当前位置:网站首页>Envi IDL: lire la teneur en colonne de NO2 de tous les produits OMI et calculer la moyenne mensuelle, la moyenne trimestrielle, la moyenne annuelle + résolution
Envi IDL: lire la teneur en colonne de NO2 de tous les produits OMI et calculer la moyenne mensuelle, la moyenne trimestrielle, la moyenne annuelle + résolution
2022-07-19 02:09:00 【Aubergines frites】
Table des matières
1. Contenu de l'expérience
Je n'écrirai pas mes devoirs pour la troisième semaine,Directement lié à cette expérience.

Une réflexion globale:
1. AccèsLon、Lat、NO2Les données de l'ensemble de données et de la paireNO2Les données sont traitées(Traitement de la valeur de remplissage、Conversion des unités、Échange nord - Sud)
2. Somme et compte
3. Moyenne
2. Réserve de connaissances
Parce queOMILe produit estHDF5Documentation,À utiliserHDF5Fonction de corrélation pour,D'autres fonctions de traitement de fichiers sont utilisées.
AccèsHDF5Étapes générales des données:
1. Ouvre.HDF5Documentation,Obtenir des fichiersid(Utiliserh5f_open()Fonctions)
2. Obtenir le nom de l'ensemble de données(Ici, vous pouvez programmer,Mais ce n'est pas vraiment nécessaire,UtiliserHDF ExplorerLe logiciel peut visualiser les ensembles de données、Propriétés、Vous pouvez également voir les données de contenu individuelles, etc,Même visualiser les données)
3. Par le nom de l'ensemble de données et le fichier obtenu précédemmentidObtenir l'ensemble de donnéesid(Adoptionh5d_open()Fonctions)
4. Obtenir des données pour l'ensemble de données (Adoptionh5d_read()Fonctions)
5. Fermer les ensembles de données et les fichiers (Adoptionh5f_close()、h5d_close()Fonctions)
3. Programmation
function get_hdf5_ds, file_path, ds_name
; Fonctions de construction: Obtenir des données pour l'ensemble de données
; Obtenir l'ensemble de données dans le fichier id
file_id = h5f_open(file_path)
; Chemin vers le fichier où se trouve l'ensemble de données entrant
; Obtenir l'ensemble de donnéesid
ds_id = h5d_open(file_id, ds_name)
; Le fichier dans lequel l'ensemble de données est passé id, Nom de l'ensemble de données entrant
; Obtenir des données pour l'ensemble de données
ds_data = h5d_read(ds_id)
; Dans l'ensemble de données id
; Fermer les ensembles de données et les fichiers
h5d_close, ds_id
h5f_close, file_id
; Renvoie les données pour obtenir l'ensemble de données
return, ds_data
end
pro week_three_test
start = systime(1)
; CalculNO2 Moyenne mensuelle de 、 Moyenne trimestrielle 、Moyenne annuelle,EtGeotiffFormat de sortie、 L'Unit é de sortie est mol/km2.
; Exigences: Le programme exige que toutes les moyennes soient calculées en même temps
; Chemins vers tous les fichiers
in_path = 'D:/IDL_program/experiment_data/chapter_2/NO2'
; Chemin vers le fichier de sortie
out_path = 'D:/IDL_program/experiment_data/chapter_2/NO2/output/'
if file_test(out_path, /directory) eq 0 then begin ; Vérifier si le répertoire existe , Créer s'il n'existe pas
file_mkdir, out_path
endif
; Où se trouve l'ensemble de données group Chemin dans le fichier
group_path = '/HDFEOS/GRIDS/ColumnAmountNO2/Data Fields/' ; Utilisez ici\Il y aura une erreur.,Il faut utiliser/
; Nom de l'ensemble de données
ds_name = 'ColumnAmountNO2TropCloudScreened'
; Chemin de l'ensemble de données dans le fichier
ds_path = group_path + ds_name
; Accèsin_path Chemin vers tous les fichiers à l'intérieur
file_path_array = file_search(in_path, '*.he5', count=file_count) ; count=Nombre de documents
; Obtenir le nom du fichier à partir de chaque chemin de fichier
file_name_array = file_basename(file_path_array, '.he5')
; Année à partir du nom du fichier
file_year_array = fix(strmid(file_name_array, 19, 4))
; Obtenir l'année de début et le nombre d'années
start_year = min(file_year_array)
end_year = max(file_year_array)
year_count = end_year - start_year + 1
; Initialisation de diverses données
; Initialisation de l'ensemble de données du mois de stockage
data_total_month = fltarr(1440, 720, 12) ; Chaque ensemble de données est (1440, 720), Douze mois par an
data_valid_month = fltarr(1440, 720, 12) ; Sur certains ensembles de données NO2 Les données sont invalides , Alors nous ne faisons pas la moyenne / 12, Ça dépend du nombre de fois où ça marche.
data_aver_month = fltarr(1440, 720, 12) ; Au - dessusdata_total_month / data_valid_monthJe peux avoir
; Initialisation des ensembles de données de la saison de stockage
data_total_season = fltarr(1440, 720, 4) ; Un an.4Saison
data_valid_season = fltarr(1440, 720, 4) ; Nombre effectif
data_aver_season = fltarr(1440, 720, 4) ; Moyenne
; Initialisation des ensembles de données de l'année de stockage
data_total_year = fltarr(1440, 720, year_count) ; C'est tout.year_countAnnée
data_valid_year = fltarr(1440, 720, year_count)
data_aver_year = fltarr(1440, 720, year_count)
; En boucle
for file_i = 0, file_count - 1 do begin
