当前位置:网站首页>传输层 -------- TCP(一)
传输层 -------- TCP(一)
2022-07-17 14:32:00 【GSX_MI】
目录
1.关于可靠性
(1)网络为什么存在不可靠?
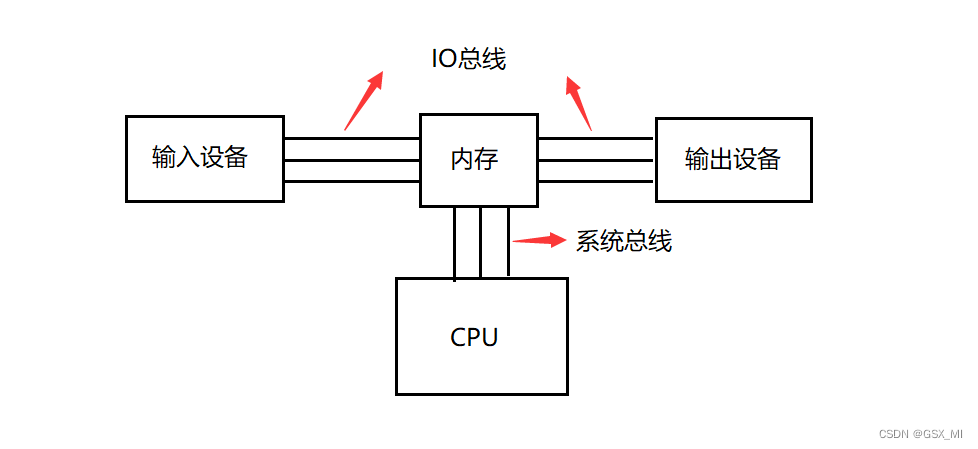
- 虽然这里的输入设备、输出设备、内存、CPU都在一台机器上,但这几个硬件设备是彼此独立的。如果它们之间要进行数据交互,就必须要想办法进行通信,因此这几个设备实际是用“线”连接起来的,其中连接内存和外设之间的“线”叫做IO总线,而连接内存和CPU之间的“线”叫做系统总线。由于这几个硬件设备都是在一台机器上的,因此这里传输数据的“线”是很短的,传输数据时出现错误的概率也非常低。
- 但如果要进行通信的各个设备相隔千里,那么连接各个设备的“线”就会变得非常长,传输数据时出现错误的概率也会大大增高,此时要保证传输到对端的数据无误,就必须引入可靠性措施来保证。
- 总之,网络中存在不可靠的根本原因就是,长距离数据传输所用的“线”太长了,数据在长距离传输过程中就可能会出现各种各样的问题,而TCP就是在此背景下诞生的,TCP就是一种保证可靠性的协议。
- 拓展: 实际单独的一台计算机可以看作成一个小型的网络,计算机上的各种硬件设备之间实际也是在进行数据通信,并且它们在通信时也必须遵守各自的通信协议,只不过它们之间的通信协议更多是描述一些数据的含义
(2)TCP有可靠性保证,为什么还要有不可靠的UDP
①不可靠和可靠是两个中性词,它们描述的都是协议的特点
- TCP协议是可靠的协议,也就意味着TCP协议需要做更多的工作来保证传输数据的可靠,并且引起不可靠的因素越多,保证可靠的成本(时间+空间)就越高。
- 比如数据在传输过程中出现了丢包、乱序、检验和失败等,这些都是不可靠的情况。
- 由于TCP要想办法解决数据传输不可靠的问题,因此TCP使用起来一定比UDP复杂,并且维护成本特别高。
- UDP协议是不可靠的协议,也就意味着UDP协议不需要考虑数据传输时可能出现的问题,因此UDP无论是使用还是维护都足够简单。
- 需要注意的是,虽然TCP复杂,但TCP的效率不一定比UDP低,TCP当中不仅有保证可靠性的机制,还有保证传输效率的各种机制。
②UDP和TCP没有谁最好,只有谁最合适,网络通信时具体采用TCP还是UDP完全取决于上层的应用场景。如果应用场景严格要求数据在传输过程中的可靠性,那么就必须采用TCP协议,如果应用场景允许数据传输出现少量丢包,那么肯定优先选择UDP协议,因为UDP协议足够简单。
2.TCP协议格式


