Bridging Video-text Retrieval with Multiple Choice Questions, CVPR 2022 (Oral)
Paper | Project Page | Pre-trained Model | CLIP-Initialized Pre-trained Model 
News
2022-04-17 We release the pre-trained model initialized from CLIP (ViT-B/32) and its usage (text-to-video retrieval and video feature extraction).
2022-04-08 We release the pre-training and downstream evaluation code, and the pre-trained model.
Main Results on Downstream Tasks
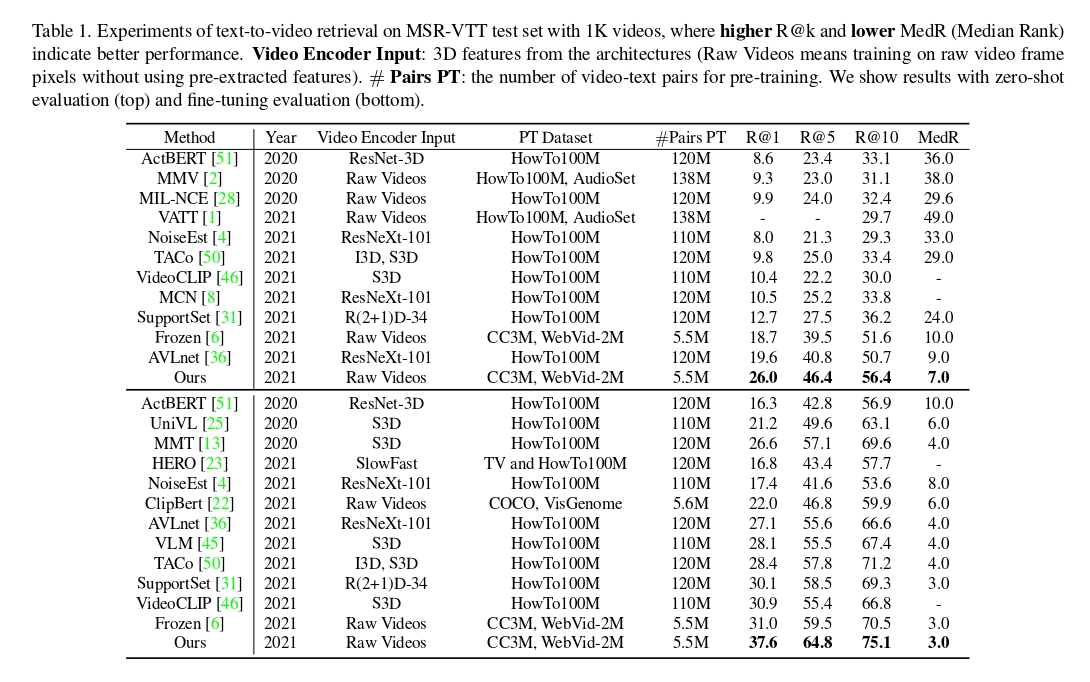
Text-to-video Retrieval on MSR-VTT
Text-to-video Retrieval on MSVD, LSMDC and DiDeMo

Visualization
Answer Noun Questions
We visualize cross-modality attention between the text tokens of noun questions and video tokens from BridgeFormer. In the second and fifth column, the noun phrase marked in blue (Q1) is erased as the question, and in the third and sixth column, the noun phrase marked in green (Q2) is erased as the question. BridgeFormer attends to video patches with specific object information to answer noun questions.

Answer Verb Questions
We visualize cross-modality attention between the text tokens of verb questions and video tokens from BridgeFormer. Three frames sampled from a video are shown and the verb phrase marked in blue (Q) is erased as the question. BridgeFormer focuses on object motions of video tokens to answer verb questions.

