaneous interaction with the storage engine , It's the physical storage layer of the file .
Some of the main documents are : Data files 、 Log files 、 Configuration files, etc
have access to SHOW VARIABLES LIKE ‘%datadir%’; Command to view the directory of the data file , In the data file directory, we can see the following files .


see mysql Log information , Use show variables like ‘log_%’ command 
- Data storage files
MySQL The database will be data Create a folder named database under the directory , Used to store table file data in the database . Different Database engine , Each table has a different extension
- .frm:8.0 Before, no matter what kind of storage engine , After the table is created, a named ’.frm’ file .frm Files mainly store data information related to tables , It mainly includes the definition information of table structure . When the database crashes , The user can go through frm File to restore the data table structure .
- InnoDB Data files :
.ibd: Use exclusive tablespaces to store table data and index information , One table corresponds to one ibd file
.ibdata: Use shared table space to store table data and index information , All tables use one or more ibdata file
Shared tablespace : All table data of a database , Index files are all in one file .
Exclusive tablespace : Each table will be generated and stored as a separate file , Each table has one .frm Table description file , also One .ibd file . This file includes Data from a single table Content and index content .
show variables like "innodb_file_per_table";
ON Represents stand-alone table space management ,OFF Represents shared table space management
Shared tablespace :
advantage :
1. Table space can be divided into multiple files and stored on each disk . Data and files together for easy management .
shortcoming :
1. All the data and indexes are stored in one file , Multiple tables and indexes are mixed in the table space , In this way, after a large number of delete operations for a table, there will be a large number of gaps in the table space .
Independent table space :
advantage :
1. Each table has its own independent table space .
2. The data and index of each table will exist in its own table space .
3. Single table can be moved in different databases .
4. Space is recyclable (Drop table Operate auto recycle table space )
shortcoming :
1. The single watch is too large , Exceed 100 G
- MyISAM Data files :
.MYD: It is mainly used to store table data information
.MYI: It is mainly used to store the data tree of the task index in the table data file
MySQL8.0 Is no longer available separately b.frm, But merge in b.ibd In file
To the storage ibd File directory , Execute the following command :
shell ibd2sdi --dump-file= Resolved file name .txt Table name to be resolved .ibd


- Log files
Common logs include : Error log 、 Binary log 、 Query log 、 Slow query log and so on
- Error log
Error log (Error Log) yes MySQL One of the most commonly used logs in , Main records MySQL Messages during server startup and shutdown Rest 、 Faults and abnormalities occurred during the operation of the server
# Check the error log location
show variables like "log_error";
# stay MySQL in , have access to mysqladmin Command to open a new error log , In order to make sure MySQL Hard disk space on the server .
# mysqladmin The syntax of the command is as follows :
mysqladmin -uroot -p flush-logs
# After executing the command ,MySQL The server will automatically create a new error log first , Then rename the old error log to filename.err-old . You can delete it manually .
# Configuration in profile
[mysqld]
log-error=dir/{
filename}
- Binary log (binlog)
Binary log binlog Used to record write operations performed by the database ( Exclude queries ) Information , Stored on disk in binary form . Using any storage engine mysql The database records binlog journal . stay binlog The logical log is recorded in , That is to say SQL sentence .SQL After statement execution ,binlog Append to log file . You can set binlog file size , After exceeding the size , Automatically create new files .
binlog There are three formats , Respectively STATMENT、ROW and MIXED
- STATMENT: You can change the data sql Statement recorded to binlog in ; yes MySQL 5.7.7 The previous default format ;
- ROW: Don't record every sql The context information of the statement , Only record which data has been modified ; yes MySQL 5.7.7 Default format after ;
- MIXED: be based on STATMENT and ROW Mixed replication of the two modes , In general use STATEMENT Pattern , For operations that cannot be copied, use ROW Pattern ;
show variables like 'log_bin%'
mysql-index.0000XX : Hold on MySQL The logic of change
mysql-index.index : Is the location index , Subsequent backup and recovery use

show binlog events in 'mysql-bin.000049'; # View specified binlog The content of the document

