Towards Abstractive Grounded Summarization of Podcast Transcripts
We provide the source code for the paper "Towards Abstractive Grounded Summarization of Podcast Transcripts" accepted at ACL'22. If you find the code useful, please cite the following paper.
@inproceedings{song-etal-2022-grounded,
title="Towards Abstractive Grounded Summarization of Podcast Transcripts",
author = "Song, Kaiqiang and
Li, Chen and
Wang, Xiaoyang and
Yu, Dong and
Liu, Fei",
booktitle={Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics},
year={2022}
}
Goal
We proposed a grounded summarization system, which provide each summary sentence a linked chunk of the original transcripts and their audio/video recordings. It allows a human evaluator to quickly verify the summary content against source clips. 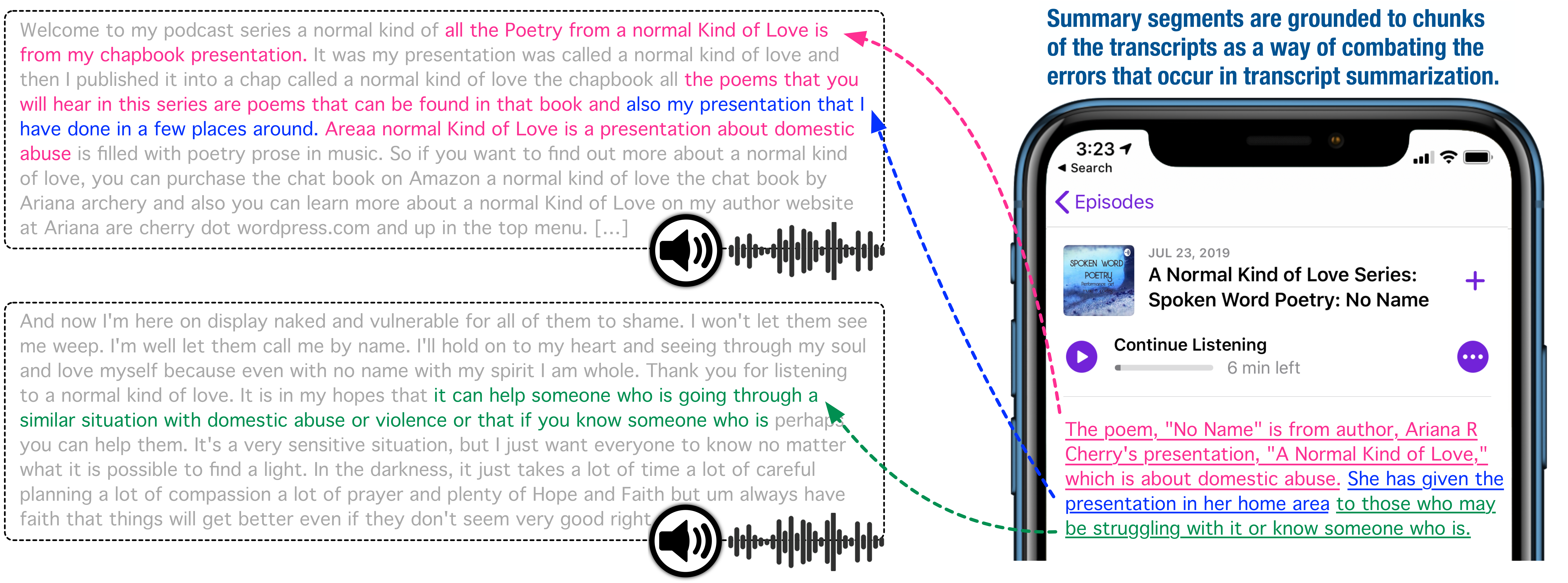
News
- 03/04/2022 Trained model and processed testing data released.
- 03/03/2022 Code Released. Paper link, trained model and processed testing data will be released soon.
- 02/23/2022 Paper accepted at ACL 2022.
Experiments
You can follow the below 4 steps to generate grounded podcast summaries or directly download the generated summary from this link
Step 1: Download Code, Model & Data
Download the code
git clone https://github.com/tencent-ailab/GrndPodcastSum.git
cd GrndPodcastSum
Download the Trained Models to GrndPodcastSum Directory and unzip
unzip model.zip
Download the Processed Test Set (1027) to GrndPodcastSum Directory and unzip
unzip data.zip
Step 2: Setup Environment
Create the environment using .yml file.
conda env create -f env.yml
conda activate GrndPodcastSum
Step 3. Offline Computing for Chunk Embeddings
Calculating the chunk embedding offline.
sh offline.sh
Step 4. Generating Grounded Summary
Use Grnd-token-nonoveralp model to generate summary.
sh test.sh
License
Copyright 2022 Tencent
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
Disclaimer
This repo is only for research purpose. It is not an officially supported Tencent product.

 247 Dec 26, 2022
247 Dec 26, 2022
 102 Dec 07, 2022
102 Dec 07, 2022
 9 Dec 28, 2022
9 Dec 28, 2022
 3k Jan 06, 2023
3k Jan 06, 2023
 295 Jan 07, 2023
295 Jan 07, 2023
 1 Nov 20, 2021
1 Nov 20, 2021
 3 Jun 20, 2022
3 Jun 20, 2022
 112 Dec 05, 2022
112 Dec 05, 2022
 1 Oct 20, 2021
1 Oct 20, 2021
 6.4k Jan 09, 2023
6.4k Jan 09, 2023
 3 Dec 28, 2021
3 Dec 28, 2021
 8.5k Jan 03, 2023
8.5k Jan 03, 2023
 394 Dec 17, 2022
394 Dec 17, 2022
 3 Dec 05, 2022
3 Dec 05, 2022
 13.2k Jul 07, 2021
13.2k Jul 07, 2021
 43 Jan 05, 2023
43 Jan 05, 2023
 76 Dec 14, 2022
76 Dec 14, 2022
 47 Nov 18, 2022
47 Nov 18, 2022
 7 Dec 25, 2022
7 Dec 25, 2022
 581 Dec 21, 2022
581 Dec 21, 2022