当前位置:网站首页>Redis data persistence
Redis data persistence
2022-07-19 08:05:00 【Program three two lines】
One 、 summary
Redis Is a memory database , If you do not save the database state in memory to disk , So once the server process exits , Server The state of the database will disappear . therefore Redis Provides persistence !redis Provides RDB+AOF Two ways to persist
Two 、RDB
1、 summary
Write the data set snapshot in memory to disk within the specified time interval , That's what jargon says Snapshot snapshot , Recovery will be fast Read the file directly into memory
2、 principle
Redis Will create... Separately (fork) A subprocess to persist , Write the data to a temporary file first , Process to be persisted It's all over , Replace the last persistent file with this temporary file . The whole process , The main process is not going to do anything IO Operation of the . This ensures extremely high performance . If large-scale data recovery is needed , And it's not very sensitive to the integrity of data recovery , that RDB The way is better than AOF It's more efficient .RDB The disadvantage is that the data may be lost after the last persistence .
Fork Its function is to copy the same process as the current process . All the data for the new process ( Variable , environment variable , Program counter, etc ) The values are consistent with the original process , But it's a whole new process , And as a child of the original process .
3、 Location
Where to start is in that directory , The default is redis When starting, the command line is in the directory . You can modify the path address and file name of the generated file through the configuration file
4、 The interval between snapshot generation
How to configure SNAPSHOTTING
save
Redis Three conditions are provided in the default configuration file :
save 900 1
save 300 10
save 60 10000
respectively 900 second (15 minute ) There are 1 A change ,300 second (5 minute ) There are 10 Changes and 60 In seconds 10000 A change
Change .Other commands
Stop-writes-on-bgsave-error: If configured as no, It means that you don't care about data inconsistency or other means to find and control system , The default is yes.
rbdcompression: For snapshots stored on disk , You can set whether to compress storage . If so ,redis Will be used LZF Algorithm for compression , If you don't want to consume CPU To compress , It can be set to turn off this function .
rdbchecksum: After storing the snapshot , Can also let redis Use CRC64 Algorithm to check data , But doing so will add about 10% Performance consumption of , If you want to get the maximum performance improvement , You can turn it off . The default is yes.
5、 How to trigger RDB snapshot
1、 The default snapshot configuration in the configuration file , It is recommended to use one more machine as a backup , A copy of dump.rdb
2、 command save Or is it bgsave,
save Just keep it , Whatever else , All blocked
bgsave redis The snapshot operation will be performed asynchronously in the background , The snapshot can also respond to client requests .
Can pass lastsave Command gets the last time the snapshot was executed successfully .
3、 perform flushall command , There will be dump.rdb file , But it's empty , meaningless !
4、 When you exit, it will also produce dump.rdb file !
6、 Advantages and disadvantages
advantage
1、 Suitable for large-scale data recovery
2、 The requirements for data integrity and consistency are not high
shortcoming
1、 Make a backup at regular intervals , So if redis accident down If you drop it , All changes since the last snapshot will be lost
2、Fork When , The data in memory is cloned , roughly 2 Double expansion needs to be considered .
3、 ... and 、AOF
1、 summary
Log every write operation in the form of a log , take Redis All instructions executed are recorded ( Reading operation does not record ), Only additional documents are allowed But you can't rewrite the file ,redis At the beginning of startup, it will read the file and rebuild the data , In other words ,redis Restart according to the log file Execute the write instruction from front to back to complete the data recovery
Aof What is kept is appendonly.aof file
2、 To configure
appendonly no # Whether or not to append only Patterns as a means of persistence , The default is rdb Way to persist , this These methods are enough in many applications appendfilename "appendonly.aof" # appendfilename AOF File name # Here is redis aop Synchronous frequency setting appendfsync everysec # appendfsync aof Configuration of persistence policy # no Means not to execute fsync, Data synchronization to disk is guaranteed by the operating system , The fastest . # always Indicates that every write is executed fsync, To ensure data synchronization to disk . # everysec Represents one execution per second fsync, It could lead to the loss of this 1s data . No-appendfsync-on-rewrite # Can I use Appendfsync, Use default no that will do , Ensure data security Totality Auto-aof-rewrite-min-size # Set the overridden benchmark Auto-aof-rewrite-percentage # Set the overridden benchmark
3、AOF start-up / Repair / recovery