; Pour vérifier ce fichier NO2 Si l'ensemble de données existe
flag = 0
file_path = file_path_array[file_i] ; Obtenir le chemin du fichier sous cette boucle
file_id = h5f_open(file_path) ; Obtenir des fichiersid
ds_count = h5g_get_nmembers(file_id, group_path) ; Fichier entrantidEtgroup Le chemin renvoie ce group Nombre d'ensembles de données sous
for ds_i = 0, ds_count - 1 do begin
ds_i_name = h5g_get_member_name(file_id, group_path, ds_i)
if ds_i_name eq ds_name then begin
flag = 1
continue
endif
endfor
if flag ne 0 then begin
; Invite le fichier à avoir un ensemble de données
print, 'Exit NO2 data set>>> ' + file_basename(file_path)
; Date à laquelle le document a été obtenu par son nom
file_year = fix(strmid(file_basename(file_path), 19, 4))
file_month = fix(strmid(file_basename(file_path), 24, 2))
; Obtenir des données pour l'ensemble de données
ds_data = get_hdf5_ds(file_path, ds_path)
; Traitement de la valeur de remplissage
ds_data = (ds_data gt 0) * ds_data ; Nombre négatif(Valeur de remplissage)Devenir0
; Conversion des unités(Numérateur/cm2 ————》mol/km2)
ds_data = (ds_data * 10.0 ^ 10.0) / !const.NA
; Changement de position des pôles Nord et Sud
ds_data = rotate(ds_data, 7)
; Enregistrer les ensembles de données————》Mois
data_total_month[*, *, file_month - 1] = data_total_month[*, *, file_month - 1] + ds_data
data_valid_month[*, *, file_month - 1] = data_valid_month[*, *, file_month - 1] + (ds_data gt 0)
; Enregistrer les ensembles de données————》Saison
season_index = [3, 3, 0, 0, 0, 1, 1, 1, 2, 2, 2, 3]
data_total_season[*, *, season_index[file_month - 1]] = data_total_season[*, *, season_index[file_month - 1]] + ds_data
data_valid_season[*, *, season_index[file_month - 1]] = data_valid_season[*, *, season_index[file_month - 1]] + (ds_data gt 0)
; Enregistrer les ensembles de données————》Année
data_total_year[*, *, file_year - start_year] = data_total_year[*, *, file_year - start_year] + ds_data
data_valid_year[*, *, file_year - start_year] = data_valid_year[*, *, file_year - start_year] + (ds_data gt 0)
endif else begin
print, 'Not exit NO2 data set>> ' + file_basename(file_path)
endelse
endfor
; Traitement de la valeur moyenne de l'ensemble de données en mm / JJ / AAAA
; Traitement mensuel
data_valid_month = (data_valid_month gt 0) * data_valid_month + (data_valid_month eq 0) * 1.0
data_aver_month = data_total_month / data_valid_month
; Traitement saisonnier
data_valid_season = (data_valid_season gt 0) * data_valid_season + (data_valid_month eq 0) * 1.0
data_aver_season = data_total_season / data_valid_season
; Traitement annuel
data_valid_year = (data_valid_year gt 0) * data_valid_year + (data_valid_year eq 0) * 1.0
data_aver_year = data_total_year / data_valid_year
; geotiffParamètres
geoinfo = {$
MODELPIXELSCALETAG:[0.25,0.25,0.0],$
MODELTIEPOINTTAG:[0.0,0.0,0.0,-180.0,90.0,0.0],$
GTMODELTYPEGEOKEY:2,$
GTRASTERTYPEGEOKEY:1,$
GEOGRAPHICTYPEGEOKEY:4326,$
GEOGCITATIONGEOKEY:'GCS_WGS_1984',$
GEOGANGULARUNITSGEOKEY:9102,$
GEOGSEMIMAJORAXISGEOKEY:6378137.0,$
GEOGINVFLATTENINGGEOKEY:298.25722}
; Paramètres de sortie
month_out = ['01', '02', '03', '04', '05', '06', '07', '08', '09', '10', '11', '12']
season_out = ['spring', 'summer', 'autumn', 'winter']
; Mois de sortie séquentiel 、Saison、Moyenne annuelle
for month_i = 0, 11 do begin
out_month_path = out_path + 'month_aver_' + month_out[month_i] + '.tiff'
write_tiff, out_month_path, data_aver_month[*, *, month_i], /float, geotiff=geoinfo
print, file_basename(out_month_path) + ' have completed'
endfor
for season_i = 0, 3 do begin
out_season_path = out_path + 'season_aver_' + month_out[season_i] + '.tiff'
write_tiff, out_season_path, data_aver_season[*, *, season_i], /float, geotiff=geoinfo
print, file_basename(out_season_path) + ' have completed'
endfor
for year_i = 0, year_count - 1 do begin
out_year_path = out_path + 'year_aver_' + strcompress(string(year_i + start_year), /REMOVE_ALL) + '.tiff'
write_tiff, out_year_path, data_aver_year[*, *, year_i], /float, geotiff=geoinfo
print, file_basename(out_year_path) + ' have completed'
endfor
; Ici, les résultats annuels sont produits comme suit: txtDocumentation
out_txt_path = out_path
for year_i = 0, year_count - 1 do begin
out_year_path = out_txt_path + 'year_aver_' + strcompress(string(year_i + start_year), /REMOVE_ALL) + '.txt'
openw, 2, out_year_path
printf, 2, 'lon lat NO2'
; Le Centre le plus central de chaque pixel , Un pixel est 0.25*0.25
for row_i = 0, 719 do begin
lat = 89.875 - 0.25 * row_i
for column_i = 0, 1439 do begin
lon = -179.875 + column_i * 0.25
printf, 2, lon, lat, data_aver_year[column_i, row_i, year_i], format='(3(f0.3, :, ","))'
endfor
endfor
print, file_basename(out_year_path) + ' have completed'
free_lun, 2
endfor
stop = systime(1)
print, 'Spend time : ' + strcompress(string(stop - start))
endAffichage des résultats d'exécution de la compilation :

