SinGlow: Generative Flow for SVS tasks in Tensorflow 2
See more in the paper: SinGlow: Singing Voice Synthesis with Glow ---- Help Virtual Singers More Human-like
SinGlow is a part of my Singing voice synthesis system. It can extract features of sound, particularly songs and musics. Then we can use these features (or perfect encoding) for feature migrating tasks. For example migrate features of real singers' song to those virtual singers' songs.
This project is developed above the project GLOW-tf2 under MIT licence, and the following words are from its developers.
My implementation of GLOW from the paper https://arxiv.org/pdf/1807.03039 in Tensorflow 2. GLOW is an interesting generative model as it uses invertible neural network to transform images to normal distribution and vice versa. Additionally, it is strongly based on RealNVP, so knowing it would be helpful to understand GLOW's contribution.
Table of Contents
Abstract
Singing voice synthesis (SVS) is a task using the computer to generate songs with lyrics. So far, researchers are focusing on tunning the pre-recorded sound pieces according to rigid rules. For example, in Vocaloid, one of the commercial SVS systems, there are 8 principal parameters modifiable by song creators. The system uses these parameters to synthesise sound pieces pre-recorded from professional voice actors. We notice a common difference between computer-generated songs and real singers' songs. This difference can be addressed to help the generated ones become more like the real-singer ones.
In this paper, we propose SinGlow, as a solution to minimise this difference. SinGlow is one of the Normalising Flow that directly uses the calculated Negative Log-Likelihood value to optimise the trainable parameters. This feature gives SinGlow the ability to perfectly encode inputs into feature vectors, which allows us to manipulate the feature space to minimise the difference we discussed before. To our best knowledge, we are the first to propose an application of Normalising Flow in SVS fields.
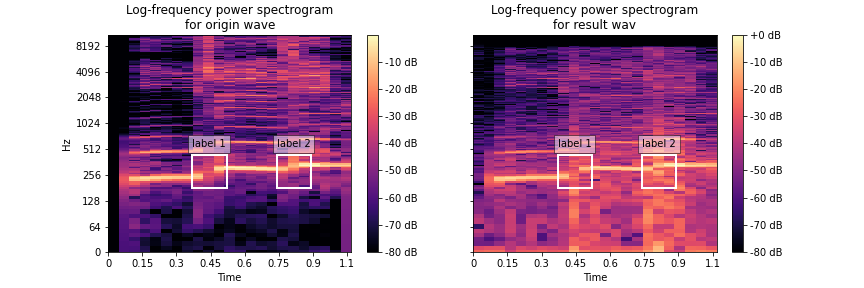
In our experiments, SinGlow shows the ability to encode sound and make the input virtual-singer songs more human-like.
Structure
SinGlow
│ train.py //need modification, replace data dirs with yours
│ common_definitions.py //model configurations are located here
│ data_loarder.py //construct tfrecord dataset from wav or mp3 data, and load it
│ model.py //Glow Model / SinGlow Model
│ pipeline.py //training pipeline
│ README.md
├───utils
│ utils.py //originate from Glow-OpenAI
│ weightnorm.py //originate from Tensorflow
├───checkpoints
│ weights.h5 //the model weights file
├───runs //outputs and rerecords
├───logs //tensorboard logdir
├───design //model architecture information
└───notebooks
run.ipynb //dataset construction and applying model
experiment.ipynb //evaluate model
README.md //some user guide
Requirements
pip3 install -r requirements.txt
Training
After every epoch, the network's weights will be stored in the checkpoints directory defined in common_definitions.py.
There are also some sampling of the network (image generation mode) that are going to be stored in results directory. Additionally, TensorBoard is used to track z's mean and variance, as well as the negative log-likelihood.
In optimal state, z should have zero mean and one variance. Additionally, the TensorBoard stores sampling with temperature of 0.7.
python3 train.py [-h] [--dataset [DATASET]] [--k_glow [K_GLOW]] [--l_glow [L_GLOW]]
[--img_size [IMG_SIZE]] [--channel_size [CHANNEL_SIZE]]
optional arguments:
-h, --help show this help message and exit
--dataset [DATASET] The dataset to train on ("mnist", "cifar10", "cifar100")
--k_glow [K_GLOW] The amount of blocks per layer
--l_glow [L_GLOW] The amount of layers
--img_size [IMG_SIZE] The width and height of the input images
--channel_size [CHANNEL_SIZE]
The channel size of the input images
CONTRIBUTING
To contribute to the project, these steps can be followed. Anyone that contributes will surely be recognized and mentioned here!
Contributions to the project are made using the "Fork & Pull" model. The typical steps would be:
- create an account on github
- fork this repository
- make a local clone
- make changes on the local copy
- commit changes
git commit -m "my message" pushto your GitHub account:git push origin- create a Pull Request (PR) from your GitHub fork (go to your fork's webpage and click on "Pull Request." You can then add a message to describe your proposal.)
LICENSE
This open-source project is licensed under MIT License.
Reference
TODO the reference information
中文注释
这是一个基于流模型的歌曲特征提取,并进行风格迁移的项目。我们一定程度上实现了将真实人声歌曲的特征迁移到虚拟歌手的歌曲上。
我们接下来的计划是继续优化模型,并在歌曲切割上取得进展,向着研究落地努力。
我们有一个堆满创意点子的秘密基地,里面有很多有意思的小伙伴。生活什么的、技术什么的、二次元什么的都可以聊得开。
欢迎加入我们的小群:兔叽的魔术工房。群内会经常发布各种各样的企划,总会遇上你感兴趣的。

 4 Dec 21, 2022
4 Dec 21, 2022
 1k Dec 26, 2022
1k Dec 26, 2022
 498 Jan 06, 2023
498 Jan 06, 2023
 671 Jan 04, 2023
671 Jan 04, 2023
 9 Jun 04, 2022
9 Jun 04, 2022
 1 Nov 22, 2021
1 Nov 22, 2021
 84 Dec 31, 2022
84 Dec 31, 2022
 16 Oct 21, 2022
16 Oct 21, 2022
 22 Sep 03, 2022
22 Sep 03, 2022
 870 Dec 27, 2022
870 Dec 27, 2022
 13 Oct 03, 2022
13 Oct 03, 2022
 2.6k Dec 30, 2022
2.6k Dec 30, 2022
 11.3k Dec 31, 2022
11.3k Dec 31, 2022
 1 Nov 19, 2021
1 Nov 19, 2021
 1 Oct 11, 2021
1 Oct 11, 2021
 1 Jun 30, 2022
1 Jun 30, 2022
 2 Dec 14, 2021
2 Dec 14, 2021
 105 Dec 26, 2022
105 Dec 26, 2022
 1 Dec 26, 2021
1 Dec 26, 2021
 51 Dec 17, 2022
51 Dec 17, 2022