当前位置:网站首页>[machine learning] evaluation index and code implementation of multi label classification
[machine learning] evaluation index and code implementation of multi label classification
2022-07-19 11:51:00 【The journey is bleak】
[1] The overview
6 The basic evaluation indicators are as follows: mind map :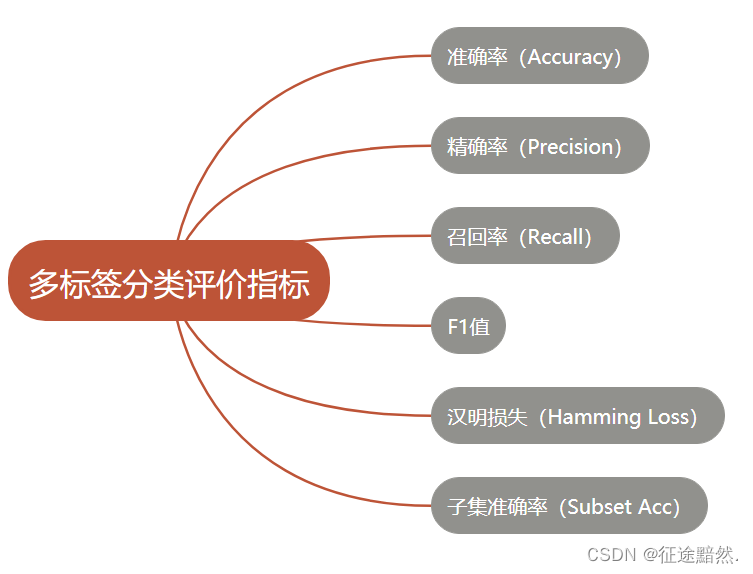
[2] Introduce
Suppose there's data : Sample size batch_size = 5, Number of tags label_num = 4.y_true For real labels ,y_pred Is the predicted tag value .
y_true = np.array([[0, 1, 0, 1],
[0, 1, 1, 0],
[0, 0, 1, 0],
[1, 1, 1, 0],
[1, 0, 1, 1]])
y_pred = np.array([[0, 1, 1, 0],
[0, 1, 1, 0],
[0, 0, 1, 0],
[0, 1, 1, 0],
[0, 1, 0, 1]])
[2.1] Subset accuracy (Subset Accuracy)
For every sample , The prediction is correct only when the predicted value is exactly the same as the real value , That is to say, as long as there is a difference in the prediction results of one category, it is considered that the prediction is not correct . therefore , Its calculation formula is :
Compare the data given above y_true、y_pred. Then only the second 2 And the first 3 It's a sample that makes the prediction right . stay sklearn in , You can go directly through sklearn.metrics Module accuracy_score Method to complete the calculation [3], Code implementation :
from sklearn.metrics import accuracy_score
print(accuracy_score(y_true,y_pred)) # 0.4
print(accuracy_score(y_true,y_pred,normalize=False)) # 2
【 notes 】
accuracy_scoreWith parametersnormalize.normalize = Falsewhen : Return the exact number of samples ,normalize = Truewhen : Return the proportion of completely correct samples .
[2.2] Accuracy rate (Accuracy)
Accuracy is the average accuracy of all samples . And for each sample , The accuracy rate is the proportion of the number of correctly predicted tags in the total number of correctly predicted or actually correct tags . Its calculation formula is :
For example, for a sample , Its real label is [0, 1, 0, 1], The prediction label is [0, 1, 1, 0]. Then the corresponding accuracy of the sample should be :(0 + 1 + 0 + 0) / (0 + 1 + 1 + 1)= 0.33.
Compare the data given above y_true、y_pred. Then the corresponding accuracy of the sample should be :
1 5 ∗ ( 1 3 + 2 2 + 1 1 + 2 3 + 1 4 ) = 0.65 \frac{1}{5} * (\frac{1}{3} + \frac{2}{2} + \frac{1}{1} + \frac{2}{3} + \frac{1}{4})= 0.65 51∗(31+22+11+32+41)=0.65
stay sklearn in ,acc Subset accuracy only , So here we need to realize by ourselves . Code implementation :
def Accuracy(y_true, y_pred):
count = 0
for i in range(y_true.shape[0]):
p = sum(np.logical_and(y_true[i], y_pred[i]))
q = sum(np.logical_or(y_true[i], y_pred[i]))
count += p / q
return count / y_true.shape[0]
print(Accuracy(y_true, y_pred)) # 0.65
[2.3] Accuracy (Precision)
The accuracy rate calculates the average accuracy rate of all samples . And for each sample , The accuracy rate is the proportion of the number of correctly predicted tags in the total number of correctly predicted tags . Its calculation formula is :
For example, for a sample , Its real label is [0, 1, 0, 1], The prediction label is [0, 1, 1, 0]. Then the accuracy of the sample should be :(0 + 1 + 0 + 0) / (1 + 1)= 0.5.
Compare the data given above y_true、y_pred. Then the corresponding accuracy of the sample should be :
1 5 ∗ ( 1 2 + 2 2 + 1 1 + 2 2 + 1 2 ) = 0.8 \frac{1}{5} * (\frac{1}{2} + \frac{2}{2} + \frac{1}{1} + \frac{2}{2} + \frac{1}{2})= 0.8 51∗(21+22+11+22+21)=0.8
Code implementation :
from sklearn.metrics import precision_score
print(precision_score(y_true=y_true, y_pred=y_pred, average='samples'))# 0.8
[2.4] Recall rate (Recall)
Recall rate is actually the average recall rate of all samples . And for each sample , Recall rate is to predict the proportion of the correct number of tags in the total number of correct tags . Its calculation formula is :