- Query log
The query log is in mysql Is called general log( General log ), Don't be " Query log " My name misleads , Query logs are not just records select sentence , The query log records the commands executed by the database , Whether these statements are correct or not , Will be recorded .
show VARIABLES LIKE 'general_log';
Store the query log in mysql.general_log In the table
general_log: Indicates whether the query log is enabled ,ON Open for indication ,OFF Indicates not on , The default is OFF
- Slow log
The so-called slow query is to record the data that exceeds a certain time through settings SQL sentence
Turn on MySQL Slow query log function
# Check to see if it's on Unused index SQL Log query
show variables like 'log_queries_not_using_indexes';
# Turn on Unused index SQL Log query
set global log_queries_not_using_indexs=on/off;
# Check how long queries are logged in the slow query log
show variables like 'long_query_time';
# Set the recording duration ,0 For all records , Restart after setting
set global long_query_time=10
# Check to see if it's on mysql Slow query log function
show variables like 'slow_qurey_log'
# Turn on 、 Close the slow log
set global slow_qurey_log=on/off;
# View log location
show variables like 'slow_query_log_file';
# How to store logs
show variables like "log_output";
- The configuration file
To hold MySQL All configuration information files , such as :my.cnf、my.ini
### Find profile
/usr/local/mysql/bin/mysqld --verbose --help |grep -A 1 'Default options'
### Finding results
Default options are read from the following files in the given order:
/etc/my.cnf /etc/mysql/my.cnf /usr/local/mysql/etc/my.cnf ~/.my.cnf
2.Innodb Architecture diagram


Innodb Memory layout
(1) Buffer Pool
Buffer Pool yes MYSQL An important memory component in the database , A buffer between the external system and the storage engine , For the addition, deletion, modification and query of the database, these operations are performed for the cached data in the memory data structure , Before manipulating data , Will load data from disk to Buffer Pool in , After the operation is completed, the disk is brushed asynchronously 、 Write undo log、binlog、redolog Wait for some column operations , Avoid disk access every time IO Affect performance .
MySQL When the server starts, it will request a piece of continuous memory from the operating system , namely Buffer Pool. Under default configuration Buffer Pool Only 128MB size , We can adjust innodb_buffer_pool_size Parameter to set Buffer Pool Size
To manage Buffer Pool Cache pages in ,InnoDB Some description information is created for each cache page ( Metadata ), Used to describe this cache page . The description information mainly includes the table space number to which the page belongs 、 Page number 、 The address of the cache page 、 List node information 、 Lock information 、LSN Information, etc. .
The description information itself is also a piece of data , They all use the same amount of memory . stay Buffer Pool in , The description of each cache page is placed at the top , Each cache page is behind . It looks like the picture below .
Each description data is approximately equivalent to the size of the cache page 5%, That is to say 800 About bytes . And we set up innodb_buffer_pool_size Does not contain the size of the descriptive data , actually Buffer Pool The size of will exceed this value . For example, the default configuration 128MB, that InnoDB For Buffer Pool When requesting continuous memory space , Will apply for almost 128 + 128*5% ≈ 134MB Size space