(1)TCP报头当中各个字段的含义如下:
- 源/目的端口号:表示数据是从哪个进程来,到发送到对端主机上的哪个进程。
- 32位序号/32位确认序号:分别代表TCP报文当中每个字节数据的编号以及对对方的确认,是TCP保证可靠性的重要字段。
- 4位TCP报头长度:表示该TCP报头的长度,以4字节为单位。
- 6位保留字段:TCP报头中暂时未使用的6个比特位。
- 16位窗口大小:保证TCP可靠性机制和效率提升机制的重要字段。
- 16位检验和:由发送端填充,采用CRC校验。接收端校验不通过,则认为接收到的数据有问题。(检验和包含TCP首部+TCP数据部分)
- 16位紧急指针:标识紧急数据在报文中的偏移量,需要配合标志字段当中的URG字段统一使用。
- 选项字段:TCP报头当中允许携带额外的选项字段,最多40字节。
TCP报头当中的6位标志位:
- URG:紧急指针是否有效。
- ACK:确认序号是否有效。
- PSH:提示接收端应用程序立刻将TCP接收缓冲区当中的数据读走。
- RST:表示要求对方重新建立连接。我们把携带RST标识的报文称为复位报文段。
- SYN:表示请求与对方建立连接。我们把携带SYN标识的报文称为同步报文段。
- FIN:通知对方,本端要关闭了。我们把携带FIN标识的报文称为结束报文段。
(2)每一层协议都要解决的两个问题
①如何将报头和有效载荷分离
- TCP报头当中的4位首部长度描述的基本单位是4字节,这也恰好是报文的宽度。4为首部长度的取值范围是0000 ~ 1111,因此TCP报头最大长度为15 × 4 = 60
- 先无脑式的读取20字节,拿到4位首部长度,然后分析首部长度,如果是20,剩下的就是数据了,如果是60还要读取40字节
②交付给上层的那个协议
- TCP的报头中涵盖了目的端口号,因此TCP可以提取出报头中的目的端口号,找到对应的应用层进程,进而将有效载荷交给对应的应用层进程进行处理。
- 内核中用哈希的方式维护了端口号与进程ID之间的映射关系,因此传输层可以通过端口号快速找到其对应的进程ID,进而找到对应的应用层进程。
3.序列号和确认序号
(1)什么是真正的可靠
- 在进行网络通信时,一方发出的数据后,它不能保证该数据能够成功被对端收到,因为数据在传输过程中可能会出现各种各样的错误,只有当收到对端主机发来的响应消息后,该主机才能保证上一次发送的数据被对端可靠的收到了,才叫做真正的可靠。
- 但TCP要保证的是双方通信的可靠性,虽然此时主机A能够保证自己上一次发送的数据被主机B可靠的收到了,但主机B也需要保证自己发送给主机A的响应数据被主机A可靠的收到了。因此主机A在收到了主机B的响应消息后,还需要对该响应数据进行响应,但此时又需要保证主机A发送的响应数据的可靠性…,这样就陷入了一个死循环。
- 因为只有当一端收到对方的响应消息后,才能保证自己上一次发送的数据被对端可靠的收到了,但双方通信时总会有最新的一条消息,因此无法百分之百保证可靠性。
- 严格意义上来说,互联网通信当中是不存在百分之百的可靠性的,因为双方通信时总有最新的一条消息得不到响应。但实际没有必要保证所有消息的可靠性,我们只要保证双方通信时发送的每一个核心数据都有对应的响应就可以了。而对于一些无关紧要的数据(比如响应数据),我们没有必要保证它的可靠性。因为对端如果没有收到这个响应数据,会判定上一次发送的报文丢失了,此时对端可以将上一次发送的数据进行重传。
- 这种策略在TCP当中就叫做确认应答机制。需要注意的是,确认应答机制不是保证双方通信的全部消息的可靠性,而是只要一方收到了另一方的应答消息,就说明它上一次发送的数据被另一方可靠的收到了。
(2)32位序列号
- 如果双方在进行数据通信时,只有收到了上一次发送数据的响应才能发下一个数据,那么此时双方的通信过程就是串行的,效率可想而知。
- 因此双方在进行网络通信时,允许一方向另一方连续发送多个报文数据,只要保证发送的每个报文都有对应的响应消息就行了,此时也就能保证这些报文被对方收到了。
- 但在连续发送多个报文时,由于各个报文在进行网络传输时选择的路径可能是不一样的,因此这些报文到达对端主机的先后顺序也就可能和发送报文的顺序是不同的。但报文有序也是可靠性的一种,因此TCP报头中的32位序号的作用之一实际就是用来保证报文的有序性的。
- TCP将发送出去的每个字节数据都进行了编号,这个编号叫做序列号;谁发送 , 谁填写
- 32位序列号就是本报文段所发送的数据的第一个字节的序号。
- 例如: 发送的顺序序列号是1,101,201,各携带100字节的数据 ; 信息链路比较长中间消息可能因为路径选择问题,收到的顺序可能是201,101,1.但是我不怕,只要根据序号进行排序即可。
(3)32位确认序号
①TCP报头当中的32位确认序号是告诉对端,我当前已经收到了哪些数据,你的数据下一次应该从哪里开始发。
②例如:当主机B收到主机A发送过来的32位序号为1的报文时,由于该报文当中包含100字节的数据,因此主机B已经收到序列号为1-100的字节数据,于是主机B发给主机A的响应数据的报头当中的32位确认序号的值就会填成101。
- 一方面是告诉主机A,序列号在101之前的字节数据我已经收到了。
- 另一方面是告诉主机A,下次向我发送数据时应该从序列号为1001的字节数据开始进行发送。

注意: 响应数据与其他数据一样,也是一个完整的TCP报文,尽管该报文可能不携带有效载荷,但至少是一个TCP报头。
(4)如果中间有报文丢失怎么办
- 主机A发送了三个报文给主机B,其中每个报文的有效载荷都是100字节,这三个报文的32位序号分别是1、101、200。
- 如果这三个报文在网络传输过程中出现了丢包,最终只有序号为1和201的报文被主机B收到了,那么当主机B在对报文进行顺序重排的时候,就会发现只收到了1-100和201-300的字节数据。此时主机B在对主机A进行响应时,其响应报头当中的32位确认序号填的就是1001,告诉主机A下次向我发送数据时应该从序列号为1001的字节数据开始进行发送。
- 此时主机B在给主机A响应时,其32位确认序号不能填301,因为101-200是在301之前的,如果直接给主机A响应301,就说明序列号在301之前的字节数据全都收到了。
- 因此主机B只能给主机A响应101,当主机A收到该确认序号后就会判定序号为101的报文丢包了,此时主机A就可以选择进行数据重传。
- 因此发送端可以根据对端发来的确认序号,来判断是否某个报文可能在传输过程中丢失了。

