当前位置:网站首页>Leveraging Semi-Supervised Learning for Fairness using Neural Networks
Leveraging Semi-Supervised Learning for Fairness using Neural Networks
2022-07-19 01:57:00 【Chubby Zhu】
Using neural network to realize the fairness of semi supervised learning (in-processing)
There are generally three stages of data processing :pre-processing,in-processing,post-processing, This paper is in-processing
Research background : First, the lack of tag data has always been a problem for machine learning based systems . Second, in some applications , Creating a label data set to train the model is expensive and time-consuming . under these circumstances , Semi supervised learning has been proved to be an effective method to improve the performance of the model by using unlabeled data . There is no denying that , Unlabeled data does not contain label information , Label information itself may be an important source of deviation in training machine learning systems .
Innovation points : This paper presents a semi supervised algorithm of neural network using unlabeled data , Not only improved performance , And it improves the fairness of the decision-making process . The model is called SSFair, Use the information in the unlabeled data to reduce the deviation in the training data .
Research objectives : Through experiments, it is proved that SSFair, Compared with the fully supervised model ,SSFair The structure and information of unmarked data can be used to improve accuracy and fairness ,SSFair It provides higher accuracy for the same level of fairness loss .
Research process : Through the experiment , indicate SSFair Methods can optimize “ Population equality , Equal opportunities , Equal probability ” These three equity goals .
The goal is to learn a binary classifier function ![]()
![]() adopt Θ A parameterized , Two main objectives of optimization Classification accuracy and fair . The function will be established through neural network f(.) Model of , In order to achieve this goal , The loss function of the model is defined as
adopt Θ A parameterized , Two main objectives of optimization Classification accuracy and fair . The function will be established through neural network f(.) Model of , In order to achieve this goal , The loss function of the model is defined as ![]()
A. Classified loss

jc(Xi) Presentation sample Xi Classification loss of , It is defined as the cross entropy between the output of the learning function and the target tag :
![]()
![]() Represents the learning function to the sample Xi Output ,qi yes Xi Corresponding target tag ,
Represents the learning function to the sample Xi Output ,qi yes Xi Corresponding target tag ,![]() Indicates whether samples need to be considered in the learning process Xi,
Indicates whether samples need to be considered in the learning process Xi,![]() Is the index function that makes the sample return to zero
Is the index function that makes the sample return to zero

![]() Define a threshold , This threshold controls the confidence of the prediction label that needs to be considered in the learning process
Define a threshold , This threshold controls the confidence of the prediction label that needs to be considered in the learning process
B: Fair loss
1) Population equality : It measures the difference in the ability of protected groups and unprotected groups to predict the output of dominance , The decision of the classifier is required to be independent of the protected attribute a
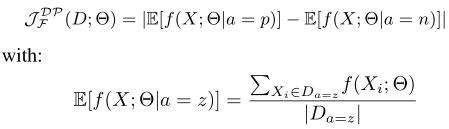
2) Equal opportunities : This measurement focuses on the fairness of favorable results . The difference of the predicted beneficial output probability between the protected group and the unprotected group with beneficial reality is measured .

3) Equal probability : This constraint requires output and protected Attributes are independent of tags
![]()
besides , There are other fairness measures : Can we make corresponding improvements to this article ?

