当前位置:网站首页>This article takes you to graph transformers
This article takes you to graph transformers
2022-07-26 04:04:00 【kaiyuan_ sjtu】

author | Dream
Company | Zhejiang University
Research direction | Figure shows learning
Write in the front
Why is it used on the diagram Transformer?
Briefly mention GT Benefits :
1. Can capture long-distance dependencies
2. Lighten the appearance of smoothness , Over extrusion phenomenon
3. GT Can even be combined into GNN And frequency domain information (Laplacian PE), The model will be more expressive .
4. Make good use of [CLS] token, There is no need for extra use pooling function.
5. etc

Graph-Bert
Graph-Bert: Only Attention is Needed for Learning Graph Representations (arXiv 2020)
https://arxiv.org/abs/2001.05140
GNN Over reliance on the links on the graph , In addition, because the large picture consumes a lot of video memory , It may not be possible to operate directly . This paper proposes a new kind of dependency attention Graph network of mechanism Graph-BERT,Graph-BERT The input of is not the whole picture , It's a bunch of sampled subgraphs ( Without edge ). The author uses the two tasks of node attribute reconstruction and structure restoration for pre training , Then fine tune the downstream data set . This method achieves SOTA.

▲ chart 1:Graph-BERT
And before NLP Medium BERT What's different about Yang is mainly position encoding,Graph-BERT Three kinds of PE, Namely WL absolute PE,intimacy based relative PE and Hop based relative PE, Here are three PE Are all based on complete graph Calculated .
For ease of operation , The author will subgraph Sort according to the graph intimacy matrix [i, j, ...m], among S(i,j) > S(i,m), Get the result of serialization .
among Weisfeiler-Lehman Absolute Role Embedding as follows :

after WL after , Nodes with the same substructure will get the same hash code, If it is 1-WL It's kind of like degree centrality( For undirected graphs ). therefore ,WL PE You can capture global node role information .
Intimacy based Relative Positional Embedding
This PE What is captured is partial local Information about , Because the input has been sorted according to the graph intimacy matrix , Here, we just need to simply set , The closer the i The node of The smaller it gets . The mapping formula is as follows :

Hop based Relative Distance Embedding
The PE What is captured is between global and local Information between :

The nodes embedding And these PE Add up , And then type in Transformer Get in subgraph Representation of each node . because subgraph There are a lot of nodes in , The author hopes to get only target node The representation of , Therefore, the author also designed a Fusion function, In the original text, all nodes are represented average. Will be output , Select the required ones according to the downstream tasks .

Node classification effect ( no pre-training)

▲ Node classification
In general, the novelty of this paper is that it puts forward a variety of PE, And the effect on the subgraph can also reach the previous GNN Effect on the whole picture , But the experimental data set is too small , And there is no use of relatively large graph data sets , Because these data sets are small, they do not show the effect of pre training . Besides , Finally, the sub graph obtained by sampling is only carried out with the target node loss Calculation , Such utilization efficiency is too low ,inference Efficiency is also very low .

GROVER
Self-Supervised Graph Transformer on Large-Scale Molecular Data (NeurIPS 2020)
https://papers.nips.cc/paper/2020/file/94aef38441efa3380a3bed3faf1f9d5d-Paper.pdf
GNN It is widely studied in the molecular field , But there are two main problems in this field :(1) There is not so much tag data ,(2) It shows poor generalization ability on newly synthesized molecules . In order to solve these problems , This paper designs node-,edge-,graph-level The task of self-monitoring , It is hoped that the rich semantic and structural information in molecules can be captured from a large number of unlabeled data . The author trained a 100M Parameter quantity GNN, Then proceed according to the downstream tasks fine-tuning, stay 11 All data sets have reached SOTA( The average increase is more than 6 A little bit ).
The model structure is as follows :