(5)为什么要用两套序号机制?
TCP是全双工的,可能双方同时在通信,确认应答机制双方都需要
- 发送端在发送数据时,将该序号看作是32位序号。
- 接收端在对发送端发来的数据进行响应时,将该序号看作是32位确认序号。
- 但实际TCP却没有这么做,根本原因就是因为TCP是全双工的,双方可能同时想给对方发送消息。
- 双方发出的报文当中,不仅需要填充32位序号来表明自己当前发送数据的序号。
- 还需要填充32位确认序号,对对方上一次发送的数据进行确认,告诉对方下一次应该从哪一字节序号开始进行发送。
- 因此在进行TCP通信时,双方都需要有确认应答机制,此时一套序号就无法满足需求了,因此需要TCP报头当中出现了两套序号。
(6)小结
- 32位序号的作用是,保证数据的按序到达,同时这个序号也是作为对端发送报文时填充32位确认序号的根据。
- 32位确认序号的作用是,告诉对端当前已经收到的字节数据有哪些,对端下一次发送数据时应该从哪一字节序号开始进行发送。
- 序号和确认序号是确认应答机制的数据化表示,确认应答机制就是由序号和确认序号来保证的。此外,通过序号和确认序号还可以判断某个报文是否丢失。
(7)面试题:
- 为什么要有序号? 序列号解决按序到达的问题,确认号解决确认应答的问题
- 为什么有两种序号? TCP是全双工,双方可能同时在通信,双方在通信的时候不同的角色关心的序列号是不一样的。
4.窗口大小
(1)TCP的缓冲区
TCP本身是具有接收缓冲区和发送缓冲区:
- 接收缓冲区用来暂时保存接收到的数据。
- 发送缓冲区用来暂时保存还未发送的数据。
- 这两个缓冲区都是在TCP传输层内部实现的。

- TCP发送缓冲区当中的数据由上层应用应用层进行写入。当上层调用write/send这样的系统调用接口时,实际不是将数据直接发送到了网络当中,而是将数据从应用层拷贝到了TCP的发送缓冲区当中。
- TCP接收缓冲区当中的数据最终也是由应用层来读取的。当上层调用read/recv这样的系统调用接口时,实际也不是直接从网络当中读取数据,而是将数据从TCP的接收缓冲区拷贝到了应用层而已。
- 就好比调用read和write进行文件读写时,并不是直接从磁盘读取数据,也不是直接将数据写入到磁盘上,而对文件缓冲区进行的读写操作。

