项目简介
学习强国自动化脚本,解放你的时间!
使用Selenium、requests、mitmpoxy、百度智能云文字识别开发而成
使用说明
注:Chrome版本
驱动会自动下载
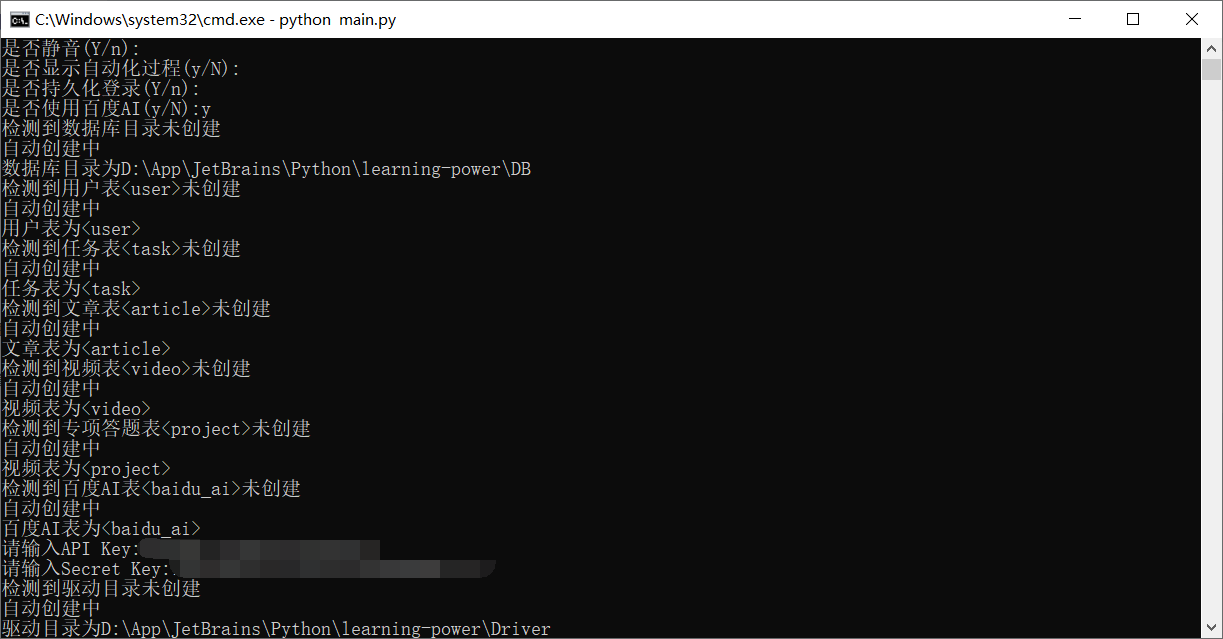
首次使用会生成数据库文件db.db,用于提高文章、视频任务效率。

依赖安装
pip install -r requirements.txt
没有梯子的同学可使用国内阿里源:
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple
使用方法
