当前位置:网站首页>Li Mu D2L (V) -- multilayer perceptron
Li Mu D2L (V) -- multilayer perceptron
2022-07-26 09:09:00 【madkeyboard】
List of articles
One 、 perceptron
Concept
A given input x, The weight w, And offset b, The output of the sensor is as follows . The output of perceptron is a binary problem , The output of linear regression is a real number ,Softmax If there is n A class will output n Elements , It is a multi classification problem .
The perceptron cannot fit XOR problem , Because it can only produce linear split surfaces

Training perceptron
Its solution algorithm is equivalent to using a batch size of 1 The gradient of .

Convergence theorem

Two 、 Multilayer perceptron
Why is it called multilayer ? When the goal we want to achieve cannot be achieved at one time , Just learn a simple function first , Learn another simple function , Finally, another function is used to combine the two functions .
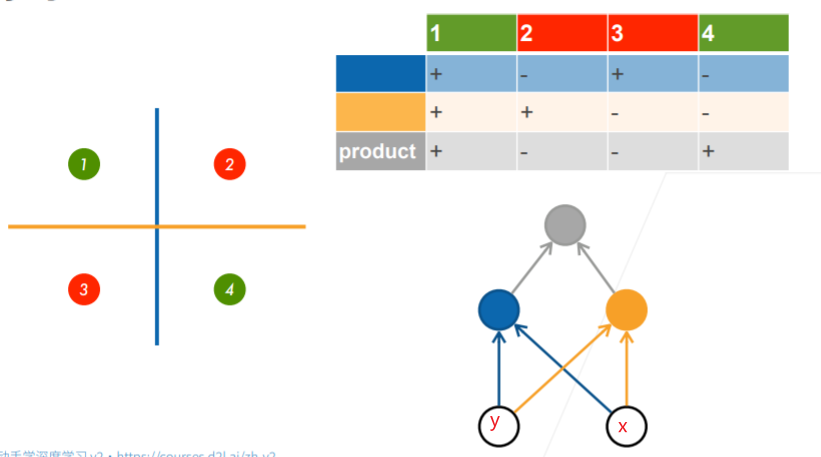
Single hidden layer - Single category
Input is n Dimension vector , The hidden layer is m x n Matrix , Offset is long bit m Vector . The output layer is also a long bit m Vector , The offset is a scalar .

Why do we need a nonlinear activation function ? Suppose the activation function is itself , namely σ(x) = x, You can see the output o Of w2T W1 x + b’ It is still a linear function , Then it is equivalent to a single-layer perceptron .

Sigmoid Activation function

Tanh Activation function

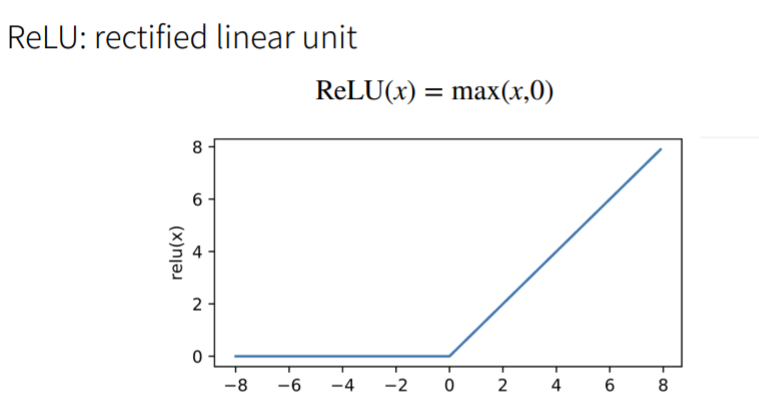
ReLU Activation function
Multilevel classification
Input and hidden layers are the same as single classification , The difference is that the output layer is a m x k Matrix , The offset is a length of k Vector .

3、 ... and 、 Multi layer perceptron code starts from scratch
import torch
from torch import nn
from d2l import torch as d2l
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
# 1 Implement a multi-layer perceptron with a single hidden layer , contain 256 Hidden units
num_inputs, num_outputs = 784, 10
num_hiddens = 256
w1 = nn.Parameter(torch.randn(num_inputs, num_hiddens, requires_grad=True) * 0.01) # randn It is normally distributed in (0,1) The reason why I multiply by 0.01 Is to limit the scope to (0,0.01)
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
w2 = nn.Parameter(torch.randn(num_hiddens, num_outputs, requires_grad=True) * 0.01)
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
params = [w1, b1, w2, b2]
# 2 Realization RELU Activation function
def relu(X):
a = torch.zeros_like(X)
return torch.max(X, a)
# 3 Implementation model
def net(X):
X = X.reshape((-1, num_inputs))
H = relu(X @ w1 + b1) # @ Abbreviation for matrix multiplication
return (H @ w2 + b2)
# 4 Loss
loss = nn.CrossEntropyLoss(reduction='none')
# 5 Training process
num_epochs, lr = 10, 0.1
updater = torch.optim.SGD(params, lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, updater)
d2l.plt.show()
From the results, we can see that it is the same as last time sofmax comparison , its loss To reduce the , But the accuracy has not improved .

Four 、 Simple implementation
import torch
from torch import nn
from d2l import torch as d2l
net = nn.Sequential(nn.Flatten(), nn.Linear(784, 256), nn.ReLU(),
nn.Linear(256, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights);
batch_size, lr, num_epochs = 256, 0.1, 10
loss = nn.CrossEntropyLoss()
trainer = torch.optim.SGD(net.parameters(), lr=lr)
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
边栏推荐
- Canal 的学习笔记
- Zipkin安装和使用
- Pop up window in Win 11 opens with a new tab ---firefox
- Elastic APM安装和使用
- 围棋智能机器人阿法狗,阿尔法狗机器人围棋
- Qtcreator reports an error: you need to set an executable in the custom run configuration
- 原根与NTT 五千字详解
- ext4文件系统打开了DIR_NLINK特性后,link_count超过65000的后使用link_count=1来表示数量不可知
- 756. 蛇形矩阵
- Espressif plays with the compilation environment
猜你喜欢

Innovus卡住,提示X Error:
![[leetcode database 1050] actors and directors who have cooperated at least three times (simple question)](/img/ab/bad6b86039384af7b829bef5316923.png)
[leetcode database 1050] actors and directors who have cooperated at least three times (simple question)

深度学习常用激活函数总结

03 exception handling, state keeping, request hook -- 04 large project structure and blueprint

Clean the label folder

数据库操作技能7
Database operation skills 6

What is the difference between NFT and digital collections?

Sklearn machine learning foundation (linear regression, under fitting, over fitting, ridge regression, model loading and saving)

TCP solves the problem of short write
随机推荐
03 exception handling, state keeping, request hook -- 04 large project structure and blueprint
839. 模拟堆
Polynomial open root
codeforces dp合集
Clean the label folder
李沐d2l(四)---Softmax回归
day06 作业--技能题2
优秀的 Verilog/FPGA开源项目介绍(三十零)- 暴力破解MD5
Simple message mechanism of unity
【ARKit、RealityKit】把图片转为3D模型
Announcement | FISCO bcos v3.0-rc4 is released, and the new Max version can support massive transactions on the chain
tornado之多进程服务
[leetcode database 1050] actors and directors who have cooperated at least three times (simple question)
机器学习中的概率模型
MySQL 强化知识点
Error: Cannot find module ‘umi‘ 问题处理
2022年上海市安全员C证考试试题及模拟考试
NTT (fast number theory transformation) polynomial inverse 1500 word analysis
JVM触发minor gc的条件
数据库操作技能7