- 当数据写入到TCP的发送缓冲区后,对应的write/send函数就可以返回了,至于发送缓冲区当中的数据具体什么时候发,怎么发,发多少等问题实际都是由TCP决定的。
- 我们之所以称TCP为传输层控制协议,就是因为最终数据的发送和接收方式,以及传输数据时遇到的各种问题应该如何解决,都是由TCP自己决定的,用户只需要将数据拷贝到TCP的发送缓冲区,以及从TCP的接收缓冲区当中读取数据即可。
(2)TCP的发送缓冲区和接收缓冲区存在的意义
①发送缓冲区和接收缓冲区的作用:
- 数据在网络中传输时可能会出现某些错误,此时就可能要求发送端进行数据重传,因此TCP必须提供一个发送缓冲区来暂时保存发送出去的数据,以免需要进行数据重传。只有当发出去的数据被对端可靠的收到后,发送缓冲区中的这部分数据才可以被覆盖掉。
- 接收端处理数据的速度是有限的,为了保证没来得及处理的数据不会被迫丢弃,因此TCP必须提供一个接收缓冲区来暂时保存未被处理的数据,因为数据传输是需要耗费资源的,我们不能随意丢弃正确的报文。此外,TCP的数据重排也是在接收缓冲区当中进行的。
②经典的生产者消费者模型:
- 对于发送缓冲区来说,上层应用不断往发送缓冲区当中放入数据,下层网络层不断从发送缓冲区当中拿出数据准备进一步封装。此时上层应用扮演的就是生产者的角色,下层网络层扮演的就是消费者的角色,而发送缓冲区对应的就是“交易场所”。
- 对于接收缓冲区来说,上层应用不断从接收缓冲区当中拿出数据进行处理,下层网络层不断往接收缓冲区当中放入数据。此时上层应用扮演的就是消费者的角色,下层网络层扮演的就是生产者的角色,而接收缓冲区对应的就是“交易场所”。
- 因此引入发送缓冲区和接收缓冲区相当于引入了两个生产者消费者模型,该生产者消费者模型将上层应用与底层通信细节进行了解耦,此外,生产者消费者模型的引入同时也支持了并发和忙闲不均。
(3)窗口大小
①当发送端要将数据发送给对端时,本质是把自己发送缓冲区当中的数据发送到对端的接收缓冲区当中。但缓冲区是有大小的,如果接收端处理数据的速度小于发送端发送数据的速度,那么总有一个时刻接收端的接收缓冲区会被打满,这时发送端再发送数据过来就会造成数据丢包,进而引起丢包重传等一系列的连锁反应。
②因此TCP报头当中就有了16位的窗口大小,这个16位窗口大小当中填的是自身接收缓冲区中剩余空间的大小,也就是当前主机接收数据的能力。
③接收端在对发送端发来的数据进行响应时,就可以通过16位窗口大小告知发送端自己当前接收缓冲区剩余空间的大小,此时发送端就可以根据这个窗口大小字段来调整自己发送数据的速度。
④我给你发送数据;我的报文里面包含我的窗口大小,当你发送的时候心里有数了。期间还不断地ACK,通报彼此的窗口大小。TCP协议双方是对等的,你给我发消息发送的你的大小我给你发消息发送我的大小,双方就可以通过窗口大小调整发送的数据(流量控制).
- 窗口大小字段越大,说明接收端接收数据的能力越强,此时发送端可以提高发送数据的速度。
- 窗口大小字段越小,说明接收端接收数据的能力越弱,此时发送端可以减小发送数据的速度。
- 如果窗口大小的值为0,说明接收端接收缓冲区已经被打满了,此时发送端就不应该再发送数据了。
⑤理解现象:
- 在编写TCP套接字时,我们调用read/recv函数从套接字当中读取数据时,可能会因为套接字当中没有数据而被阻塞住,本质是因为TCP的接收缓冲区当中没有数据了,我们实际是阻塞在接收缓冲区当中了。
- 而我们调用write/send函数往套接字中写入数据时,可能会因为套接字已经写满而被阻塞住,本质是因为TCP的发送缓冲区已经被写满了,我们实际是阻塞在发送缓冲区当中了。
- 在生产者消费者模型当中,如果生产者生产数据时被阻塞,或消费者消费数据时被阻塞,那么一定是因为某些条件不就绪而被阻塞。
5.六个标志位
(1)为什么会有标志位
- TCP报文的种类多种多样,除了正常通信时发送的普通报文,还有建立连接时发送的请求建立连接的报文,以及断开连接时发送的断开连接的报文等等。
- 收到不同种类的报文时完美需要对应执行动作,比如正常通信的报文需要放到接收缓冲区当中等待上层应用进行读取,而建立和断开连接的报文本质不是交给用户处理的,而是需要让操作系统在TCP层执行对应的握手和挥手动作。
- 也就是说不同种类的报文对应的是不同的处理逻辑,所以我们要能够区分报文的种类。而TCP就是使用报头当中的六个标志字段来进行区分的,这六个标志位都只占用一个比特位,为0表示假,为1表示真。
(2)SYN
- 报文当中的SYN被设置为1,表明该报文是一个连接建立的请求报文。
- 只有在连接建立阶段,SYN才被设置,正常通信时SYN不会被设置。
(3)ACK
- 报文当中的ACK被设置为1,表明确认序号有效.
- 一般而言报文基本都会设置ACK,因为发送出去的数据本身就对对方发送过来的数据具有一定的确认能力,因此双方在进行数据通信时,可以顺便对对方上一次发送的数据进行响应。
(4)FIN
- 报文当中的FIN被设置为1,表明该报文是一个连接断开的请求报文。
- 只有在断开连接阶段,FIN才被设置,正常通信时FIN不会被设置。
(5)URG
- 双方在进行网络通信的时候,由于TCP是保证数据按序到达的,即便发送端将要发送的数据分成了若干个TCP报文进行发送,最终到达接收端时这些数据也都是有序的,因为TCP可以通过序号来对这些TCP报文进行顺序重排,最终就能保证数据到达对端接收缓冲区中时是有序的。
- TCP按序到达本身也是我们的目的,此时对端上层在从接收缓冲区读取数据时也必须是按顺序读取的。但是有时候发送端可能发送了一些“紧急数据”,这些数据需要让对方上层提取进行读取,此时应该怎么办呢?
- URG标志位代表的是:当前携带的报文数据当中有一些数据是需要优先被处理的,需要插队。哪些数据需要被处理呢? --(16位紧急指针)
- 这个紧急指针代表的是后续有效载荷当中的一个偏移量,偏移量所对应的那个数据是需要被处理的。
- recv函数的第四个参数flags有一个叫做MSG_OOB的选项可供设置,其中OOB是带外数据(out-of-band)的简称,带外数据就是一些比较重要的数据,因此上层如果想读取紧急数据,就可以在使用recv函数进行读取,并设置MSG_OOB选项。

- send函数的第四个参数flags也提供了一个叫做MSG_OOB的选项,上层如果想发送紧急数据,就可以使用send函数进行写入,并设置MSG_OOB选项。

- 16位紧急指针是一个偏移量,它能够从起始位置确定一个地址,但是没有结束。也就意味着,TCP的带外数据一次只能插一个字节数据。
- TCP的带外数据比较鸡肋,只能传一个字节的数据。但也符合常理,插队不能成为普遍现象,肯定要增加成本。
(6)PUSH
①报文当中的PSH被设置为1,是在告诉对方尽快将你的接收缓冲区当中的数据交付给上层。
②高低水位线
- 当使用read/recv从缓冲区当中读取数据时,如果缓冲区当中有数据read/recv函数就能够读到数据进行返回,而如果缓冲区当中没有数据,那么此时read/recv函数就会阻塞住,直到当缓冲区当中有数据时才会读取到数据进行返回。
- 实际这种说法是不太准确的,其实接收缓冲区和发送缓冲区都有一个水位线的概念。比如我们假设TCP接收缓冲区的水位线是100字节,那么只有当接收缓冲区当中有100字节时才让read/recv函数读取这100字节的数据进行返回。
- 如果接收缓冲区当中有一点数据就让read/recv函数读取返回了,此时read/recv就会频繁的进行读取和返回,进而影响读取数据的效率(在内核态和用户态之间切换也是有成本的)。
- 因此不是说接收缓冲区当中只要有数据,调用read/recv函数时就能读取到数据进行返回,而是当缓冲区当中的数据量达到一定量时才能进行读取。
③当报文当中的PSH被设置为1时,实际就是在告知对方操作系统,尽快将接收缓冲区当中的数据交付给上层,尽管接收缓冲区当中的数据还没到达所指定的水位线。这也就是为什么我们使用read/recv函数读取数据时,期望读取的字节数和实际读取的字节数是不一定吻合的。
(7)RST
- 报文当中的RST被设置为1,表示需要让对方重新建立连接。
- 在通信双方在连接未建立好的情况下,一方向另一方发数据,此时另一方发送的响应报文当中的RST标志位就会被置1,表示要求对方重新建立连接。
- 在双方建立好连接进行正常通信时,如果通信中途发现之前建立好的连接出现了异常也会要求重新建立连接。