一定要找个网络好的地方,不然可能会出现错误
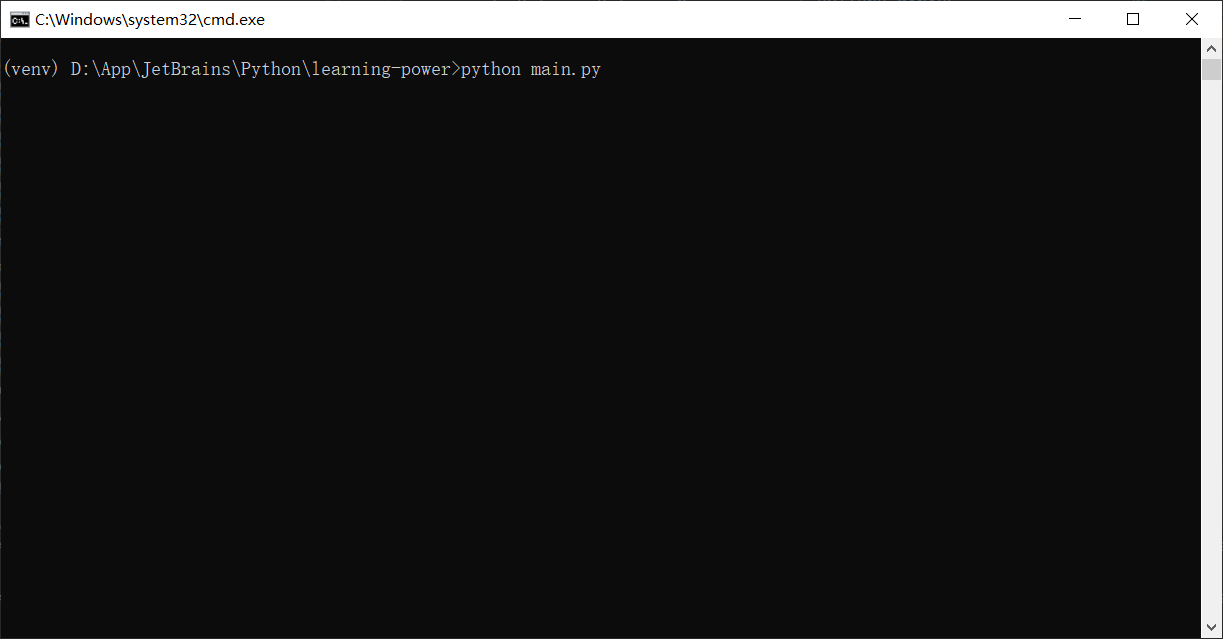
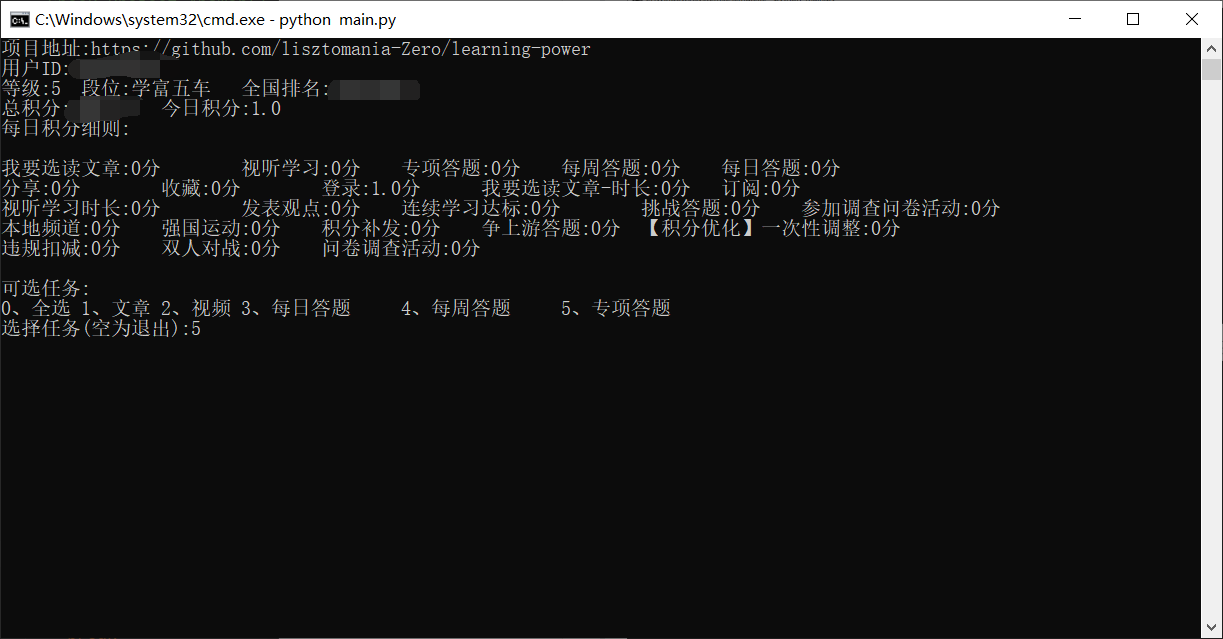
1、控制台运行:python main.py
2、选择选项(如非必要,尽量选择不显示自动化过程,以免误操)
等待片刻,连接学习强国服务器需要时间,等待时间与网速关系很大。
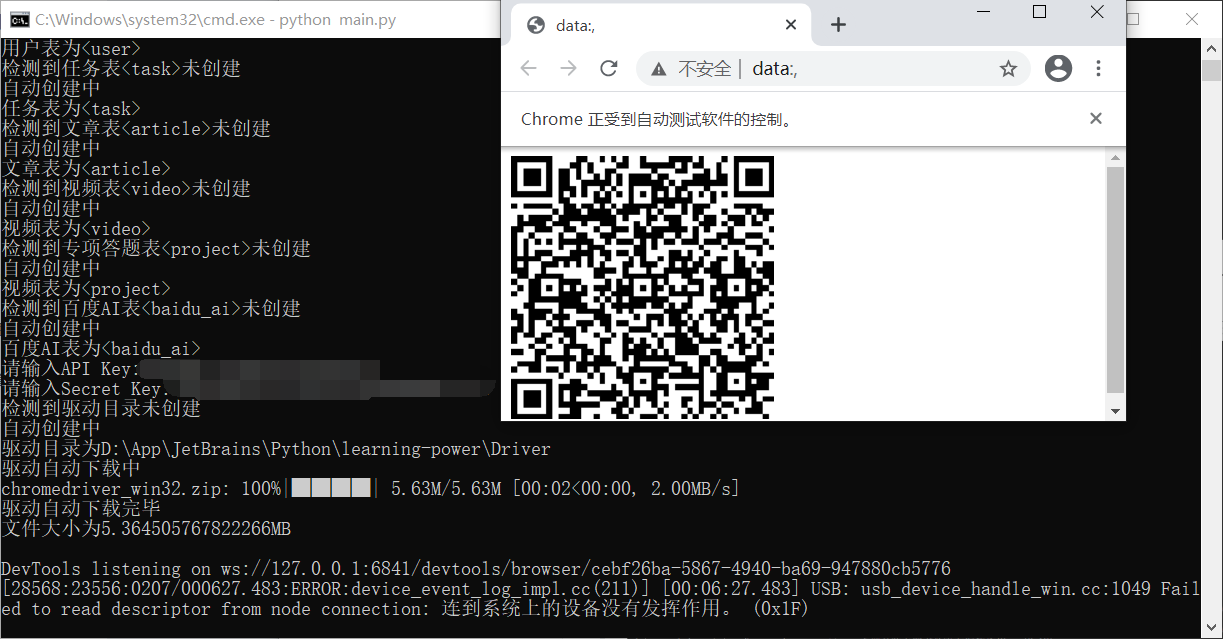
3、扫描二维码登录
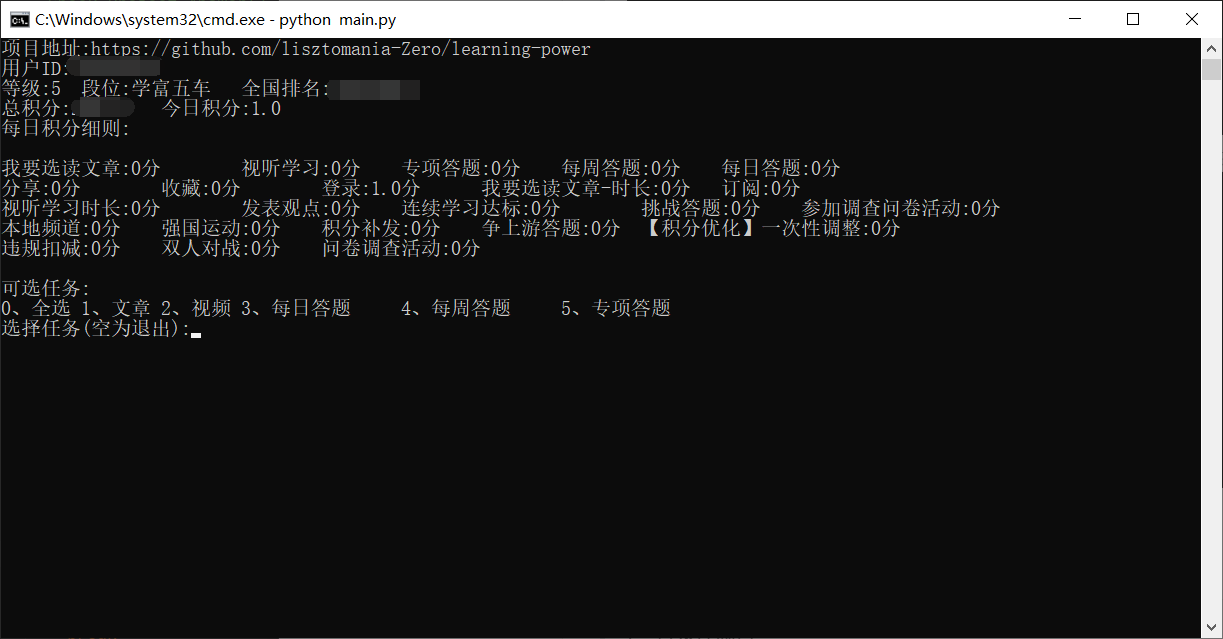