▲ chart
because message passing The process of can capture the local structure information in the graph , So pass the data first GNN obtain Q,K,V, Each node can be characterized local subgraph structure Information about . then , These representations pass self-attention You can capture global Information about . In order to prevent message passing appear over-smoothing The phenomenon , This paper turns the residual link into long-range residual connection, Connect the original features directly to the back .
Besides , because GNN The number of layers directly affects the receptive field , This will affect message passing model The generalization of . Because different types of datasets may be needed GNN The number of layers is different , Define in advance GNN The number of layers may affect the performance of the model . The author randomly selects the number of layers during training , Random selection Jumping MPNN, among perhaps . such MPNN be called Dynamic Message Passing networks(dyMPN), Experiments show that this structure will be better than ordinary MPNN good .
Preliminary training :
There are two main self-monitoring tasks used in this paper :
1. Contextual property prediction(node/edge level task)

▲ Contextual property prediction
A good node-level Self monitoring tasks should satisfy two properties :(1) The prediction goal is credible and easy to get (2) The prediction target should reflect the context information of the node or edge . Based on these properties , The author designs a self-monitoring task based on nodes and edges ( adopt subgraph To predict the target node / The context sensitive nature of edges )

▲ Example
For example , Given a target node C atom , We first get its k-hop Neighbors as subgraph, When k=1,N and O Atoms will be included as well as single and double bonds . Then we start from this subgraph Extract statistical features from (statistical properties), Our accountant counted out for center node(node-edge)pairs The co-occurrence times of , Can be expressed as node-edge-counts, be-all node-edge counts terms In alphabetical order , In this case , We can get C_N-DOUBLE1_O-SINGLE1. This step can be regarded as a clustering process : According to the extracted features ,subgraphs Can be clustered , A feature (property) Corresponding to a cluster of subgraphs with the same statistical properties .
Through this with context-aware property The definition of , The global property prediction task can be divided into the following processes :
Enter a molecular diagram , adopt GROVER encoder We can get atoms and edges embeddings, Randomly select atoms ( its embedding by ). We are not predicting atoms Categories , But hope Be able to code node Some contextual information around (contextual information), The way to achieve this is to Input to a very simple model( One layer full connection ), Then use its output to predict nodes The context property of (contextual properties), This prediction is a multi-class classification( One category corresponds to one contextual property).
2. Graph-level motif prediction

▲ Graph-level motif prediction
Graph-level The self-monitoring task of also needs credible and cheap labels ,motifs yes input graph data Frequent sub-graphs. A kind of important motifs It's a functional group , It encodes a wealth of domain knowledge of molecules , And can be detected by professional software (e.g. RDKit). therefore , We can motif prediction task Formulation becomes a multi classification problem , every last motif Corresponding to one label. Suppose the molecular data set exists p individual motifs , For a specific molecule , We use RDKit Detect whether there is motif, Then build it as motif prediction task The goal of .
Fine tune for downstream tasks :
Complete on massive unmarked data pre-training after , We got a high-quality molecule encoder, For specific downstream tasks (e.g. node classification, link prediction, the property prediction for molecules, etc), We need to fine tune the model , in the light of graph-level Downstream tasks of , We need an extra readout Function to get the representation of the whole graph (node-level and edge-level There is no need to readout Function ), And then one after another MLP To classify .
experiment :
notes : Green means pre-training
The performance improvement is quite obvious .


Graph Transformer Architecture
A Generalization of Transformer Networks to Graphs (DLG-AAAI 2021)
https://arxiv.org/abs/2012.09699

▲ Model structure
It is mainly proposed to use Laplacian eigenvector As PE, Than GraphBERT Used in PE good .

▲ Different PE Comparison of effects
But the effect of this model is self-attention Focus on the neighbors It will be better when , Is not so much graph transformer, It's better to say with PE Of GAT.Sparse graph refer to self-attention Only neighbor nodes are calculated ,full graph Refer to self-attention All nodes in the diagram will be considered .