InnoDB It's not a one-time application pool_size Size of memory space , But rather chunk Apply for . One chunk The default is 128M, Represents a continuous space , After applying for this memory space , It will be divided into several cache pages and their corresponding description information blocks .
That is to say a Buffer Pool The example is actually composed of several chunk Composed of , Every chunk It is divided into description information block and cache page , Then share a set Free Linked list 、LRU Linked list 、Flush Linked list .
It should be noted that , The memory space occupied by the basic node of the linked list is not included in Buffer Pool within , It's a separate piece of memory space , Each base node only occupies 40 Byte size
a key : The descriptive information is flush_pre ,flush_next ,free_pre, free_next The pointer 
- Free Linked list
InnoDB Designed a free Linked list , It is a two-way linked list data structure , Each node of the linked list is the description information of an idle cache page .
There are... In each description free_pre、free_next Two pointers ,Free Linked list It is a two-way linked list formed by the connection of these two pointers . then Free Linked list There is a base node , This basic node stores the address of the head node of the linked list 、 Tail node address , And the number of nodes in the current linked list .
effect : With this Free Linked list after , When you need to load a page from disk to Buffer Pool when , From Free Linked list Take out a description data block , Then write the page into the free cache page corresponding to the description data block . And write some description data into the description data block , For example, the table space number of the page 、 Page number and so on . Last , Transfer the description data block corresponding to the cache page from Free Linked list Remove , Indicates that the cached page has been used .

- LRU Linked list
Because the buffer pool size is limited , It is impossible to load data into the buffer pool all the time , For some frequently accessed data, you can always stay in the buffer pool , And some rarely accessed data , When the cache page is running out , You can eliminate some . It can be used at this time LRU Linked list To manage used cache pages , This way you can know which pages are most commonly used , Which pages use the least .( Recently used on the head , Not much use, to the tail )
Existing problems :
1、InnoDB There is a pre reading mechanism , When loading a data page from the disk , It may be associated with loading other data pages adjacent to this data page into the cache . Although I pre read other pages , But it may not work , But if these pages go to LRU Head placement , It will cause the pages that are often visited to move back , Then it was eliminated . This situation belongs to loading into Buffer Pool Pages in are not necessarily used, resulting in a reduction in cache hit rate .
2、 If we write a query with a full table scan , The page of the whole table is loaded into LRU The head of , If the table records a lot , Probably LRU The pages in the linked list that were often visited before are eliminated at once , The remaining data may not be accessed often . This is to load a large number of low-frequency pages to Buffer Pool, Then eliminate the frequently used pages , As a result, the cache hit rate is reduced .
In order to solve the simple problem LRU The problem with the list ,InnoDB In the design LRU When you link lists , In fact, it adopts the idea of separating cold and hot data ,LRU The linked list will be split into two parts , Part of it is thermal data ( also called new list ), Part of it is cold data ( also called old list )

1.LRU The linked list is divided into cold 、 Thermal data area , front 63% Is the thermal data area , after 37% Is the cold data area , Load the cache page and put it in the head of the cold data area first .
2. The first access of the cache page of the cold data area exceeds 1 Seconds later , It will not be moved to the head of the hot data area until it is accessed again .
3. In the thermal data area , Only after 3/4 The cached page will be moved to the head only when it is accessed , front 1/4 Being accessed will not move .
4. Eliminate data, preferentially eliminate the cache page at the end of the cold data area .
- Flush Linked list
Locate which data pages are dirty pages , Need to brush dirty page data back to disk .Flush Linked list Like the previous two linked lists , There is also a base node , If a cache page is modified , Will join Flush In the list .
There are also two pointers in the description information block flush_pre、flush_next Used to connect to form flush Linked list , therefore Flush Linked list The cache page in must be in LRU In the list , and LRU Not in the linked list Flush Linked list The cached page in is the unmodified page