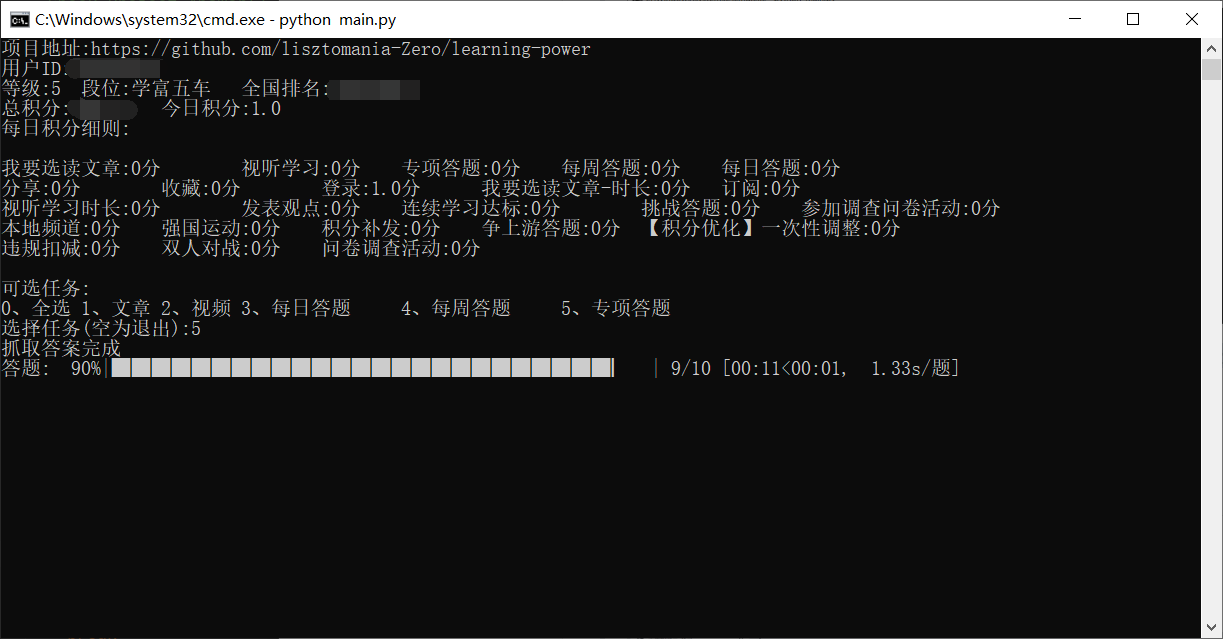
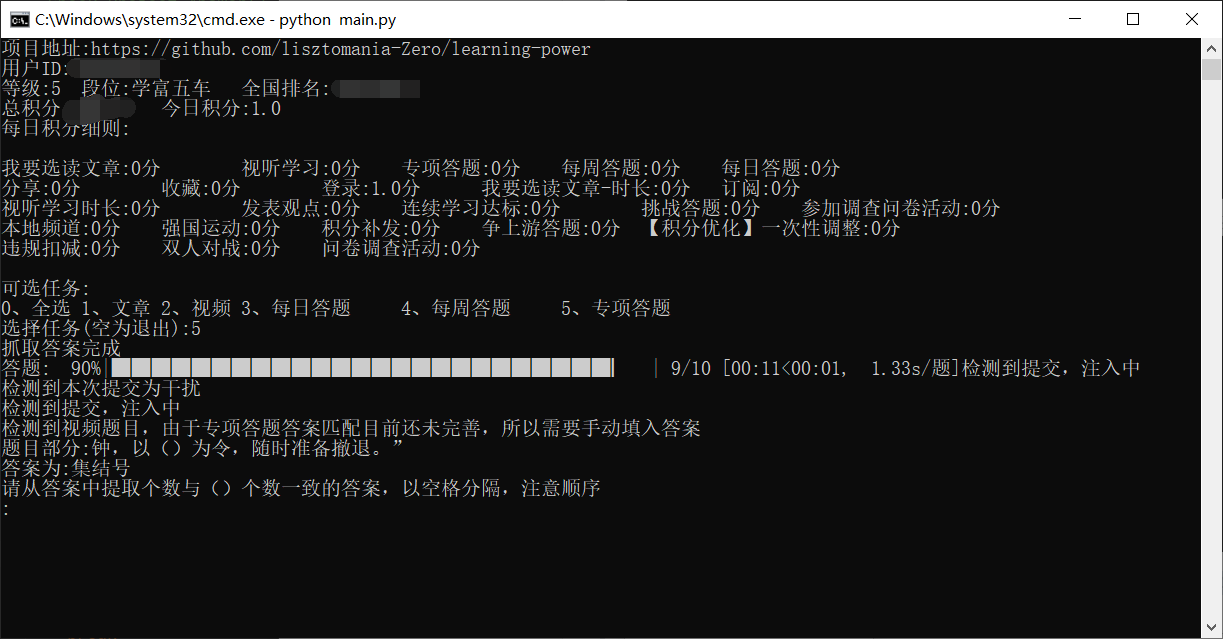
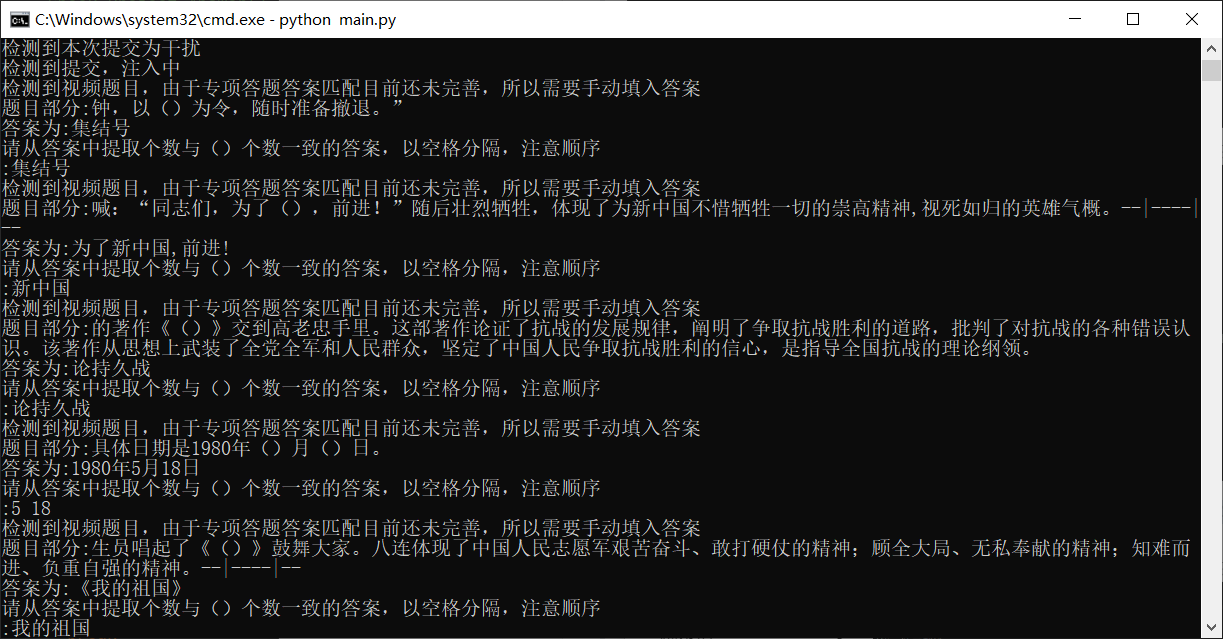
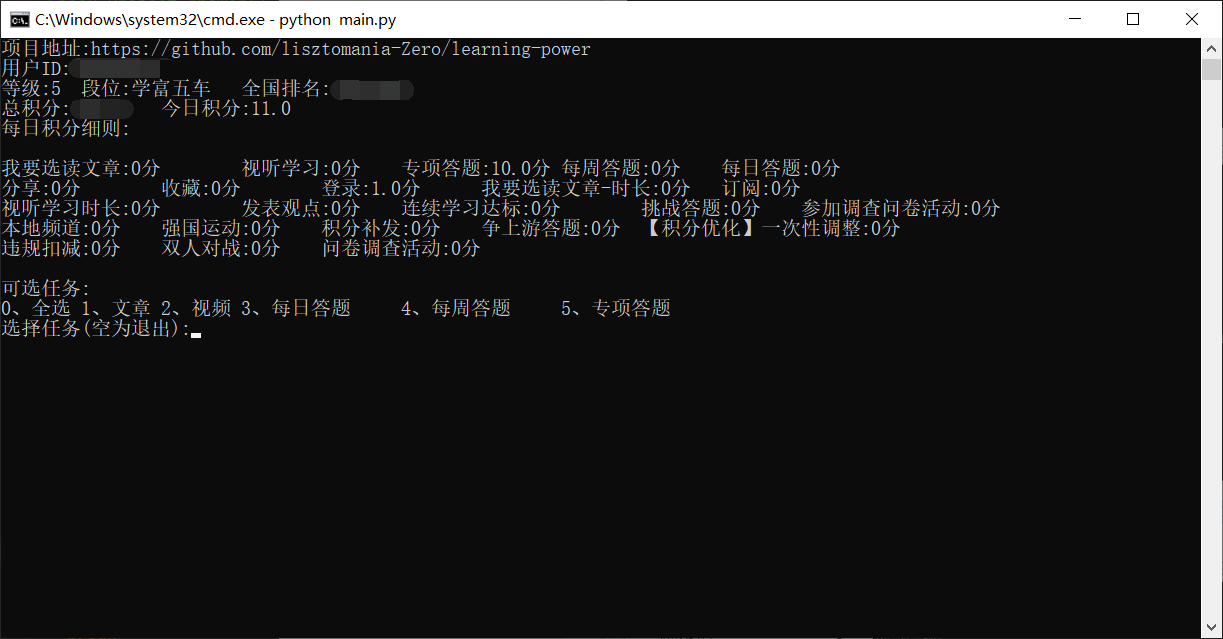
4、选择任务(暂时只支持文章、视频、每日答题、每周答题、专项答题,后续功能正在开发,不过暂时也差不多够用了,45分呢),可多选,不过每个选项要用空格隔开,选择文章或视频时,等待时间稍久一点。
5、任务完成后需手动结束程序