For example, for a sample , Its real label is [0, 1, 0, 1], The prediction label is [0, 1, 1, 0]. Then the accuracy of the sample should be :(0 + 1 + 0 + 0) / (1 + 1)= 0.5.
Compare the data given above y_true、y_pred. Then the corresponding accuracy of the sample should be :
1 5 ∗ ( 1 2 + 2 2 + 1 1 + 2 3 + 1 3 ) = 0.7 \frac{1}{5} * (\frac{1}{2} + \frac{2}{2} + \frac{1}{1} + \frac{2}{3} + \frac{1}{3})= 0.7 51∗(21+22+11+32+31)=0.7
Code implementation :
from sklearn.metrics import recall_score
print(recall_score(y_true=y_true, y_pred=y_pred, average='samples'))# 0.7
[2.5] F1
Its calculation formula is :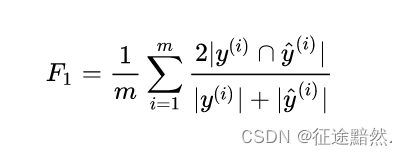
For example, for a sample , Its real label is [0, 1, 0, 1], The prediction label is [0, 1, 1, 0]. Then the accuracy of the sample should be :2 * (0 + 1 + 0 + 0) / ((1 + 1)+(1 + 1))= 0.5.
Compare the data given above y_true、y_pred. Then the corresponding accuracy of the sample should be :
2 ∗ 1 5 ∗ ( 1 4 + 2 4 + 1 2 + 2 5 + 1 5 ) = 0.74 2*\frac{1}{5} * (\frac{1}{4} + \frac{2}{4} + \frac{1}{2} + \frac{2}{5} + \frac{1}{5})= 0.74 2∗51∗(41+42+21+52+51)=0.74
Code implementation :
from sklearn.metrics import f1_score
print(f1_score(y_true,y_pred,average='samples'))# 0.74
[2.6] Hamming lost (Hamming Loss)
Hamming Loss It's measured in all samples , The proportion of mispredicted tags in the total number of tags . So for Hamming Loss In terms of losses , The smaller the value, the better the performance of the model .
Compare the data given above y_true、y_pred. Then the corresponding accuracy of the sample should be :
1 5 ∗ 4 ∗ ( 2 + 0 + 0 + 1 + 3 ) = 0.3 \frac{1}{5*4} * (2 + 0 + 0 + 1 + 3)= 0.3 5∗41∗(2+0+0+1+3)=0.3
Code implementation :
from sklearn.metrics import hamming_loss
print(hamming_loss(y_true, y_pred))# 0.3
边栏推荐
- 【无标题】cv 学习1转换
- Dream CMS foreground search SQL injection
- Resources for physics based simulation in computer graphics
- QT learning diary 17 - QT database
- [unity technology accumulation] simple timer & Co process & delay function
- 机器人开发--常用仿真软件工具
- 公网连接MySQL实例的解决方案
- Tikv memory parameter performance tuning
- 02-2. Default parameters, function overloading, reference, implicit type conversion, about error reporting
- 024.static and final use traps continued
猜你喜欢
Configure spectrum navigation for Huawei wireless devices

开发那些事儿:如何解决RK芯片视频处理编解码耗时很长的问题?

03-1、内联函数、auto关键字、typeid、nullptr

Two misunderstandings of digital transformation

Send blocking, receive blocking

Docker安装MySQL
Docker install MySQL

TCP拥塞控制详解 | 7. 超越TCP
Synchronized lock upgrade

Transport layer -------- TCP (I)
随机推荐
[wechat applet] use a thousand hand float - rollback
TS solves the problem that the type file of the imported plug-in does not exist
LeetCode_17_电话号码的字母组合
Leetcode 1304. 和为零的 N 个不同整数
02-3、指针和引用的区别
NAT technology and NAT alg
Synchronized lock upgrade
Unchangeable status quo
[unity technology accumulation] realize the mouse line drawing function &linerenderer
A simple websocket example
02-2、缺省参数、函数重载、引用、隐式类型转换、关于报错
2022 National latest fire-fighting facility operator (intermediate fire-fighting facility operator) simulation test questions and answers
【多线程】JUC详解 (Callable接口、RenntrantLock、Semaphore、CountDownLatch) 、线程安全集合类面试题
动态内存分配问题
02-3、指針和引用的區別
02-3. Difference between pointer and reference
【机器学习】多标签分类的评价指标与代码实现
项目建设,谋事在人,成事亦在人!
Will causal learning open the next generation of AI? Chapter 9 Yunji datacanvas officially released the open source project of ylarn causal learning
2022.07.14 summer training personal qualifying (IX)