(2) change buffer

When you need to update a data page , If the data page is in memory, update it directly , And if the data page is not in memory , Without affecting data consistency ,InooDB These updates will be cached in change buffer in , So you don't need to read this data page from disk .
The next time the query needs to access this data page , Read data pages into memory , And then execute change buffer Operations related to this page in . In this way, we can guarantee the correctness of the data logic
take change buffer The operations in apply to the original data page , The process of getting the latest results is called merge. In addition to accessing this data page will trigger merge Outside , There are background threads in the system that regularly merge. Shut down the database normally (shutdown) In the process of , Will perform merge operation .
Under what conditions can you use Change buffer?
For a unique index , All update operations must first determine whether the operation violates the uniqueness constraint . such as , To insert id =5 This record , It is necessary to judge whether there is already id=5 The record of , But this must read the data page into the memory to judge . Then I read the memory , There is no need to use change buffer,change buffer The purpose is to reduce disk IO frequency
therefore , Only index updates are not available change buffer, In fact, only ordinary indexes can be used .
redo log The savings are random disk writes IO Consume ( Although it is also a disk , But write logs in sequence )
change buffer To save random disk reading IO Consume . Without it , First read data from disk into memory , Then change in memory , He saved a step
So what scenario will trigger ChangeBuffer Of Merge Operation? ?
- Access the data page corresponding to the change operation ;
- InnoDB Backstage regularly Merge;
- database BufferPool The space is insufficient ;
- When the database shuts down normally ;
- RedoLog When it's full ;
problem :change buffer Recorded a delete operation , for example delete from table where x = a , But at this time insert What about a statement with a primary key ?( This primary key happens to be when the condition is equal to x=a Within the scope of )
When inserting the primary key , In less than change buffer , The disk page needs to be loaded buffer pool , This is the time change buffer The data of will modify the corresponding page , Record this range is_delete Set to 1, It can be inserted successfully , Primary key conflicts will not be reported .
(3) Adaptive Hash Index The adaptive hash Indexes
InnoDB The storage engine monitors queries to the index pages on the table . And establish an appropriate hash index , Accelerate access to data pages
characteristic
- Hash index , Query consumption O(1)
- Reduce frequent resource access to the secondary index tree .
- The adaptive
shortcoming
- hash Adaptive indexing takes innodb buffer pool;
- The adaptive hash Index is only suitable for searching equivalent queries , Such as select * from table where index_col=‘xxx’, For other types of lookup , For example, range finding , It can't be used ;

Innodb The storage engine monitors the lookup of secondary indexes on the table , If a secondary index is frequently accessed ,innodb It will use the prefix of the index key to build a hash index . Convert the index value into a pointer , Easy direct access , Bring about an increase in speed .
Frequently accessed secondary index data is automatically generated to hash Go inside the index ( Data that has been accessed three times in a row recently )
(4) log buffer
InnoDB redo log It's the storage engine WAL journal , For databases crash recovery, Ensure the reliability and safety of database data in case of system failure . User transactions are writing redo log Is not written directly redo log file, It's about writing first redo log buffer, Then by the backstage log_writer Threads and log_flush The thread is responsible for writing file, To improve the write performance of the database .
Innodb Disk layout
InnoDB Logical storage structure :
Table spaces can be thought of as InnoDB The highest level of the logical structure of the storage engine , All the data is stored in the table space .
- paragraph (segment)
paragraph (Segment) Divided into index segments , Data segment , Rollback segments, etc . among The index segment is the non leaf node part , and The data segment is the leaf node part , The rollback segment is used for data rollback and multi version control . A paragraph contains 256 Districts (256M size ) - District (extent)
A section is a collection of pages , An area contains 64 Consecutive pages , The default size is 1MB (64*16K) - page (page)
InnoDB Dividing data into pages , Page as the basic unit of interaction between disk and memory , That is, read at least one page from the disk at a time 16KB In memory , Put at least... In memory at a time 16KB Refresh content to disk