使用示例
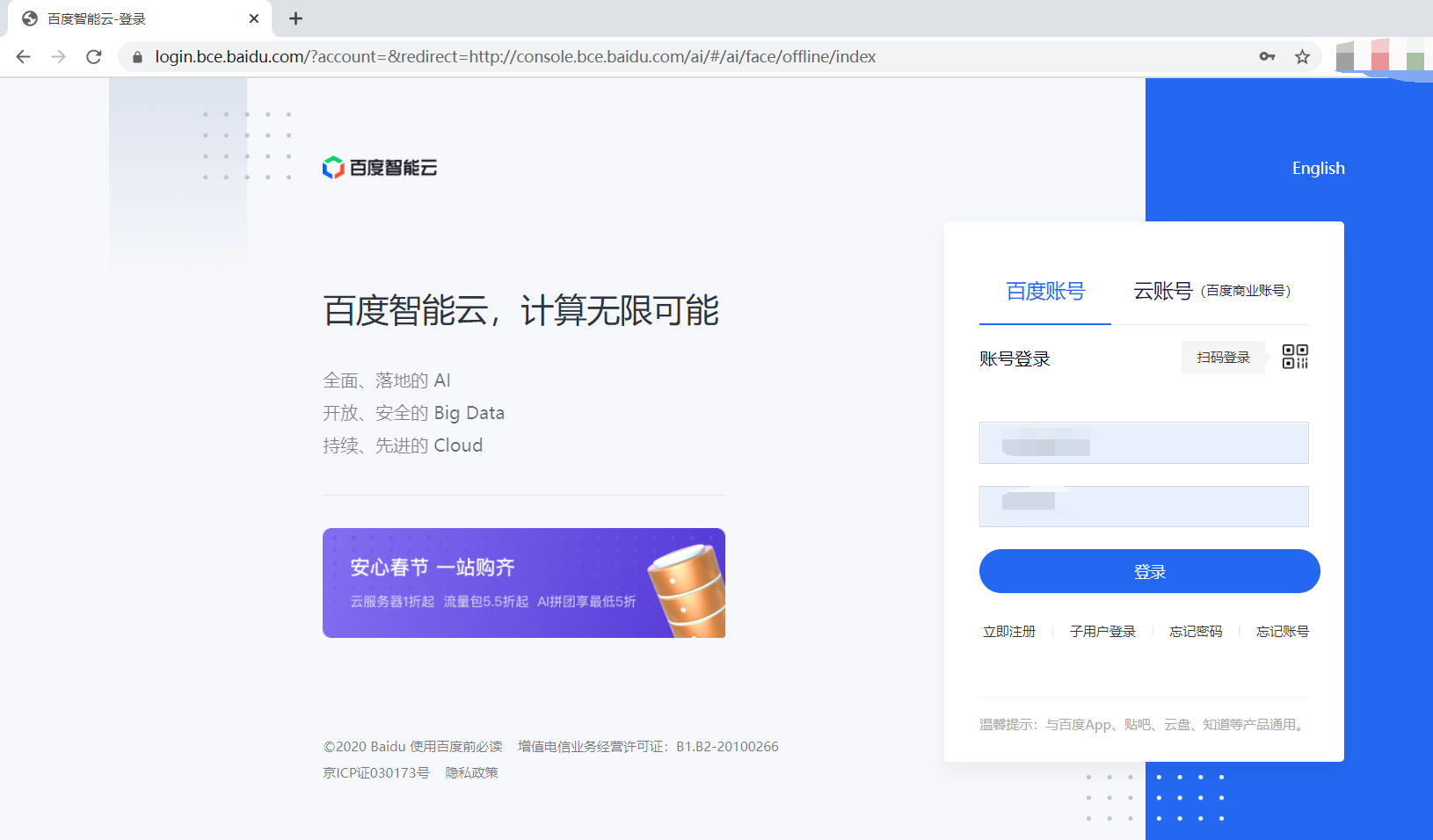
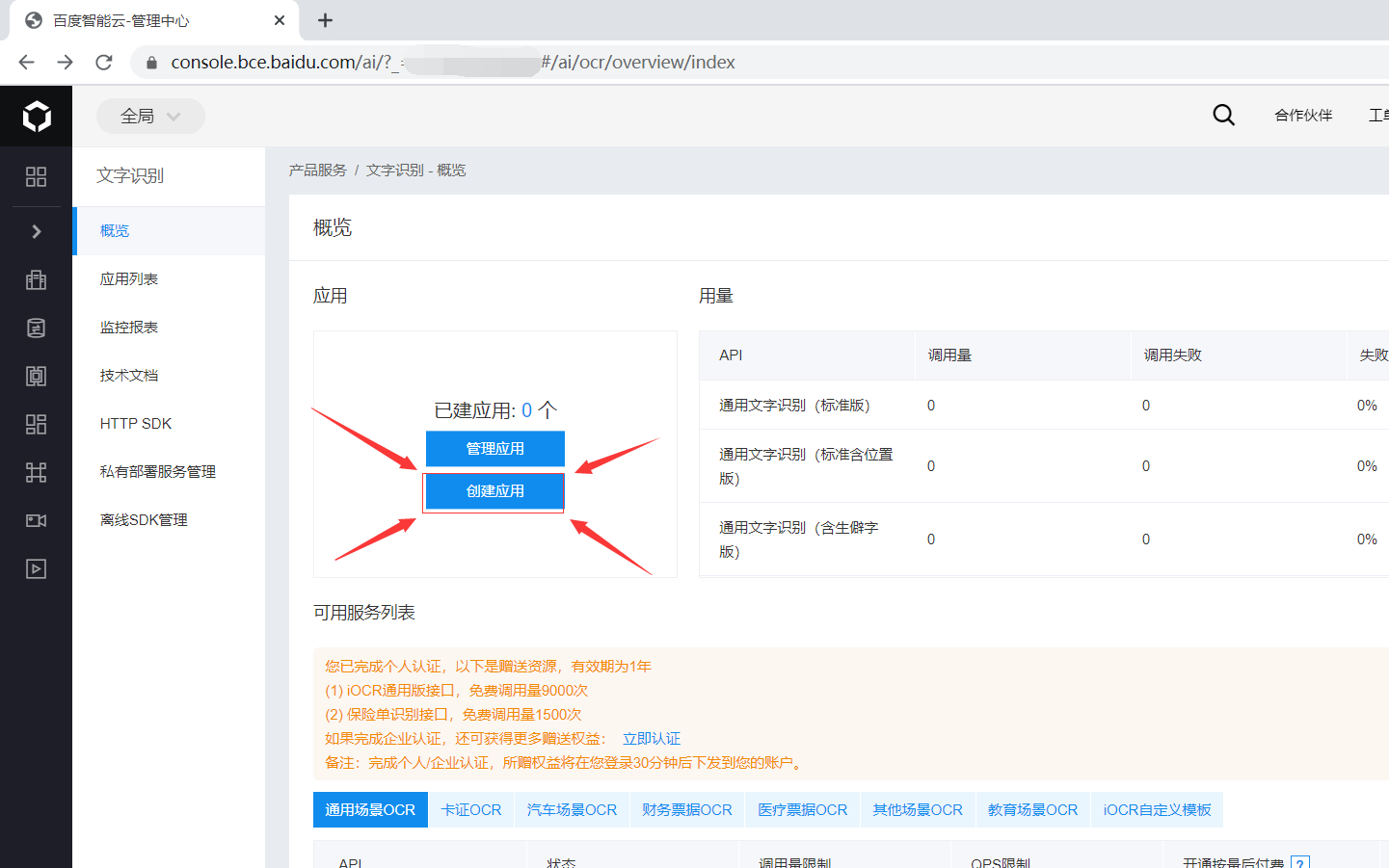
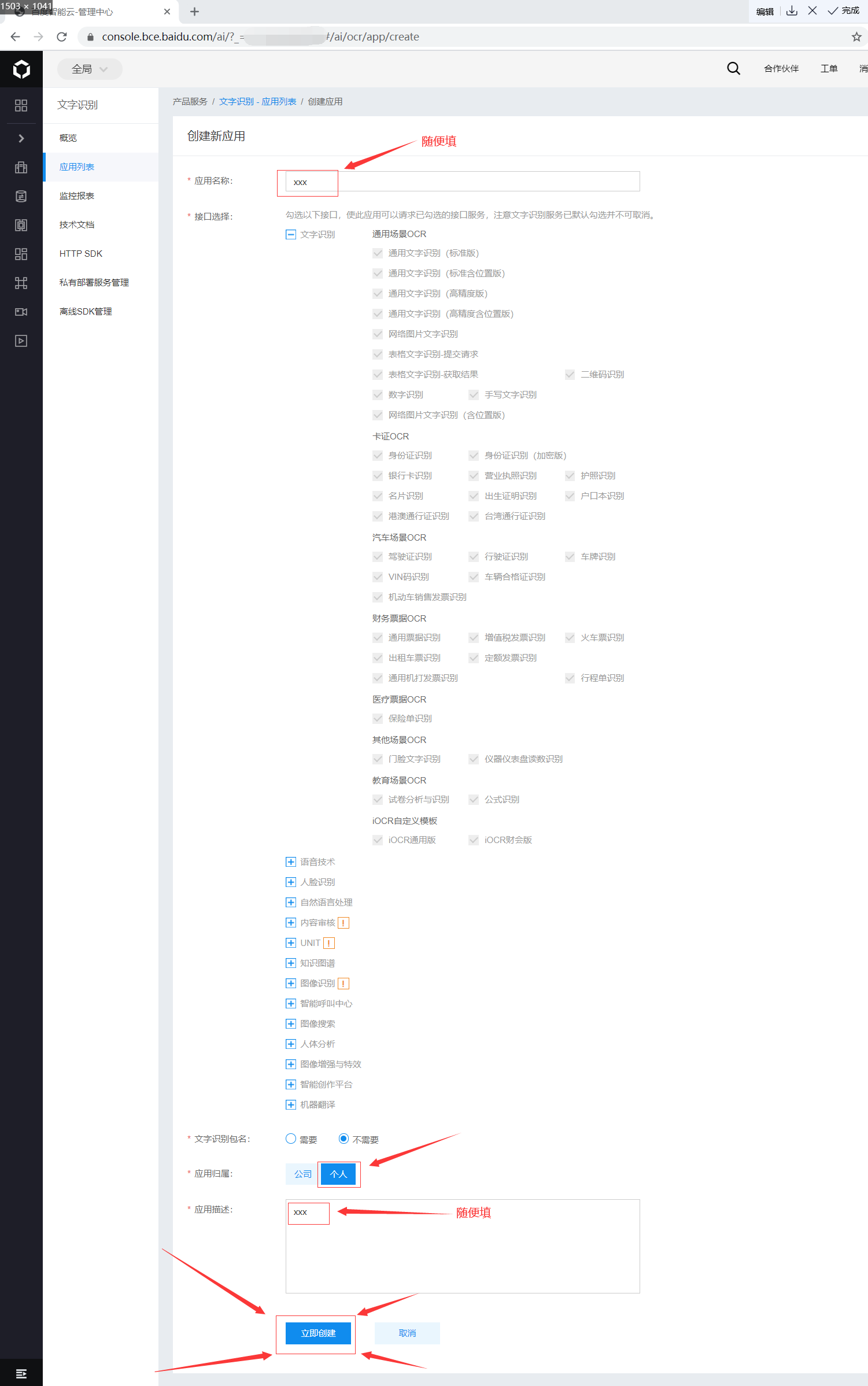
百度智能云操作流程
1、登录控制台
点击→百度智能云
2、创建应用
3、选择选项
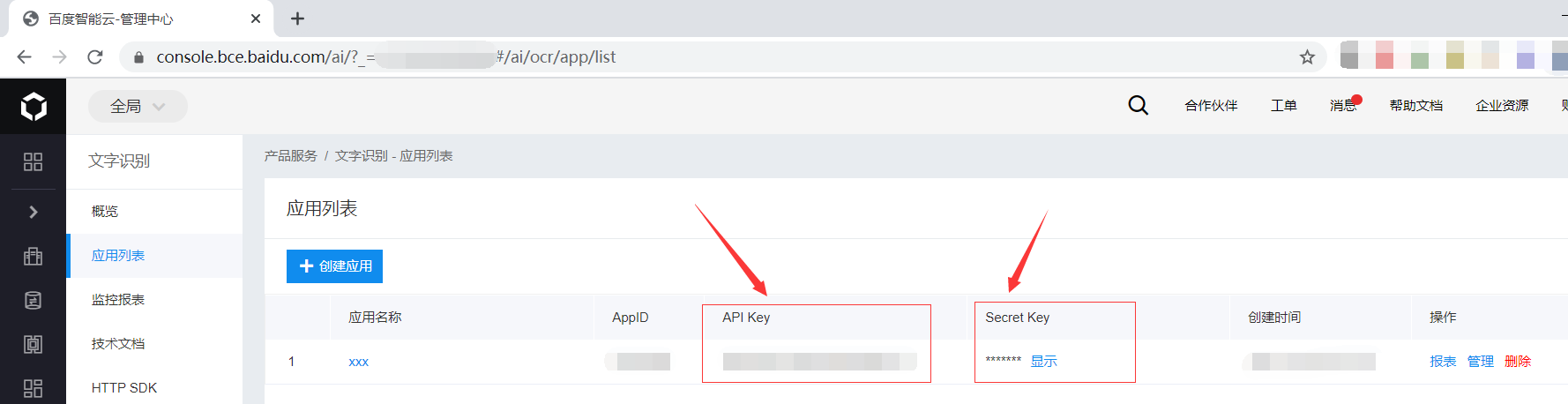
4、获取API Key、Secret Key
版本说明