Normal recovery
start-up : Set up Yes, Modify the default appendonly no, Change it to yes There will be data aof Copy a file and save it to the corresponding directory (config get dir)
recovery : restart redis Then reload
Abnormal recovery
start-up : Set up Yes Vandalism appendonly.aof file !
Repair : redis-check-aof --fix appendonly.aof Make repairs
recovery : restart redis Then reload
4、rewrite principle
What is it?
AOF By means of document addition , The file will get bigger and bigger , To avoid this , New rewrite mechanism , When AOF File size When the set threshold is exceeded ,Redis Will start AOF The content of the file is compressed , Keep only the smallest instruction set that can recover data , Sure Use command bgrewriteaof !
Rewriting principle
AOF When files continue to grow and become too large , Meeting fork A new process to rewrite the file ( Also write temporary documents first and then rename), Traverse the data in memory of the new process , Each record has one Set sentence . rewrite aof Operation of file , Did not read old Of aof file , It's a bit like a snapshot !
Trigger mechanism
Redis It will record the last time it was rewritten AOF size , The default configuration is when AOF The file size is last rewrite The post size has been and the file is large On 64M Trigger . An expert , It's just not , Experts look at the door , The layman is watching
5、 Advantages and disadvantages
advantage :
1、 Sync per change :appendfsync always Synchronous persistence , Every time there is a data change, it will be recorded to the disk immediately , Poor performance But the data integrity is better
2、 A second synchronous : appendfsync everysec Asynchronous operations , Record every second , If it goes down in a second , There is data loss 3、 Out of sync : appendfsync no No synchronization
shortcoming :
1、 Data from the same data set ,aof Documents are much larger than rdb file , Recovery is slower than rdb.
2、Aof Operating efficiency is slower than rdb, The efficiency of synchronization strategy per second is better , Out of sync efficiency and rdb identical .
Four 、 summary
1、RDB Persistence mode can snapshot your data in a specified time interval
2、AOF Persist to record every write to the server , When the server restarts, these commands will be re executed to restore the original The data of ,AOF Command to Redis Protocol append saves each write to the end of the file ,Redis Also able to AOF Background redoing of files Write , bring AOF The size of the file should not be too large .
3、 Cache only , If you only want your data to exist when the server is running , You can also use no persistence
4、 Open two persistence methods at the same time under these circumstances , When redis It will be loaded prior to restart AOF File to restore the original data , Because in general AOF The data set saved by the file is better than RDB The data set of the file should be complete . RDB The data is not real-time , When using both, the server will only look for AOF file , Do you want to use only AOF Well ? author Is not recommended , because RDB Better for backing up databases (AOF It's not easy to backup in constant change ), A quick restart , And there won't be AOF May be latent Bug, Keep it as a means in case .
5、 Performance Suggestions
because RDB The documents are for backup purposes only , The advice is only in Slave On persistence RDB file , And as long as 15 One backup per minute is enough 了 , Only keep save 900 1 This rule .
If Enable AOF , The advantage is that in the worst case, it will only lose no more than two seconds of data , The startup script is simple load since Own AOF Just file it , The first is to bring about continuous IO, Two is AOF rewrite At the end of rewrite The process is The blocking caused by new data written to new files is almost inevitable . As long as the hard disk is licensed , We should try to minimize AOF rewrite The frequency of ,AOF Overridden base size default 64M Is too small , It can be set to 5G above , Default over original size 100% Size weight Write can be changed to the appropriate value .
If you don't Enable AOF , Only by Master-Slave Repllcation High availability can also be achieved , Can save a lot of IO, also Less rewrite The fluctuation of the system caused by . The price is if Master/Slave At the same time , It will lose more than ten minutes of data , There are also two startup scripts to compare Master/Slave Medium RDB file , Load the newer one , Microblogging is this kind of Architecture .
边栏推荐
- Precautions for MySQL statements
- Double index mechanism of redis source code analysis
- Local storage sessionstorage
- Random forest of machine learning
- 美联储降息,为何长期利好数字货币市场? 2020-03-05
- 收单外包服务商北京捷文科技以约4.8亿转让60%股份
- INSTALL_PARSE_FAILED_MANIFEST_MALFORMED
- 类型详解·自定义类型·结构体初识
- Xinlinx zynq7010 domestic replacement fmql10s400 national production arm core board + expansion board
- Jd.com's purchase intention forecast (IV)
猜你喜欢
![[day01] preface, introductory program, constant variables](/img/aa/8ebb3fd11aa054264103a6f018ce6b.png)
[day01] preface, introductory program, constant variables