File Header: Used to record some header information of the page , from 8 Component composition , Fixed occupancy 38 byte
Key attributes :FIL_PAGE_LSN This value represents the last modified log sequence position of the page LSN(Log Sequence Number)
Page Header: This part is used to record the status information of the data page , from 14 Component composition , Co occupation 56 byte , As shown in the following table 
Infimum and Supremum Record:
InnoDB There are two virtual row records in each data page , Used to define the boundaries of records .Infimum A record is a record smaller than any primary key value in the page ,Supremum Record It is a record larger than any primary key value in the page change . These two records are created when the page is created , And will not be deleted under any circumstances .
User Record and Free Space
User Records Is the part that actually stores row records ,Free Space It's obviously free space
Free Space Free space is obviously free space , It is also a linked list data structure . After a record is deleted , Set up delete_mask by 1, Then the space will be added to the free linked list , This part of the space can be used .
Page Directory
Page Directory( Page directory ) The relative position in which records are stored , The records in the page are divided into groups , The slot stores the relative position of the largest record in each group ( Record the relative position in the page , It's not an offset ), stay InnoDB Not every record in the has a slot , InnoDB The slot of the storage engine is a sparse directory (sparse directory), That is, a slot may contain multiple records .
Suppose there is (1,2,3,4,5,6,7,8,9,10) At the same time, suppose that a slot contains 4 Bar record , be Slots The record in may be (1,5,8)

File Trailer
When a page is written to disk , The first thing to write is File Header Medium FIL_PAGE_SPACE_OR_CHKSUM value , Is the checksum of the page . In the process of writing , The database may be down , As a result, the page is not completely written to disk .
In order to verify whether the page is completely written to disk ,InnoDB Just set up File Trailer part .File Trailer Only one of them FIL_PAGE_END_LSN, Occupy 8 byte .FIL_PAGE_END_LSN It's divided into two parts , front 4 Bytes represent the checksum of the page ; after 4 Bytes represent the corresponding log sequence position when the page is last modified (LSN), And File Header Medium FIL_PAGE_LSN identical .
- InnoDB rows
at present ,InnoDB Support 4 BOC record format , Namely Compact、Redundant、Dynamic and Compressed Line format .
COMPACT Line record format 
- Variable length field length list
- MySQL There are some variable length field types in , Such as VARCHAR(M)、TEXT、BLOB etc. , The length of the variable length field is not fixed , Therefore, when storing data, the number of bytes occupied by these data should also be saved , When reading data, you can read the data of the corresponding length according to this length list .
- Variable length field length list Is the byte length used to record the real data of all variable length fields in a row , And the number of bytes occupied by each variable length field data is Store in reverse order of columns .
- The variable length field only stores values that are not in the length list NULL The length occupied by the column contents of , The value is NULL The length of the column is not stored
- NULL List of values
Some columns in the table may store NULL value , If you put these NULL It is a waste of space to put all values into the recorded real data , therefore Compact The line format takes these values as NULL The columns of are stored in NULL Value list .
The value of the binary bit is 1 when , The value representing the column is NULL.
The value of the binary bit is 0 when , The value representing the column is not NULL.
- Record header information
The header information is fixed 5 Byte composition ,5 One byte is 40 Binary bits
- Record real data
Each row of data is in addition to the user-defined columns , There are two hidden columns at the beginning , Business ID Column (DB_TRX_ID) And rollback pointer column (DB_ROLL_PTR), Respectively 6 Byte and 7 The size of bytes . if InnoDB Table has no primary key defined , One more per line 6 Byte line ID Column (DB_ROW_ID)
If we don't explicitly define a primary key for a table , And there is no unique index defined in the table , that InnoDB Will automatically add a... To the table row_id As the primary key .
B+ The tree structure is as follows :

(1) SYSTEM tablespace ( Shared tablespace )
By default InnoDB The storage engine has a shared table space ibdata1( SYSTEM tablespace System TableSpaces) System tablespaces can have one or more data files . By default , ibdata1 Create a file named... In the data directory System table space data file . The size and number of system tablespace data files are determined by innodb_data_file_path Start option definition .
InnoDB The system tablespace contains InnoDB The data dictionary (InnoDB Metadata of related objects ), yes doublewrite buffer ,change buffer Change buffer and undo logs Storage area of rollback log
The system tablespace also contains any tables and index data created by users in the system tablespace .
System tablespaces are considered shared tablespaces , Because it is shared by multiple tables .