v0.1:文章、视频,分数:25v0.2:优化文章、优化视频、每日答题(百分百正确),分数30v0.3:新增每周答题、专项答题(也是百分百正确),分数45v0.31:优化记录存储、优化目录结构、优化配置文件结构,增加进度条、增加自动下载驱动、增加系统兼容(Linux、Windows、MacOS)v1.0: 重构整个项目,增加持久化、驱动自动检测与谷歌浏览器匹配、驱动自主下载、更快的登录、文章和视频自适应、更快更精准的答题、加强的防检测、每个文件都有说明注释(便于各位大佬修改)- v1.1: 由于专项答题视频答案匹配问题,现加入百度智能云的文字识别功能,可将视频中的答案提取出来,不过答案还需手动填写,因为提取的答案暂时没有好的办法过滤。至少不用看视频了是不2333.
附语
在持久化登录方面思考了很久,要不要做批量持久化?,后来想了想,本项目的目的是为了帮助没有时间做学习强国任务的个人节省时间,如果做了批量的话,恐怕会沦为某些人的牟利工具。所以最后决定只做单用户持久模式,如果有想做批量的话,建议细读学习强国App积分页的提醒警示。
希望大佬点点start,给点动力,希望能给大家带来更多的功能!

 46 Dec 16, 2022
46 Dec 16, 2022
 36 Oct 27, 2022
36 Oct 27, 2022
 1.5k Jan 04, 2023
1.5k Jan 04, 2023
 9 Nov 16, 2022
9 Nov 16, 2022
 1 Jan 10, 2022
1 Jan 10, 2022
 725 Jan 03, 2023
725 Jan 03, 2023
 112 Nov 12, 2022
112 Nov 12, 2022
 25 Oct 31, 2022
25 Oct 31, 2022
 4 Aug 30, 2022
4 Aug 30, 2022
 95 Jan 07, 2023
95 Jan 07, 2023
 7 Nov 27, 2022
7 Nov 27, 2022
 4.8k Jan 04, 2023
4.8k Jan 04, 2023
 22 Nov 21, 2022
22 Nov 21, 2022
 1 Dec 07, 2021
1 Dec 07, 2021
 35 Aug 29, 2022
35 Aug 29, 2022
 1 Dec 30, 2021
1 Dec 30, 2021
 1 Jan 24, 2022
1 Jan 24, 2022
 3 May 31, 2022
3 May 31, 2022
 1 Nov 05, 2021
1 Nov 05, 2021
 1 Nov 03, 2021
1 Nov 03, 2021