- TCP建立链接之前要三次握手,但是三次握手不—定能建立成功!!
- 任何一个报文都可能丢,①②丢了我们不怕,因为三次握手没有完成,意味着双方没有达成链接建立的共识。最怕的是③丢,③ACK不一定被服务器收到,Client认为建立链接成功是发送ACK,ACK是否成功被接收也不可能知道,因为没有应答。Client端很难确定ACK被Server端收到,双方在建立链接共识时,Client先比Server建立共识,Client只要把ACK发出去就立马认为链接建立成功了,Server不认为链接建立成功,此时就有了信息差。这种概率特别小,永远要满足两个条件: 必须是最后一个ACK丢,众多的报文中就是这个ACK丢.
- 客户端把链接建立好就立马开始发送数据了,可是TCP进行数据通信之前要先建立链接,服务器并没有完成链接建立,ACK还没收到。服务器会认为链接还没建立怎么会给我发送数据,Server认为对方建立链接极有可能出现异常了,server会给Client一个响应,这个响应里面会包含一个字段RST,Client收到这个响应时会重新建立链接,有可能再次复盘上面的问题,但是这个概率已经极小了。
- 即便链接已经建立成功,链接出现异常Client链接崩溃,服务器向客户端发送消息时,Client就会认为很奇怪,就会给Server发送带RST的报文,这时Server收到就知道是链接异常,Server关闭链接, 等待client重新连接.
6.确认应答机制
- 确认应答机制就是由TCP报头当中的,32位序号和32位确认序号来保证的。
- 确认应答机制不是保证双方通信的全部消息的可靠性,而是通过收到对方的应答消息,来保证自己曾经发送给对方的某一条消息被对方可靠的收到了。
如何理解TCP将每个字节的数据都进行了编号?
TCP是面向字节流的,我们可以将TCP的发送缓冲区和接收缓冲区都想象成一个字符数组

- 此时上层应用拷贝到TCP发送缓冲区当中的每一个字节数据天然有了一个序号,这个序号就是字符数组的下标,只不过这个下标不是从0开始的,而是从1开始往后递增的。
- 而双方在通信时,本质就是将自己发送缓冲区当中的数据拷贝到对方的接收缓冲区当中。
- 发送方发送数据时报头当中所填的序号,实际就是发送的若干字节数据当中,首个字节数据在发送缓冲区当中对应的下标。
- 接收方接收到数据进行响应时,响应报头当中的确认序号实际就是,接收缓冲区中接收到的最后一个有效数据的下一个位置所对应的下标。
- 当发送方收到接收方的响应后,就可以从下标为确认序号的位置继续进行发送了。
7.超时重传机制
- 双方在进行网络通信时,发送方发出去的数据在一个特定的事件间隔内如果得不到对方的应答,此时发送方就会进行数据重发,这就是TCP的超时重传机制。
- 需要注意的是,TCP保证双方通信的可靠性,一部分是通过TCP的协议报头体现出来的,还有一部分是通过实现TCP的代码逻辑体现出来的。
- 比如超时重传机制实际就是发送方在发送数据后开启了一个定时器,若是在这个时间内没有收到刚才发送数据的确认应答报文,则会对该报文进行重传,这就是通过TCP的代码逻辑实现的,而在TCP报头当中是体现不出来的。
(1)丢包的两种情况
- 发送的数据报文丢失了
- 数据对方收到了,确认应答的ACK丢了
当出现丢包时,发送方是无法辨别是发送的数据报文丢失了,还是对方发来的响应报文丢失了,因为这两种情况下发送方都收不到对方发来的响应报文,此时发送方就只能进行超时重传。
(2)如果是对方的响应报文丢失而导致发送方进行超时重传,此时接收方就会再次收到一个重复的报文数据,但此时也不用担心,接收方可以根据报头当中的32位序号来判断曾经是否收到过这个报文,从而达到报文去重的目的。
(3)需要注意的是,当发送缓冲区当中的数据被发送出去后,操作系统不会立即将该数据从发送缓冲区当中删除或覆盖,而会让其保留在发送缓冲区当中,以免需要进行超时重传,直到收到该数据的响应报文后,发送缓冲区中的这部分数据才可以被删除或覆盖。
(4)超时重传的等待时间
- 超时重传的时间设置的太长,会导致丢包后对方长时间收不到对应的数据,进而影响整体重传的效率。
- 超时重传的时间设置的太短,会导致对方收到大量的重复报文,可能对方发送的响应报文还在网络中传输而并没有丢包,但此时发送方就开始进行数据重传了,并且发送大量重复报文会也是对网络资源的浪费。
因此超时重传的时间一定要是合理的,最理想的情况就是找到一个最小的时间,保证“确认应答一定能在这个时间内返回”。但这个时间的长短,是与网络环境有关的。网好的时候重传的时间可以设置的短一点,网卡的时候重传的时间可以设置的长一点,也就是说超时重传设置的等待时间一定是上下浮动的,因此这个时间不可能是固定的某个值。
TCP为了保证无论在任何环境下都能有比较高性能的通信,因此会动态计算这个最大超时时间。
- Linux中(BSD Unix和Windows也是如此),超时以500ms为一个单位进行控制,每次判定超时重发的超时时间都是500ms的整数倍。
- 如果重发一次之后,仍然得不到应答,下一次重传的等待时间就是2 × 500ms
- 如果仍然得不到应答,那么下一次重传的等待时间就是4 × 500 ms。以此类推,以指数的形式递增。
- 当累计到一定的重传次数后,TCP就会认为是网络或对端主机出现了异常,进而强转关闭连接。
8.连接管理机制
TCP是面向连接的
- TCP的各种可靠性机制实际都不是从主机到主机的,而是基于连接的,与连接是强相关的。比如一台服务器启动后可能有多个客户端前来访问,如果TCP不是基于连接的,也就意味着服务器端只有一个接收缓冲区,此时各个客户端发来的数据都会拷贝到这个接收缓冲区当中,此时这些数据就可能会互相干扰。
- 而我们在进行TCP通信之前需要先建立连接,就是因为TCP的各种可靠性保证都是基于连接的,要保证传输数据的可靠性的前提就是先建立好连接。