Exclusive Mode : adopt innodb_file_per_table=ON To open , Use ibd File to store data , And one for each table ibd file .
In exclusive tablespace mode , Table data page It doesn't belong to the system table space
Sharing mode : The default is shared mode . Use ibdata file , All tables use one ( Or more 、 Self configuring )ibdata file .
In shared mode , The data table page It also belongs to the system table space
- The data dictionary
InnoDB The data dictionary consists of internal system tables . These system tables contain objects for tracking ( As shown in the table , Indexes and columns ) Metadata
Yes 4 A basic system table to store the metadata of the table : surface 、 Column 、 Indexes 、 Index column and other information . this 4 Two tables are SYS_TABLES、SYS_COLUMNS、SYS_INDEXES、SYS_FIELDS

- double write
(1) Dirty page swipe disk risk About IO Minimum unit of :
1、 database IO The smallest unit of is 16K(MySQL Default ,oracle yes 8K)
2、 file system IO The smallest unit of is 4K( Also have 1K Of )
3、 disk IO The smallest unit of is 512 byte
therefore , There is IO Writing causes page Risk of damage :
(2) Write twice : ( Improve innodb The reliability of the , Used to solve some write failures (partial page write Page break ))
Why can't you use redo log recovery ?
Because the page falling on the disk has been damaged ,redo log It records physical changes to the page , If the page itself is corrupted ,redo log There's nothing you can do
double write Workflow
doublewrite It's made up of two parts , Some are in memory doublewrite buffer, Its size is 2MB, The other part is the shared table space on disk (ibdata x) Continuous 128 A page , namely 2 Districts (extent), So is the size 2M.