RISC-V技術雜談

redis缓存雪崩、穿透、击穿

What if the user information in the website app database is leaked and tampered with

Question 114 of Li Kou: binary tree expansion linked list

FMC sub card: 8-channel 125msps sampling rate 16 bit AD acquisition sub card
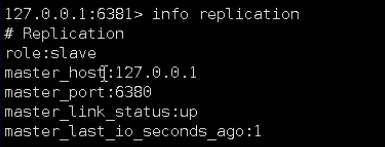
redis主从复制
【day01】前言、入门程序、常量变量

How did "leek" give money to "sickle"? 2020-03-07
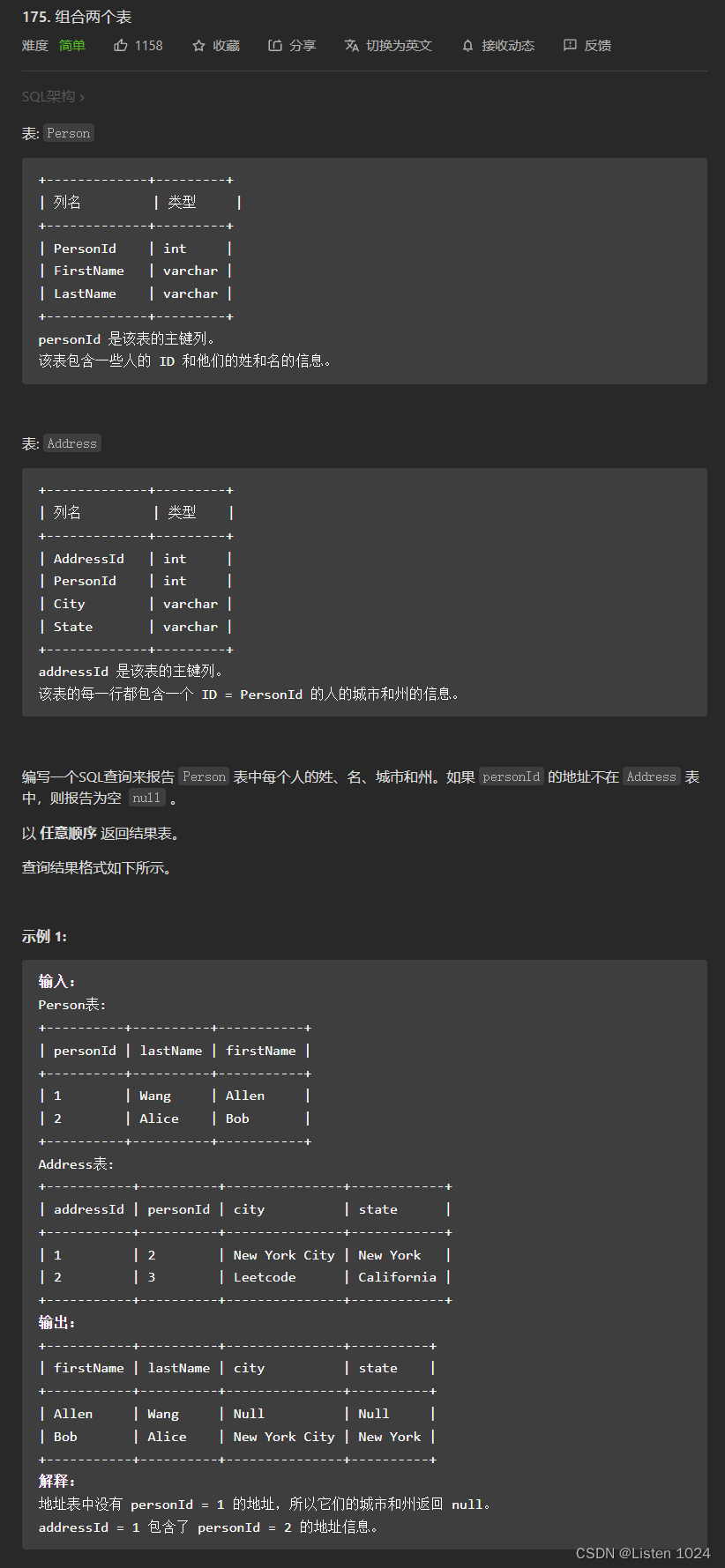
175. Combine two tables (MySQL database connection)
随机推荐
【JVM】之堆内存、逃逸分析、栈上分配、同步省略、标量替换详解
Flutter3.0(framework框架)——UI渲染
Machine learning interview questions (Reprinted)
Code learning (deamnet) CVPR | adaptive consistency prior based deep network for image learning
《牛客刷题》sql错题集
数据库复习--数据库恢复技术
[C console] - C console class
ObjectARX--自定义圆的实现
Leetcode daily question 2021/7/11-2021/7/17
Why does the Fed cut interest rates benefit the digital money market in the long run? 2020-03-05
Redis源码分析之双索引机制
Mongodb index
[C# 变量常量关键字]- C# 中的变量常量以及关键字
半导体材料技术
PCIe bus architecture high performance data preprocessing board / K7 325t FMC interface data acquisition and transmission card
Discussion on risc-v Technology
JS array intersection, subtraction and union
Convolutional neural network CNN
Niuke topic - house raiding 1, house raiding 2
175. 组合两个表(MySQL数据库连接)