Dependencies and Installation
- Python >= 3.8 (Recommend to use Anaconda)
- PyTorch >= 1.7
- NVIDIA GPU + CUDA
Installation
-
Clone repo
git clone https://github.com/TencentARC/MCQ.git cd MCQ -
Install dependent packages
pip install -r requirements.txt
-
Download the DistilBERT base model from Hugging Face in hugging face or in distilbert-base-uncased. Put "distilbert-base-uncased" under the directory of this repo.
Data Preparation
Please refer to DATA.md for pre-training and downstream evaluation datasets.
Pre-training
We adopt the curriculum learning to train the model, which pre-trains the model on the image dataset CC3M and video dataset WebVid-2M using 1 frame, and then on the video dataset WebVid-2M using 4 frames.
-
For 1-frame pre-training, since a single frame does not contain temporal dynamics to correspond to verb phrases, we train the model to answer only noun questions.
bash sctripts/train_1frame_mask_noun.shWhen the training loss converges, we get model "MCQ_1frame.pth".
-
For 4-frame pre-training, to save computation cost to enable a comparatively large batch size for contrastive learning, we train the model to anwer noun and verb questions sequentially. We first train the model to answer noun questions with "MCQ_1frame.pth" loaded in "configs/dist-4frame-mask-noun.json".
bash sctripts/train_4frame_mask_noun.shWhen the training loss converges, we get model "MCQ_4frame_noun.pth". We then train the model to answer verb questions with "MCQ_4frame_noun.pth" loaded in "configs/dist-4frame-mask-verb.json".
bash sctripts/train_4frame_mask_verb.shWhen the training loss converges, we get the final model.
-
Our repo adopts Multi-Machine and Multi-GPU training, with 32 A100 GPU for 1-frame pre-training and 40 A100 GPU for 4-frame pre-training.
Pre-trained Model
Our pre-trained model can be downloaded in Pre-trained Model, which contains the weights of VideoFormer, TextFormer and BridgeFormer. For downstream evaluation, you only need to load the weights of VideoFormer and TextFormer, with BridgeFormer removed.
Downstream Retrieval (Zero-shot on MSR-VTT)
-
Download our pre-trained model in Pre-trained Model (Or use your own pre-traind model).
-
Load the pre-trained model in "configs/zero_msrvtt_4f_i21k.json".
bash sctripts/test_retrieval.sh
CLIP-initialized Pre-trained Model
We also initialize our model from CLIP weights to pre-train a model with MCQ. Specifically, we use the pre-trained CLIP (ViT-B/32) as the backbone of VideoFormer and TextFormer, and randomly initialize BridgeFormer. Our VideoFormer does not incur any additional parameters compared to the ViT of CLIP, with a parameter-free modification to allow for the input of video frames with variable length.
To evaluate the performance of the CLIP-initialized pre-trained model on text-to-video retrieval,
-
Download the model in CLIP-Initialized Pre-trained Model.
-
Load the pre-trained model in "configs/zero_msrvtt_4f_i21k_clip.json".
bash sctripts/test_retrieval_CLIP.sh
We also provide a script to extract video features of any given videos from the CLIP-initialized pre-trained model,
python extract_video_features_clip.py
To Do
- Release pre-training code
- Release pre-trained model
- Release downstream evaluation code
- Release CLIP-initialized model
- Release video representation extraction code
License
MCQ is released under BSD 3-Clause License.
Acknowledgement
Our code is based on the implementation of "Frozen in Time: A Joint Video and Image Encoder for End-to-End Retrieval" https://github.com/m-bain/frozen-in-time.git.
Citation
If our code is helpful to your work, please cite:
@article{ge2022bridgeformer,
title={BridgeFormer: Bridging Video-text Retrieval with Multiple Choice Questions},
author={Ge, Yuying and Ge, Yixiao and Liu, Xihui and Li, Dian and Shan, Ying and Qie, Xiaohu and Luo, Ping},
journal={arXiv preprint arXiv:2201.04850},
year={2022}
}

 6 May 22, 2022
6 May 22, 2022
 27 Jun 20, 2022
27 Jun 20, 2022
 12.3k Jan 05, 2023
12.3k Jan 05, 2023
 170 Dec 27, 2022
170 Dec 27, 2022
 312 Dec 30, 2022
312 Dec 30, 2022
 1.9k Jan 02, 2023
1.9k Jan 02, 2023
 53 Dec 23, 2022
53 Dec 23, 2022
 350 Dec 19, 2022
350 Dec 19, 2022
 572 Jan 05, 2023
572 Jan 05, 2023
 428 Nov 22, 2022
428 Nov 22, 2022
 81 Dec 23, 2022
81 Dec 23, 2022
 147 Dec 20, 2022
147 Dec 20, 2022
 90 Dec 22, 2022
90 Dec 22, 2022
 4 Sep 29, 2022
4 Sep 29, 2022
 1.9k Dec 28, 2022
1.9k Dec 28, 2022
 1 Jan 31, 2022
1 Jan 31, 2022
 2 Feb 22, 2022
2 Feb 22, 2022
 2 Nov 03, 2022
2 Nov 03, 2022
 111 Nov 13, 2022
111 Nov 13, 2022
 1.1k Dec 24, 2022
1.1k Dec 24, 2022