C. experiment : Classifier functions f(.) By a multi-layer perception (MLP) Neural network modeling . The training of the whole model uses the loss function of back propagation . In a given set N In the case of two samples , Use Adam Optimization technology optimizes small batches of random data .
Data sets ![]() : Research predicts whether a person's income exceeds 5 Million dollar task . In these two groups , The proportion of high-income people is not equal , Therefore, there is no demographic equality in the data set . This data set contains 12 Features , Including classification features and continuous features . Samples with missing values are filtered out , The processed dataset contains 45222 Samples ,12 Features . Random selection 70% As a training set , The rest 30% Leave it to the test set .
: Research predicts whether a person's income exceeds 5 Million dollar task . In these two groups , The proportion of high-income people is not equal , Therefore, there is no demographic equality in the data set . This data set contains 12 Features , Including classification features and continuous features . Samples with missing values are filtered out , The processed dataset contains 45222 Samples ,12 Features . Random selection 70% As a training set , The rest 30% Leave it to the test set .
The hyperparameters of the proposed algorithm are adjusted and verified in a randomly selected 20% Training data . After setting the super parameters , Train the model on the whole training set , Finally, report the results of the test data in the experiment .
The experimental results of this paper are consistent with Manisha The models proposed by et al , This model is based on Neural Network , Used to solve fairness problems , It is fully supervised , Only the labeled samples are trained . In the experiment , about SSFair and Manisha The proposed model , Based on multilayer perceptron (MLP) The neural network of , Use 1 Size is 32 Hidden layer to model functions f(X). The output of hidden layer adopts rectification linear unit (ReLU) Activate . Because the task is binary classification , We use sigmoid Function as the activation function of the last layer , And get the final output . Use after hidden layers dropout layer ,dropout Rate is 20%. According to the results of the validation process , Each experiment starts from ![]() Select the regularization parameter . Last , Set the confidence parameter fitting coefficient to 0.99 in order to SSFair.
Select the regularization parameter . Last , Set the confidence parameter fitting coefficient to 0.99 in order to SSFair.
We use Adam Optimizer to train the model . We choose a learning rate of 10−3, For other parameters of the optimizer , We use the recommended default . Training neural networks is done by running Adam To complete 1000 individual epoch Training data , When used, the size is 512 When mixed in small batches .
experimental result : This experiment verifies SSFair Fairness in the model can benefit from unmarked data , therefore SSFair The method has successfully utilized unlabeled data to improve fairness . In general , accuracy 、 There is a trade-off between fairness and parameters , Moderate control of this trade-off : increase ![]() It will increase accuracy and reduce fairness .( The lower the fair loss , The higher the fairness )
It will increase accuracy and reduce fairness .( The lower the fair loss , The higher the fairness )
summary : Because data without labels does not include any label information , They also don't hold biased label information . therefore , They are not only conducive to the accuracy of the classifier , And it is conducive to the fairness of the classifier . Experiments show that , Compared with the fully supervised model ,SSFair The structure and information of unmarked data can be used to improve accuracy and fairness
边栏推荐
猜你喜欢
[go language] code coverage test (Gcov)

【文献阅读】Counting Integer Points in Parametric Polytopes Using Barvinok‘s Rational Functions

L1,L2范数

Fair Attribute Classification through Latent Space De-biasing

touchID 和 FaceID~1

Owl Eyes: Spotting UI Display Issues via Visual Understanding

Mxnet network model (V) conditional Gan neural network

The popularity of NFT IP licensing is rising, and the era of nft2.0 is coming?
![[literature reading] vaqf: full automatic software hardware co design framework for low bit vision transformer](/img/41/aca6596b1fa50a1940791e6e00a17a.png)
[literature reading] vaqf: full automatic software hardware co design framework for low bit vision transformer

【文献阅读】Small-Footprint Keyword Spotting with Multi-Scale Temporal Convolution
![[go language] code coverage test (Gcov)](/img/6d/2c2b91becbd6a42c1f4e3259ffa6e2)
随机推荐
ACE下载地址
2章 性能平台GodEye源码分析-数据模块
Cocos Creator 3.0 基础——常见操作
Hands on deep learning -- linear neural network
Owl Eyes: Spotting UI Display Issues via Visual Understanding
开源项目丨 Taier 1.1 版本正式发布,新增功能一览为快
【翻译】Transformers in Computer Vision
GoogLeNet
网络安全新架构:零信任安全
深度伪造对国家安全的挑战及应对
Learning Transferable Visual Models From Natural Language Supervision
[literature reading] vaqf: full automatic software hardware co design framework for low bit vision transformer
Handling conditional discrimination
mysql innodb 事务相关记录
6章 性能平台GodEye源码分析-自定义拓展模块
监听浏览器返回操作-禁止返回上一页
ViLT Vision-and-Language Transformer Without Convolution or Region Supervision
README.md添加目录
14:07:08 ckati failed with: signal: killed
Hands on deep learning - deep learning computing