三次握手
(1)为什么是三次握手
- 其实理论上应该是4次握手,但是建立链接Server无条件同意,将SYN和ACK压缩起来了。
- ①1次握手,Client发一条链接就成功了和UPD没区别,那么我可以给Sever发送大量请求,Server一瞬间链接就被占满了,不合理。维护链接是有代价的
- ②2次握手,Client发送一条清求Seve就要发送ACK应答。当你进行ACK的时候即便Cient未收到ACK,发送的那一刹那Server就认为链接建立成功了,本质和一次握手没差别。
- ③1,2次握手极容易收到SYN洪水攻击! !只要Client无条件的发送SYN, Sever立马就建立链接,链接建立成功了,Server就认为有链接了,就占用了Server一点资源。洪水意味着有大量的SYN,我只要不断地给Server扔SYN,一会Server就挂掉了。
(2)三次为什么行?
- ①Tcp是全双工的,双方在进行通信之前要先把通信信道验证一下,站在你的角度既能收也能发,站在我的角度既能收也能发,此时才具备通信的前提条件。三次握手的场景中,Client和Server分别进行了发送和接收的通信信道的验证———用最小成本验证全双工
- ②在网络当中,三次握手对应三个报文,报文中任何一个都可能丢失。1 , 2个丢失我们不担心,对服务器没影响,还未成功建立链接,双方就不会为此投入大量成本(建立对应的数据结构)。三次握手时,最担心第三次丢失,Client会认为链接建立好了,Sever认为未建立链接,Server就不会为此耗费太多成本。如果四次握手建立链接时,我们不担心前三个丢包,最担心的也是最后一次。最后一个报文是Sever发的,发的在路上是有时间的,Sever一旦发送就认为链接建立好了,就要为了维护此链接耗费资源。
- ③不管是第几次握手,我们永远担心的是最后一次,只要最后一次丢了我们一定要有人背锅(因为一定要有人发送最后一次),发送最后一次的人永远认为链接时建立成功的。现在变成了你想让谁背锅? —定是让Client背锅,Server是1:.n的,意味着有大量的请求过来,一旦丢失最后一个报文成了普遍现成(网络不好什么都可能丢),对Server来讲丢失最后一个报文的概率大大增加了,因为Sever面对的是大量客户。如果锅让Server背了,最终导致Server上挂接了大量的废弃链接,这本身对Server资源是一种浪费,我们应该保护的是服务器,这个锅应该让Client背。Client背锅对Client的影响并不大,因为Cient承载的链接数最多也就是使用这个电脑的用户所发起的网络请求个数。让服务器不要出现链接建立的误判情况(只有最后收到ACK才认为建立链接成功),减少Server的资源浪费。
(3)总结两个建立连接时采用三次握手的理由:
- 三次握手是验证双方通信信道的最小次数,能够让能建立的连接尽快建立起来。
- 三次握手能够保证连接建立时的异常连接挂在客户端(风险转移)。
(4)偶数次握手我们一定不会使用,为什么必须是三次,5,7次不行吗?
三次握手是我们已经验证全双工,且减少浪费服务器资源的最小代价,如果再加几次肯定行,只不过每一次握手都要增加─次数据通信,网络本身就要在效率和成本上面考量,所以我们一定是要以最小成本做这件事情。所以我们最终选择了三次握手。
(5)三次握手仍然可能受到大量的洪水攻击,网络当中的安全性没有绝对的安全
- Client建立链接成功一定是在Sever之前的,你想让Sever挂满大量链接,你自己必须挂满大量的链接,伤敌一千自损八百。
- 一般黑客通过一些木马植入他人的笔记本,在笔记后台开个端口,这样就可以和所有人的笔记本通信,此时可以让他们的笔记本向百度只发送链接请求什么都不做。被控制的机器叫——肉机
(6)三次握手时的状态变化
- 最开始时客户端和服务器都处于CLOSED状态。
- 服务器为了能够接收客户端发来的连接请求,需要由CLOSED状态变为LISTEN状态。
- 此时客户端就可以向服务器发起三次握手了,当客户端发起第一次握手后,状态变为SYN_SENT状态。
- 处于LISTEN状态的服务器收到客户端的连接请求后,将该连接放入内核等待队列中,并向客户端发起第二次握手,此时服务器的状态变为SYN_RCVD。
- 当客户端收到服务器发来的第二次握手后, 客户端的收发信道验证完毕,紧接着向服务器发送最后一次握手,此时客户端的连接已经建立,状态变为ESTABLISHED。
- 而服务器收到客户端发来的最后一次握手后,连接也建立成功,此时服务器的状态也变成ESTABLISHED。
(7)套接字和三次握手之间的关系
- 在客户端发起连接建立请求之前,服务器需要先进入LISTEN状态,此时就需要服务器调用对应listen函数。
- 当服务器进入LISTEN状态后,客户端就可以向服务器发起三次握手了,此时客户端对应调用的就是connect函数。
- 需要注意的是,connect函数不参与底层的三次握手,connect函数的作用只是发起三次握手。当connect函数返回时,要么是底层已经成功完成了三次握手连接建立成功,要么是底层三次握手失败。
- 如果服务器端与客户端成功完成了三次握手,此时在服务器端就会建立一个连接,但这个连接在内核的等待队列当中,服务器端需要通过调用accept函数将这个建立好的连接获取上来。
- 当服务器端将建立好的连接获取上来后,双方就可以通过调用read/recv函数和write/send函数进行数据交互了。
四次挥手
(1)为什么要四次挥手?
- 由于TCP是全双工的,建立连接的时候需要建立双方的连接,断开连接时也同样如此。在断开连接时不仅要断开从客户端到服务器方向的通信信道,也要断开从服务器到客户端的通信信道,其中每两次挥手对应就是关闭一个方向的通信信道,因此断开连接时需要进行四次挥手。
- 我上面建立的链接和你在你的OS中建立的链接双方都要达成共识才能断开.Client发送断开链接请求,Server同意,这个同意指的是同意Client断开链接。
- Client断开链接意味着将自己的链接资源(结构体)释放? NO,双方把资源释放一定是基于双方把链接都先释放
- 单纯的一方断开链接指的是我不和你说话了,此时就解决了我向你通信可能性的问题。当你给我发送消息的时候,我认可断开链接。双方达成共识之后,链接资源才可能被释放掉
- 需要注意的是,四次挥手当中的第二次和第三次挥手不能合并在一起,因为第三次握手是服务器端想要与客户端断开连接时发给客户端的请求,而当服务器收到客户端断开连接的请求并响应后,服务器不一定会马上发起第三次挥手,因为服务器可能还有某些数据要发送给客户端,只有当服务器端将这些数据发送完后才会向客户端发起第三次挥手。
(2)四次挥手时的状态变化
- 在挥手前客户端和服务器都处于连接建立后的ESTABLISHED状态。
- 客户端为了与服务器断开连接主动向服务器发起连接断开请求,此时客户端的状态变为FIN_WAIT_1。
- 服务器收到客户端发来的连接断开请求后对其进行响应,此时服务器的状态变为CLOSE_WAIT。
- 当服务器没有数据需要发送给客户端的时,服务器会向客户端发起断开连接请求,等待最后一个ACK到来,此时服务器的状态变为LASE_ACK。
- 客户端收到服务器发来的第三次挥手后,会向服务器发送最后一个响应报文,此时客户端进入TIME_WAIT状态。
