当前位置:网站首页>Convolutional neural network (IV) - special applications: face recognition and neural style transformation
Convolutional neural network (IV) - special applications: face recognition and neural style transformation
2022-07-26 06:03:00 【997and】
This study note mainly records various records during in-depth study , Including teacher Wu Enda's video learning 、 Flower Book . The author's ability is limited , If there are errors, etc , Please contact us for modification , Thank you very much !
Convolutional neural networks ( Four )- Special applications : Face recognition and neural style conversion
- One 、 What is face recognition (What is face recognition)
- Two 、One-Shot Study (One-shot learning)
- 3、 ... and 、Siamese The Internet (Siamese network)
- Four 、Triplet Loss (Triplet Loss)
- 5、 ... and 、 Face verification and classification (Face verification and binary classification)
- 6、 ... and 、 What is neural style transfer (What is neural style transfer)
- 7、 ... and 、 What does deep convolution network learn (What are deep ConvNets learning)
- 8、 ... and 、 Cost function (Cost Function)
- Nine 、 Content cost function (Content Cost Function)
- Ten 、 Style cost function (Style Cost Function)
- 11、 ... and 、 One dimensional to three-dimensional generalization (1D and 3D generalizations of models)
The first edition 2022-07-18 first draft
One 、 What is face recognition (What is face recognition)

Face verification vs Face recognition :
verification (1 Yes 1):
1. Input picture , name /ID
2. Verify that the input image is this person
distinguish (1 For more than ) Higher error rate :
1.k Human database
2. Give an input picture
3. Identify the output ID
Two 、One-Shot Study (One-shot learning)

A study , It only needs a photo to identify this person .
Suppose the database has 4 A picture , The system recognizes this person through only one photo , If this person is no longer in the database , The system can distinguish .
1. Type the picture into CNN, adopt softmax Output 5 class ,4 People may not be , The actual effect is not good ;
2. If you join a new member , It becomes (6), At this time, it is necessary to retrain the network .
Study Similarity function :d Output the difference value of the two graphs . If the difference value is less than a certain threshold T, It is a super parameter , Predict that these two pictures are the same .
3、 ... and 、Siamese The Internet (Siamese network)
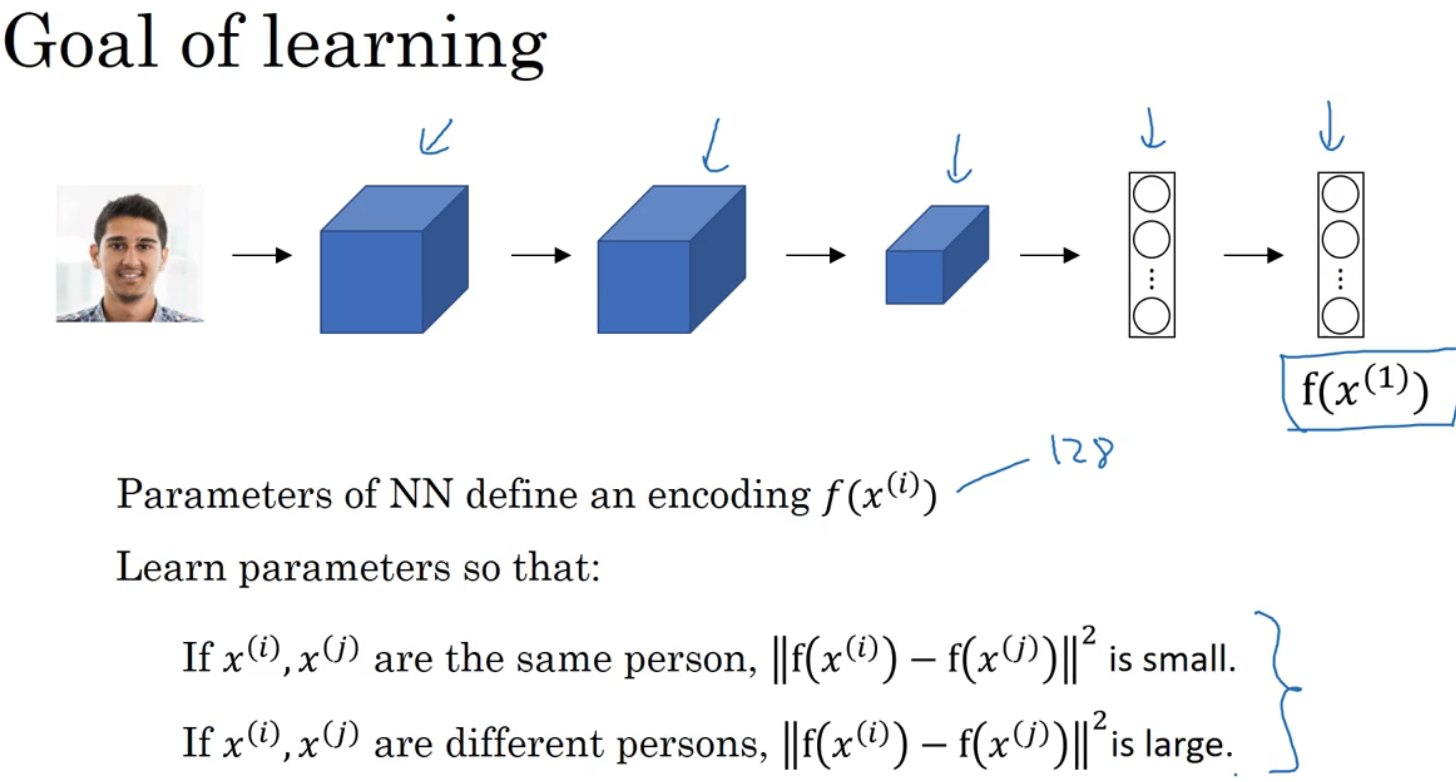
As shown in the figure, after a series of operations f(x(1)) Eigenvector of , Not this time softmax function ,f(x(1)) As an input image x(1) The coding .
If two pictures are compared , Feed the same neural network with the same parameters to the second picture , have to f(x(2)).
Definition d(x(1),x(2))=||f(x(1)-f(x(2)))||22.
The two networks have the same parameters , Just train a network , The calculated code can be used for functions d.
Four 、Triplet Loss (Triplet Loss)