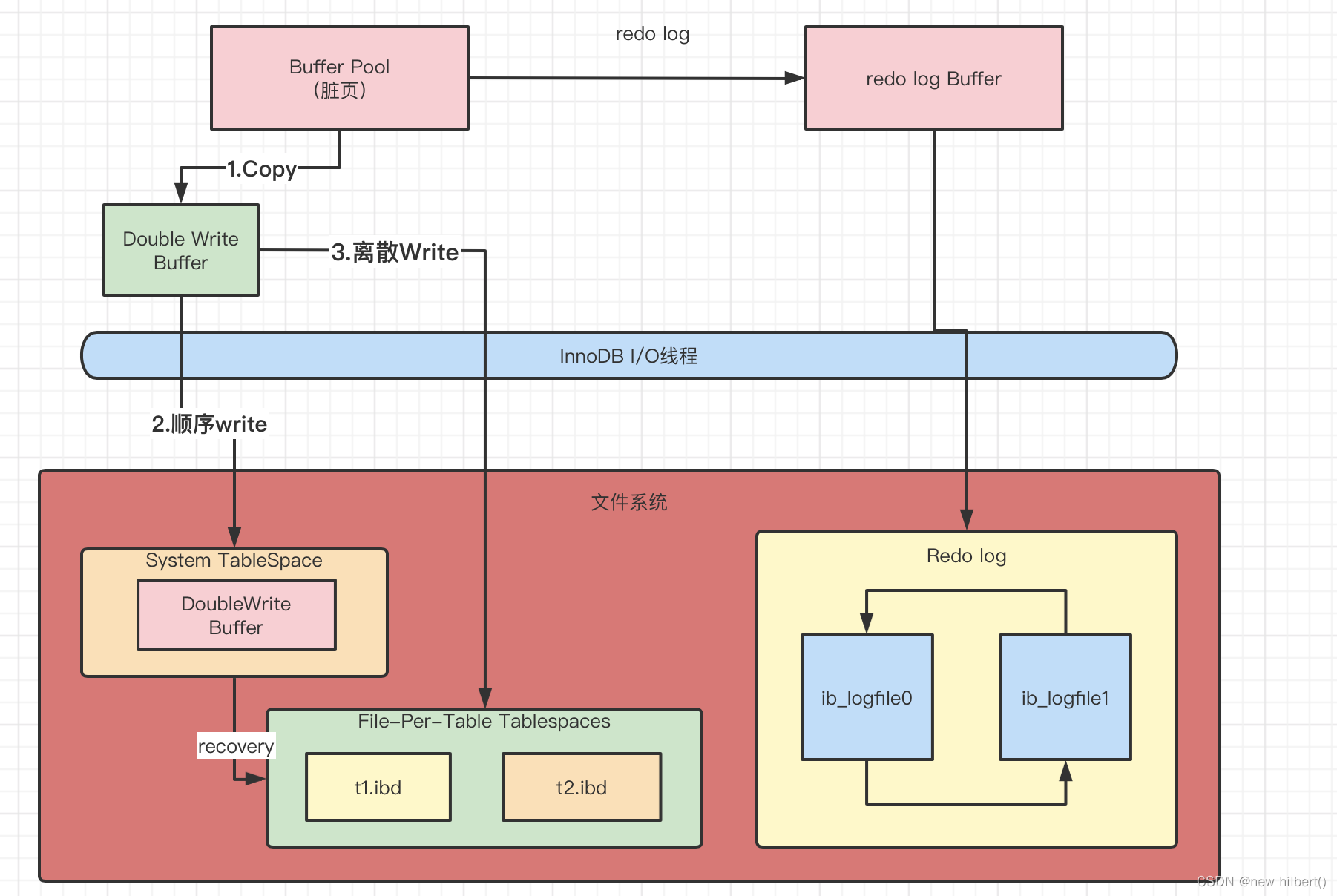
1、 When a series of mechanisms trigger the refresh of dirty pages in the data buffer pool , It is not written directly to the disk data file , It's copied to memory first doublewrite buffer in ;
2、 Then write twice to the disk shared table space from the two write buffers ( Continuous storage , Sequential writing , A high performance ), Every time 1MB;
3、 When the second step is completed , then doublewrite buffer The dirty page data in is written to the actual table space files ( Discrete writing );( After the dirty page data is solidified , That is, mark the corresponding doublewrite Data can cover )
(3)doublewrite Crash recovery :
If the operating system crashes while writing pages to disk , In the process of recovery ,innodb The storage engine can use the doublewrite Found a recent copy of the page , Copy it to a tablespace file , Then apply redo log, It completes the recovery process .
- change buffer
On disk , Changing the buffer is system tablespace Part of the system tablespace , So when the database restarts , Index changes remain in the cache . In order to ensure change buffer Persistence . - undo log Rollback log
Rollback log undo log Is associated with a transaction undo log A collection of records . When we make a change to the record, it will produce undo Record ,Undo Records are recorded to the system table space by default (ibdata) in , But from 5.6 Start , You can also use independent Undo Table space .
Undo The old version data is stored in the record , When an old transaction needs to read data , In order to read the old version of the data , Need to follow undo The chain finds records that satisfy its visibility .