- 当服务器收到客户端发来的最后一个响应报文时,服务器会彻底关闭连接,变为CLOSED状态。
- 而客户端则会等待一个2MSL(Maximum Segment Lifetime,报文最大生存时间)才会进入CLOSED状态。
①当Client 把FIN扔出去立马从ESTABUSHED状态转变为 FIN_WAIT_1,此时Server收到了FIN且刚发出去ACK随即状态ESTABLSHED转变为CLOSE_WAIT。此时我们认为Client向Server的通信信道关闭了,Client不会向Server端发消息了(应用层方面),即Client把文件描述符close了
用户就没有可能把数据从用户拷贝到内核,所谓的信道关闭Client不再给Server发消息指的是应用层消息不会发了,但是通信细节ACK还会发送,所以,本质上双方的链接并没有释放。
②当Client收到Server的ACK由FIN_WAIT_1变为FIN_WAIT_2状态此时Client认为,我不想给Server发消息这件事情上Server已经同意了。可是Server可能还有数据要给Client发送,Client两次握手完毕断开链接,Server也要将他那个方向的信道关闭. Server发送FIN后立马从CLOSE_WAIT转变为LAST_ACK,当Client接收到FIN时立马从转变为TIME_WAIT状态,TIME_WAIT之后Client发送ACK,当Server收到后立马把关闭连接。
(3)CLOSE_WAIT
- 双方在进行四次挥手时,如果只有客户端调用了close函数,而服务器不调用close函数,此时服务器就会进入CLOSE_WAIT状态,而客户端则会进入到FIN_WAIT_2状态。
- 但只有完成四次挥手后连接才算真正断开,此时双方才会释放对应的连接资源。如果服务器没有主动关闭不需要的文件描述符,此时在服务器端就会存在大量处于CLOSE_WAIT状态的连接,而每个连接都会占用服务器的资源,最终就会导致服务器可用资源越来越少。
- 因此如果不及时关闭不用的文件描述符,除了会造成文件描述符泄漏以外,可能也会导致连接资源没有完全释放,这其实也是一种内存泄漏的问题。
- 因此在编写网络套接字代码时,如果发现服务器端存在大量处于CLOSE_WAIT状态的连接,此时就可以检查一下是不是服务器没有及时调用close函数关闭对应的文件描述符。
(4)TIME_WAIT
主动断开连接的一方最终一定要进入一个状态———TIME_WAIT状态,未close的一方最终一定要进入——CLOSE_WAIT状态
- 如果客户端在发出第四次挥手后立即进入CLOSED状态,但是这个ACK服务器未收到 ,此时服务器虽然进行了超时重传,但已经得不到客户端的响应了,因为客户端已经将连接关闭了。
- 服务器在经过若干次超时重发后得不到响应,最终也一定会将对应的连接关闭,但在服务器不断进行超时重传期间还需要维护这条废弃的连接,这样对服务器是非常不友好的。
- 为了避免这种情况,因此客户端在四次挥手后没有立即进入CLOSED状态,而是进入到了TIME_WAIT状态进行等待,此时要是第四次挥手的报文丢包了,客户端也能收到服务器重发的报文然后进行响应。
(5)TIME_WAIT状态存在的必要性:
①尽量保证最后一个ACK被对方收到,尽快释放server资源
- 当Client在TIME_WAIT状态,没有立即退出,在等待,等的时候并不能保证发送的ACK被对方收到。但是Client(在等的时间内)再次收到FIN时就认为自己发送的ACK对方未收到,如果并未收到FIN就认为ACK发送成功了——没有消息就是好消息
- 当没有消息并不能说明对方100%收到了我的ACK,这是个概率问题(此时网络特别差) , Server多次重传FIN Client都未收到那么Server就会强制关闭链接,就不会导致双方出现不一致的问题。当Client等的时候有可能Server已经收到ACK了,并且关闭了链接,但此时Client还在等,锅让Clilent背了,永远考虑Server。
- 实际第四次挥手丢包后,可能双方网络状态出现了问题,尽管客户端还没有关闭连接,也收不到服务器重发的连接断开请求,此时客户端TIME_WAIT等若干时间最终会关闭连接,而服务器经过多次超时重传后也会关闭连接。这种情况虽然也让服务器维持了闲置的连接,但毕竟是少数,引入TIME_WAIT状态就是争取让主动发起四次挥手的客户端维护这个成本。
②等待历史数据在网络里消散
断开链接之前可能还有数据再网络里面跑,有可能断开链接的报文先被收到就开始进入四次挥手了,但是曾经历史上的数据被阻塞在网络里还未收到。有可能数据到来的时候链接没了,这样的话就会有不太好的问题。一般TMIE_WAIT = 2MSL (一个来回) MSL:最大传送时间,
③因此TCP并不能完全保证建立连接和断开连接的可靠性,TCP保证的是建立连接之后,以及断开连接之前双方通信数据的可靠性。
(6)TIME_WAIT的等待时长是多少
- 太长会让等待方维持一个较长的时间的TIME_WAIT状态,在这个时间内等待方也需要花费成本来维护这个连接,这也是一种浪费资源的现象。
- 太短可能没有达到我们最初目的,没有保证ACK被对方较大概率收到,也没有保证数据在网络中消散,此时TIME_WAIT的意义也就没有了。
- TCP协议规定,主动关闭连接的一方在四次挥手后要处于TIME_WAIT状态,等待两个MSL(Maximum Segment Lifetime,报文最大生存时间)的时间才能进入CLOSED状态。
- MSL在RFC1122中规定为两分钟,但是各个操作系统的实现不同,比如在Centos7上默认配置的值是60s。我们可以通过cat /proc/sys/net/ipv4/tcp_fin_timeout命令来查看MSL的值。
TIME_WAIT的等待时长设置为两个MSL的原因:
- MSL是TCP报文的最大生存时间,因此TIME_WAIT状态持续存在2MSL的话,就能保证在两个传输方向上的尚未被接收或迟到的报文段都已经消失。
- 同时也是在理论上保证最后一个报文可靠到达的时间。
边栏推荐
- Category imbalance in classification tasks
- 8. Fixed income investment
- 一个报错, Uncaught TypeError: ModalFactory is not a constructor
- Leetcode 1310. 子数组异或查询
- Keras深度学习实战(14)——从零开始实现R-CNN目标检测
- What should I do if I can't see any tiles on SAP Fiori launchpad?
- Mysql优化系列之limit查询
- Conversion of unity3d model center point (source code)
- CodeForces - 587E(线性基+线段树+差分)
- The case has been solved --- no matter how to change the code from the logic of MQ consumption, it will not take effect
猜你喜欢