▲ experimental result

GraphiT
GraphiT: Encoding Graph Structure in Transformers (arXiv 2021)
https://arxiv.org/abs/2106.05667
The work shows that , Combine structure and location information into transformer in , Can be better than the existing classics GNN.GraphiT(1) Use the relative position coding based on the kernel function on the graph to influence attention scores,(2) And encode local sub-structures Make use of . Realize discovery , Whether this method is used alone , Or combined use has achieved good results .
(i) leveraging relative positional encoding strategies in self-attention scores based on positive definite kernels on graphs, and (ii) enumerating and encoding local sub-structures such as paths of short length
Before GT Find out self-attention Only pay attention to neighboring nodes Will achieve better results , But when you focus on all nodes , Performance is not good . This paper finds that transformer with global communication It can also achieve good results . therefore ,GraphiT Through some strategies local graph structure Code into the model ,(1) A relative position coding strategy based on the weighted attention score of positive definite kernel (2) By using graph convolution kernel networks(GCKN) take small sub-structure(e.g.,paths perhaps subtree patterns) Code it out as transformer The input of .
Transformer Architectures
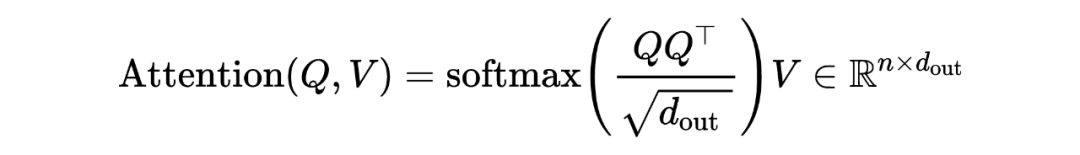

Encoding Node Positions
Relative Position Encoding Strategies by Using Kernels on Graphs

Encoding Topological Structures
Graph convolutional kernel networks(GCKN)