Define the triple loss function and then apply gradient descent .
Compare in pairs , The first pair of the same person wants to code similar . You need to look at three photos at the same time ,Anchor picture 、Postive picture 、Negative picture . The formula is shown in figure .
Now learn everything 0, If f Always output 0. To prevent this from happening , It can't be 0, And than 0 Even smaller , Join in -a.
We hope d(A,N) Than d(A,P) Much larger , It's useless to be bigger , Want to make d(A,N) At least 0.7 Or higher . Or make the interval at least 0.2.
As shown in the figure 3 Samples , The loss function is defined as L(A,P,N).max Function is as long as the former is less than or equal to 0, The loss function is 0.
take 10000 A picture , Generate triples , Training learning algorithm , Gradient descent is used for this cost function . The training set needs 1000 A different person 10000 A picture , Average per person 10 A picture .
Random selection A、P、N, Constraints are easy to achieve . If you choose different people at random , The left side may be much larger than the right , The gap is far greater than a, The Internet can't learn anything .
So try to choose triples that are difficult to train . namely d(A,P) near d(A,N), The algorithm will try its best to make the formula on the right larger , At least one on the left and right a The interval of .
As shown in the figure, training requires multiple triples ,
5、 ... and 、 Face verification and classification (Face verification and binary classification)

Select a pair of Neural Networks , selection Siamese The Internet , Finally, it is output to the logical regression unit . Transform into a binary classification problem . You can take advantage of the differences between the codes ,yhat,f(x(i)) For pictures x(i) The coding , Subscript k Represents the... Of this vector k Elements . Divide by absolute form , It can also be the green form below , be called χ Square similarity .
Take face verification as supervised learning .
6、 ... and 、 What is neural style transfer (What is neural style transfer)

The content image uses the style of the image .
7、 ... and 、 What does deep convolution network learn (What are deep ConvNets learning)

If you train one AlexNet The Internet , Hope to see the calculation results of hidden cells between different layers .
Start with the hidden cells on the first floor , Suppose you traverse the training set , Then find some pictures that maximize the activation of the unit , Or make the picture block .
Then select another hidden cell on the first layer , Repeat the steps .
By analogy ,9 Picture blocks finally form 81 Block , Each different image block is maximized and activated .
Already on the first floor 9 A hidden unit repeats the process several times , In the deep hidden cell calculation :
The first layer is obtained from the previous first layer ; The second layer of visualization is activated to the greatest extent 9 Hidden units . This process can be repeated at a deeper level .
8、 ... and 、 Cost function (Cost Function)

Define about the newly generated picture G The cost function of J To judge the quality of a generated image , Use the gradient descent method to minimize J(G), To generate an image .
J_content Called content cost , It is used to measure the generated image G Content and content pictures C How similar are the contents of ;
J_style Called the price of style , It is used to measure the generated image G Content and style pictures S How similar are the contents of .
1. Randomly initialize the generated image G, Probably 100x100x3;
2. Minimize it using gradient descent .
Nine 、 Content cost function (Content Cost Function)