Delegate parents and other loaders

A fastandrobust convolutionalneuralnetwork-based defect detection model inproductqualitycontrol-阅读笔记

Environment variable configuration of win10

Conversion of unity3d model center point (source code)
如何在 RHEL 9 中更改和重置忘记的root密码
![[multithreading] detailed explanation of JUC (callable interface, renntrantlock, semaphore, countdownlatch), thread safe set interview questions](/img/3a/b0bdf66e11e66234a222d977fd933c.png)
[multithreading] detailed explanation of JUC (callable interface, renntrantlock, semaphore, countdownlatch), thread safe set interview questions

Mpu9250 ky9250 attitude, angle module and mpu9250 MPL DMA comparison

Learning outline of the column "MySQL DBA's magic road"

XSS. haozi. Me brush questions

热议:老公今年已经34周岁想读博,以后做科研,怎么办?
随机推荐
8.固定收益投资
Déléguer un chargeur tel qu'un parent
《MySQL DBA封神打怪之路》专栏学习大纲
nodeJS中promise对象对结果简便输出办法(建议使用异步终极方案 async+await)
Cmake common commands (V)
STC8H开发(十四): I2C驱动RX8025T高精度实时时钟芯片
How can enterprise telecommuting be more efficient?
Deep Learning for Generic Object Detection: A Survey-论文阅读笔记
Set the interface language of CMD command prompt window to English
动态内存分配问题
Qt--优秀开源项目
466-82(3、146、215)
【多线程】JUC详解 (Callable接口、RenntrantLock、Semaphore、CountDownLatch) 、线程安全集合类面试题
LeetCode 558. Intersection of quadtree
Robot development -- robot data summary
Similarities and differences between OA system and MES system
Introduction of database lock, shared with InnoDB, exclusive lock
Keras deep learning practice (14) -- r-cnn target detection from scratch
To build agile teams, these methods are indispensable
Powercli script performance optimization