experimental result

▲ experimental result

GraphTrans
Representing Long-Range Context for Graph Neural Networks with Global Attention (NeurIPS 2021)
https://arxiv.org/abs/2201.08821
This paper puts forward GraphTrans, In standard GNN Add T ransformer. A new readout Mechanism ( In fact, that is NLP Medium [CLS] token). For graphs , in the light of target node The best aggregation is permutation-invariant, But add PE Of transformer It may not be possible to achieve this , So do not use PE It's quite natural on the picture .
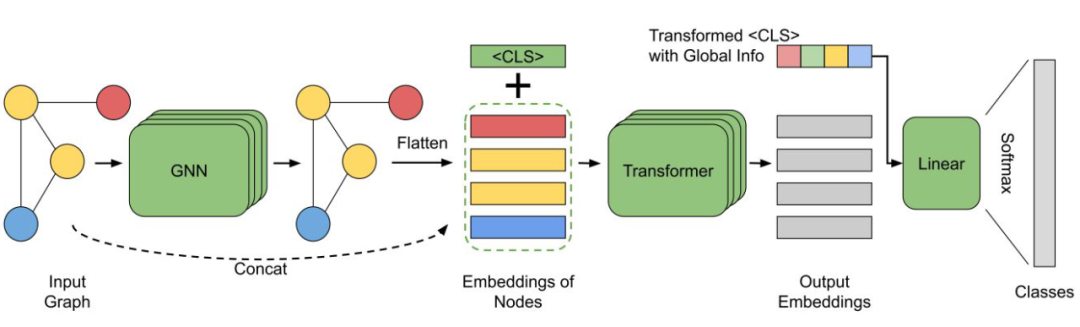
▲ pipeline
Interpretable observation
[CLS]token yes 18, You can find it and others node Interaction is frequent . It may be able to extract more general Information about .
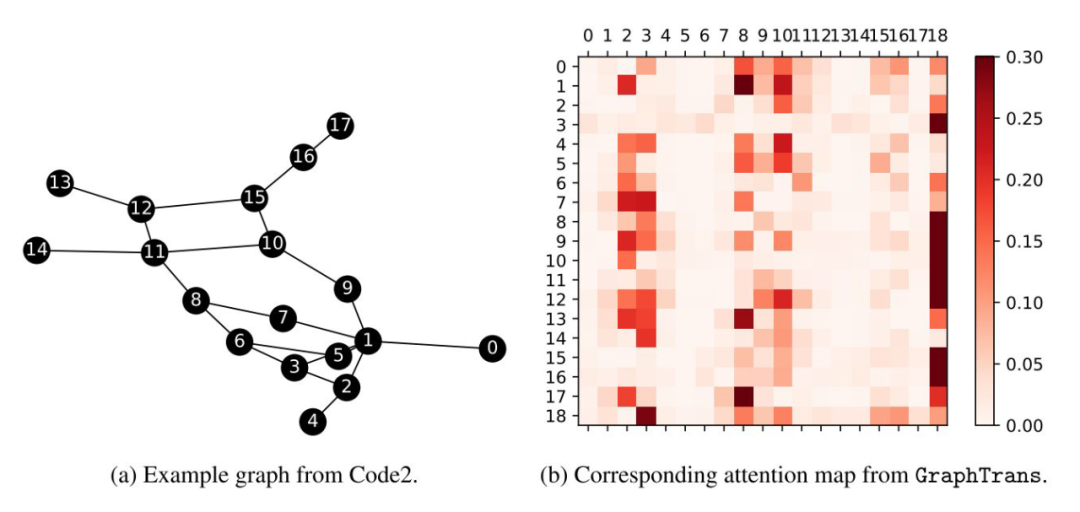
Although the method of this paper is very simple , But a lot of experiments have been done , It's not bad either .
NCI biological datasets
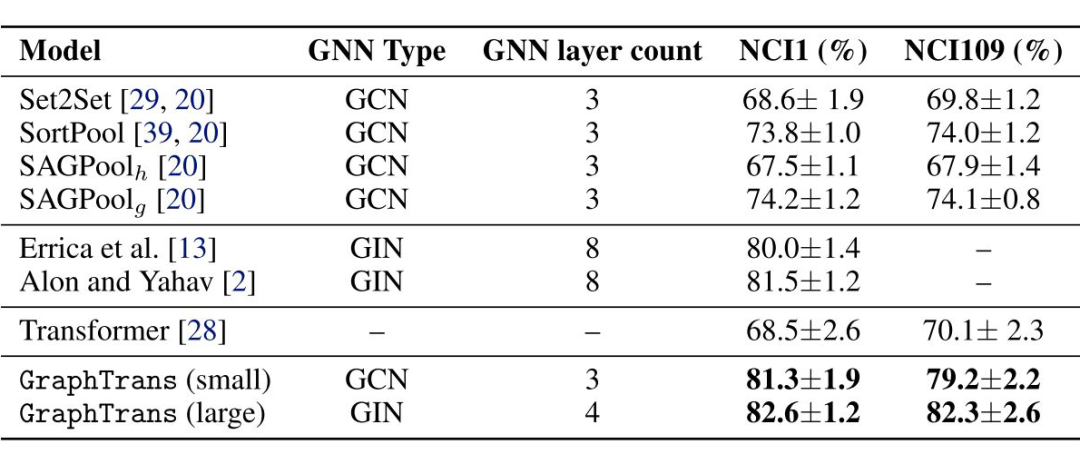
▲ NCI biological datasets
OpenGraphBenchmark Molpcba dataset

▲ Molpcba dataset
OpenGraphBenchmark Code2 dataset

▲ Code2 dataset

SAN
Rethinking Graph Transformers with Spectral Attention (NeurIPS 2021)
https://arxiv.org/abs/2106.03893
This paper uses learnable PE, Yes, why laplacian PE It makes a better explanation effectively ,


Graphormer
Do Transformers Really Perform Bad for Graph Representation? (NeurIPS 2021)
https://arxiv.org/abs/2106.05234
The original author interpreted it himself :
https://www.msra.cn/zh-cn/news/features/ogb-lsc
The core point is to use structural information to attention score Amendment , This makes better use of the structural information of the graph .