1. Use hidden layer l To calculate the cost of content ,l Very small , Foreign exchange settlement makes the generated image pixels very close to your content image . If a very deep layer , Will ask if there is a dog in the content picture , Make sure there is a dog in the generated picture ;
2. Using a pre trained convolution model ( for example VGG The Internet );
3.a[l] and a[l](g) Represents two pictures C and G Of l The activation function value of the layer 0;
4. If they are similar, the contents of the two pictures are similar .
Ten 、 Style cost function (Style Cost Function)

Pictured , Can calculate whether there are different hidden layers , You can select a certain layer ( As framed ) Define a depth measurement for the style of the image , What we need to do now is to define the style of the picture as l The correlation coefficient of the activation term between the channels in the layer .
Take out l Activation block of layer , Render different channels into different colors . For convenience of understanding 5 Channels , First look at the first two channels , Both of them contain an activation item , There are many pairs of numbers .
The correlation coefficient enables the feature to measure the frequency at which they appear simultaneously or not at the same time at each position in the picture , It can measure the similarity between the style of the generated image and the input style image .

use l Layer to measure style ,a by l Layer (i,j,k) Activation item of location .
k and k’ Used to describe k Channels and k’ Correlation coefficient between channels .
The reason to use G Express , Because this matrix is also called Gram matrix , But here we only call it style matrix .
If the two are not related ,G It will be very small .
As shown in the figure, the cost function uses the normalization constant . Also define weights for each layer λ[l]. Finally get J(G), Then gradient descent or more complex optimization algorithms find the right image G, And calculate J(G) The minimum value of .
11、 ... and 、 One dimensional to three-dimensional generalization (1D and 3D generalizations of models)

First, let's see two-dimensional convolution , You can see 14x14 Images and 5x5 The filter is convoluted , obtain 10x10 Output . Use multi-channel as shown in the figure ( The upper right ).
It can also be applied to one-dimensional data , Left KEG The signal ( It is composed of the voltage of each instant corresponding to the time series ), It's just 14 The size of the , Convolution using one-dimensional filtering , Ten dimensional data will be generated .
As shown in the figure CT scanning , The picture shows slices of different layers in the human trunk .
It can also be used 5x5x5 3D filter for ,
1
边栏推荐
- Ganglia安装部署流程
- leetcode-Array
- ERROR: Could not open requirements file: [Errno 2] No such file or directory: ‘requirments.txt’
- How can programmers improve mental internal friction?
- Widget is everything, widget introduction
- ament_cmake生成ROS2库并链接
- 解决Vagrant报错b:48:in `join‘: incompatible character encodings: GBK and UTF-8 (Encoding::Compatib
- Print linked list in reverse order
- leetcode-Array
- Why can't lpddr completely replace DDR?
猜你喜欢

Mba-day29 arithmetic - preliminary understanding of absolute value
The idea YML file code does not prompt the solution

Ros2 knowledge: DDS basic knowledge

How to divide the disks under the devices and drives in win10 new computer

The time complexity of two recursive entries in a recursive function

Day110. Shangyitong: gateway integration, hospital scheduling management: Department list, statistics based on date, scheduling details
![[MySQL from introduction to proficiency] [advanced chapter] (VI) storage engine of MySQL tables, comparison between InnoDB and MyISAM](/img/19/ca3a5710ead3c5b9a222a8ae4ecb37.png)
[MySQL from introduction to proficiency] [advanced chapter] (VI) storage engine of MySQL tables, comparison between InnoDB and MyISAM

Blurring of unity pixel painting

Unity2D 动画器无法 创建过渡

Database SQL language practice
随机推荐
[highly available MySQL solution] centos7 configures MySQL master-slave replication
Implementation of PHP multitask second timer
ETCD数据库源码分析——Cluster membership changes日志
Blurring of unity pixel painting
Mba-day28 concept of number - exercise questions
JDBC streaming query and cursor query
Select sort / insert sort / bubble sort
Rocbossphp free open source light community system
K. Link with Bracket Sequence I dp
Lemon class automatic learning after all
解决Vagrant报错b:48:in `join‘: incompatible character encodings: GBK and UTF-8 (Encoding::Compatib
VRRP protocol and experimental configuration
金仓数据库 KingbaseES SQL 语言参考手册 (9. 常见DDL子句)
Should we test the Dao layer?
JS的调用方式与执行顺序
Meiker Studio - Huawei 14 day Hongmeng equipment development practical notes 4
Redis persistence AOF
Matlab vector and matrix
Properties of binary tree~
[论文笔记] 面向网络语音隐写的抗分组丢失联合编码