InnoDB Support 128 A rollback segment , Each segment supports up to 1023 Concurrent data modification transactions , The total limit is about 128K Concurrent data modification transactions ( Read only transactions are not included in the maximum limit ). Each transaction is assigned to one of the rollback segments , And remain associated with the rollback segment within the duration . innodb_rollback_segments Options define InnoDB Number of rollback segments used
(2) undo tablespaces ( Independent rollback tablespaces )
from 5.6 Start , You can use independent Undo Table space , You can configure the undo log Stored in a separate undo tablespaces Inside . Configure individual undo tablespaces when , Rollback segments in the system tablespace will be invalidated .undo tablespaces Consists of one or more rollback log files .
innodb_undo_tablespaces
Define the use of undo tablespaces Number , This option must be initialized MySQL Before configuration .
This value also corresponds to undo log Number of files , Every undo log The file represents a separate rollback table space .
innodb_undo_directory
undo tablespaces Storage directory of documents
innodb_rollback_segments
Define the total number of rollback segments .innodb_rollback_segments The default setting for is 128, This is also the maximum
(3)file-per-table Table space ( Independent data table space )
Independent table space :
advantage :
1. Each table has its own independent table space .
2. The data and index of each table will exist in its own table space .
3. Single table can be moved in different databases .
4. Space is recyclable (Drop table Operate auto recycle table space )
File-per-table Tablespaces and shared tablespaces ( Such as SYSTEM tablespace or universal tablespace ) Compared with the following advantages
- In truncation or deletion file-per-table After the table created in the tablespace , Disk space will be returned to the operating system . Truncating or deleting a table stored in a shared tablespace will be created in the shared tablespace data file and can only be used for nnoDB Free space for data . let me put it another way , The shared tablespace data file will not shrink after the table is truncated or deleted .
- ALTER TABLE Performing a table copy operation on a table located in a shared table space will increase the amount of disk space occupied by the table space . Such operations may require as much extra space as the data in the table plus the index . The space will not be like file-per-table Free it back to the operating system like a table space .
- TRUNCATE TABLE Resident in file-per-table Better performance when executing on tables in a tablespace .
(4)General Tablespaces( General tablespace )
Similar to system tablespaces , A common table space is a shared table space that can store data for multiple tables
A common table space uses CREATE TABLESPACE Syntax creates
## Create tablespace
CREATE TABLESPACE tablespace_name
ADD DATAFILE 'file_name'
[FILE_BLOCK_SIZE = value]
[ENGINE [=] engine_name]
## Add tables to a common tablespace
CREATE TABLE tbl_name ... TABLESPACE [=] tablespace_nameALTER TABLE tbl_name TABLESPACE [=] tablespace_name
(5)Temporary Tablespaces( Temporary table space )
Uncompressed 、 The temporary tables created by the user and the temporary tables inside the disk are created in the shared temporary table space
Temporary tablespaces are deleted during normal shutdown or abort initialization , And recreate each time the server starts . Temporary tablespaces receive a dynamically generated space when they are created ID.
If you cannot create a temporary tablespace , Then refuse to start . If the server stops unexpectedly , The temporary tablespace is not deleted . under these circumstances , The database administrator can manually delete the temporary tablespace or restart the server , The server will automatically delete and recreate the temporary tablespace
## To configure innodb_temp_data_file_path Variable to specify the maximum file size
innodb_temp_data_file_path=ibtmp1:12M:autoextend:max:500M
Reference article :
边栏推荐
猜你喜欢

Server memory failure prediction can actually do this!
Selection and practice of distributed tracking system

Li Mu D2L (VI) -- model selection

The child and binary tree- open root inversion of polynomials

微信小程序学习笔记1

STM32+MFRC522完成IC卡号读取、密码修改、数据读写

【Mysql】Mysql锁详解(三)

Cat installation and use

el-table实现增加/删除行,某参数跟着变

【线上问题】Timeout waiting for connection from pool 问题排查
随机推荐
VS2019配置opencv
Basic use of Arc GIS 2
Object 的Wait Notify NotifyAll 源码解析
【Mysql】认识Mysql重要架构(一)
Under a directory of ext3 file system, subfolders cannot be created, but files can be created
异常处理机制二
Use of off heap memory
面试题目大赏
搜索模块用例编写
大二上第三周学习笔记
2020-12-29
Cat installation and use
QT | about how to use EventFilter
神经网络与深度学习-6- 支持向量机1 -PyTorch
附加到进程之后,断点显示“当前不会命中断点 还没有为该文档加载任何符号”
wap端微信h5支付,用于非微信浏览器
TabbarController的封装
Stm32+mfrc522 completes IC card number reading, password modification, data reading and writing
【Mysql】Mysql锁详解(三)
I'm faded