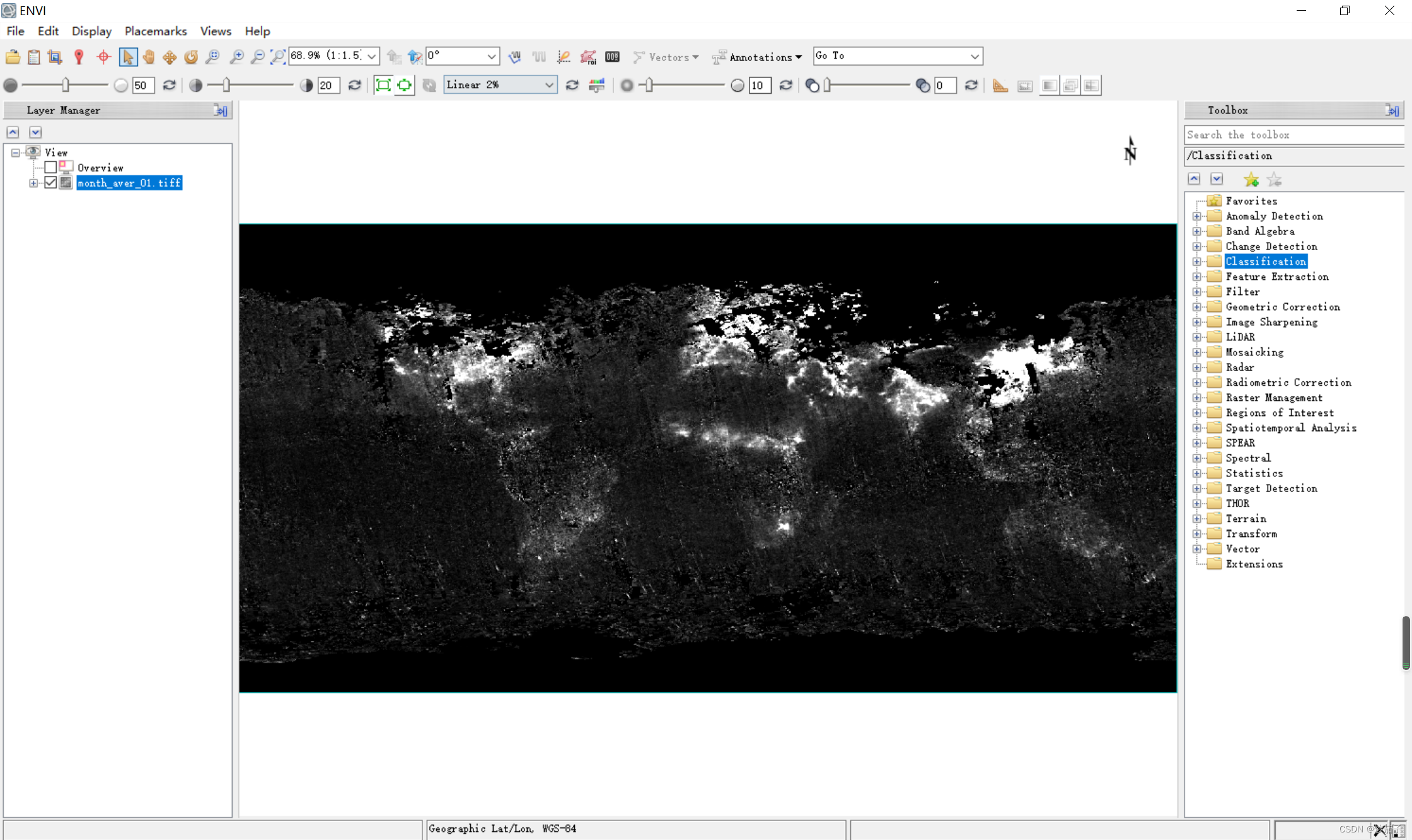
ProduittiffPrésentation des documents:

UtiliserENVI Il n'y a aucun problème à l'ouvrir :
——————————————————————————————————————————
Il faut ajouter ,Erreur signalée ici, Le nombre de points flottants est illégal ! Mais il ne semble pas affecter la production des résultats .
Bien que, Je suis toujours de mauvaise humeur. .
Un autre point est devant. tiff La sortie du fichier est plus rapide , Mais le dernier txt La sortie des fichiers est lente , J'ai failli croire que ça ne marcherait pas. ,Chronométrage91Quelques secondes..
———————————————————————————————————————————
Je suis l'Aubergine frite ,Merci à tous.!
边栏推荐
- 递推与递归学习笔记
- Problems encountered in yolov3 training its own data set
- (附word操作以及视频讲解)使用ARCGIS进行地图配准_投影变换_普通地图制作_专题地图制作
- On the properties and methods of list < t >
- ENVI_IDL:读取OMI数据(HDF5)并输出为Geotiff文件+详细解析
- S32K148EVB 关于ENET Loopback实验
- 搭建Ozzie环境
- Oozie integrated shell
- One vs One Mitigation of Intersectional Bias
- 04 design of indoor wireless positioning system based on ZigBee
猜你喜欢
Apt get update error: hash checksum does not match

AURIX Development Studio安装

二階邊緣檢測 - Laplacian of Guassian 高斯拉普拉斯算子

How to understand volatile and how to use it

Frustratingly Simple Few-Shot Object Detection

(附word操作以及视频讲解)使用ARCGIS进行地图配准_投影变换_普通地图制作_专题地图制作

ENVI_IDL:批量处理Modis Swath数据的重投影并输出为Geotiff格式+详细解析

递推与递归学习笔记

Labelme正常启动,但无法打开

ResNet
随机推荐
Build map reduce development environment
Startup mode of activity
边缘检测方法 -- 一阶边缘检测
03基于ZigBee的城市道路除尘降温系统设计
Allegro design entry CIS and OrCAD capture CIS relationship
Switch details
ENVI_IDL:读取OMI数据(HDF5)并输出为Geotiff文件+详细解析
Hands on deep learning -- from full connection layer to convolution layer
Array definition format
捉虱子的博弈论
Oozie 集成 Shell
SAE j1708/j1587 protocol details
Combined key screenshot analysis
Leveraging Semi-Supervised Learning for Fairness using Neural Networks
ENVI_IDL:批量重投影Modis Swath产品并指定范围输出为Geotiff格式+解析
gdb+vscode进行调试4——gdb执行相关命令
ENVI_IDL:批量重投影ModisSwath产品(调用二次开发接口)+解析
池式组件之内存池篇
ENVI_IDL:批量对Modis Swath产品进行均值运算+解析
VS Code 问题:launch:program‘...\.vscode\launch.exe‘ dose not exist