SAT
Structure-Aware Transformer for Graph Representation Learning (ICML 2022)
https://arxiv.org/abs/2202.03036
This paper and GraphTrans similar . First pass GNN Get a new node representation , And then type it into GT in . Only this paper defines the way of extracting structural information more abstractly ( But for convenience , Still using GNN). Another difference is that this paper also uses PE(RWPE).
In this paper , The author shows the use of location coding Transformer The generated node representation does not necessarily capture the structural similarity between nodes . To solve this problem ,Chen et al. Put forward a kind of structure-aware transformer, This is a new self-attention Mechanism transformer. This new self-attention In the calculation attention Before, we will extract the representation of the subgraph (rooted at each node), In this way, structural information is integrated .
The author proposes several methods that can be automatically generated subgraph representation Methods , It is theoretically proved that these characterizations are at least as good as subgraph representations Same expressive force . The structure-aware The framework can take advantage of existing GNN To extract subgraph representation, The performance improvement and GNN Have a greater relationship . Only on Transformer Using absolute position coding will show too loose structural induction bias , This does not guarantee that two nodes with similar local structures generate similar node representations .


GraphGPS
Recipe for a General, Powerful, Scalable Graph Transformer (NeurIPS 2022 Under Review)
https://arxiv.org/abs/2205.12454
In this paper , The author is concerned about the PE Carefully classified (local,global or relative, See the table below for details ). Besides , The paper also proposes the construction General,Powerful,Scalable Graph Transformer There are three elements :(1)positional/structural encoding,(2)local message-passing mechanism,(3)global attention mechanism. For these three elements , The author designed a new graph transformer.

in the light of layer The design of the , This paper adopts GPSlayer = a hybrid MPNN+Transformer layer.

The design and GraphTrans The difference is ,GraphTrans In the input to Transformer Before that, input to a that contains several layers MPNNs in , There may be over-smoothing,over-squashing as well as low expressivity against the WL test The problem of , In other words, these layers may not be able to save some information at an early stage , Input to transfomer There will be a lack of information .GPS The design of is that every floor is a floor MPNN+transformer layer, Then stack repeatedly L layer .

The specific calculation is as follows :



utilize Linear transformer,GPS You can reduce the time complexity to .
experimental result
1. Use different Transformer,MPNN: You can find that you don't use MPNN Drop a lot , Use Transformer Can bring performance improvements .

▲ Ablation Experiment : Use different transformer,MPNN
2. Use different PE/SE: At low computing costs , Use RWSE It works best . If you don't mind the computational overhead, you can use a better .

▲ Ablation Experiment : Use different PE\SE
3. Benchmarking GPS
3.1 Benchmarking GNNs

3.2 Open Graph Benchmark

▲ Open Graph Benchmark
3.3 OGB-LSC PCQM4Mv2

Method summary
notes : This article mainly summarizes graph transformers, At present, there are also some heterogeneous maps graph transformers The job of , Interested readers check it by themselves .
Different in the picture transformers The main difference is (1) How to design PE,(2) How to use structural information ( combination GNN Or use structural information to correct attention score, etc).
The existing methods are basically aimed at small graphs( Up to hundreds of nodes ),Graph-BERT Although for node classification tasks , But first it will pass sampling Get the subgraph , This can damage performance ( Than GAT Many more parameters , But the performance is similar ), Can we design a kind of transformer It is still a difficult problem .

▲ The difference between each method
Communicate together
I want to learn and progress with you !『NewBeeNLP』 At present, many communication groups in different directions have been established ( machine learning / Deep learning / natural language processing / Search recommendations / Figure network / Interview communication / etc. ), Quota co., LTD. , Quickly add the wechat below to join the discussion and exchange !( Pay attention to it o want Notes Can pass )


reference
[1] GRAPH-BERT: Only Attention is Needed for Learning Graph Representations:https://github.com/jwzhanggy/Graph-Bert
[2] (GROVER) Self-Supervised Graph Transformer on Large-Scale Molecular Data:https://github.com/tencent-ailab/grover
[3] (GT) A Generalization of Transformer Networks to Graphs:https://github.com/graphdeeplearning/graphtransformer
[4] GraphiT: Encoding Graph Structure in Transformers [Code is unavailable]
[5] (GraphTrans) Representing Long-Range Context for Graph Neural Networks with Global Attention:https://github.com/ucbrise/graphtrans
[6] (SAN) Rethinking Graph Transformers with Spectral Attention [Code is unavailable]
[7] (Graphormer) Do Transformers Really Perform Bad for Graph Representation?:https://github.com/microsoft/Graphormer
[8] (SAT) Structure-Aware Transformer for Graph Representation Learning [Code is unavailable]
[9] (GraphGPS) Recipe for a General, Powerful, Scalable Graph Transformer:https://github.com/rampasek/GraphGPS
Other information
[1] Graph Transformer review :https://arxiv.org/abs/2202.08455 [ Code]
[2] Tutorial: [Arxiv 2022,06] A Bird's-Eye Tutorial of Graph Attention Architectures:https://arxiv.org/pdf/2206.02849.pdf
[3] Dataset: [Arxiv 2022,06]Long Range Graph Benchmark [ Code]:https://arxiv.org/pdf/2206.08164.pdf
brief introduction :GNN Generally, you can only capture k-hop Neighbors of , And may not be able to capture long-distance dependency information ,Transformer Can solve this problem . The benmark There are five data sets (PascalVOC-SP, COCO-SP, PCQM-Contact, Peptides-func and Peptides-struct), The model needs to be able to capture long-distance dependencies in order to achieve better results , This data set is mainly used to verify the model capture long range interactions The ability of .
There are also some homogeneous graphs Graph Transformers The job of , Interested students read by themselves :
[1] [KDD 2022] Global Self-Attention as a Replacement for Graph Convolution:https://arxiv.org/pdf/2108.03348.pdf
[2] [ICOMV 2022] Experimental analysis of position embedding in graph transformer networks:https://www.spiedigitallibrary.org/conference-proceedings-of-spie/12173/121731O/Experimental-analysis-of-position-embedding-in-graph-transformer-networks/10.1117/12.2634427.short
[3] [ICLR Workshop MLDD] GRPE: Relative Positional Encoding for Graph Transformer [Code]:https://arxiv.org/abs/2201.12787
[4] [Arxiv 2022,05] Your Transformer May Not be as Powerful as You Expect [Code]:https://arxiv.org/pdf/2205.13401.pdf
[5] [Arxiv 2022,06] NAGphormer: Neighborhood Aggregation Graph Transformer for Node Classification in Large Graphs:https://arxiv.org/abs/2206.04910

边栏推荐
- 2.9.4 Boolean object type processing and convenient methods of ext JS
- 构建关系抽取的动词源
- 在 Istio 服务网格内连接外部 MySQL 数据库
- WAF details
- Summary of senior report development experience: understand this and do not make bad reports
- 按键消抖的Verilog实现
- Kbpc1510-asemi large chip 15A rectifier bridge kbpc1510
- Worked overtime for a week to develop a reporting system. This low code free it reporting artifact is very easy to use
- Pits encountered by sdl2 OpenGL
- firewall 命令简单操作
猜你喜欢

WAF details

ZK snark: about private key, ring signature, zkksp

Analysis on the infectious problem of open source license

ASEMI整流桥GBU1510参数,GBU1510规格,GBU1510封装

Can't the container run? The Internet doesn't have to carry the blame
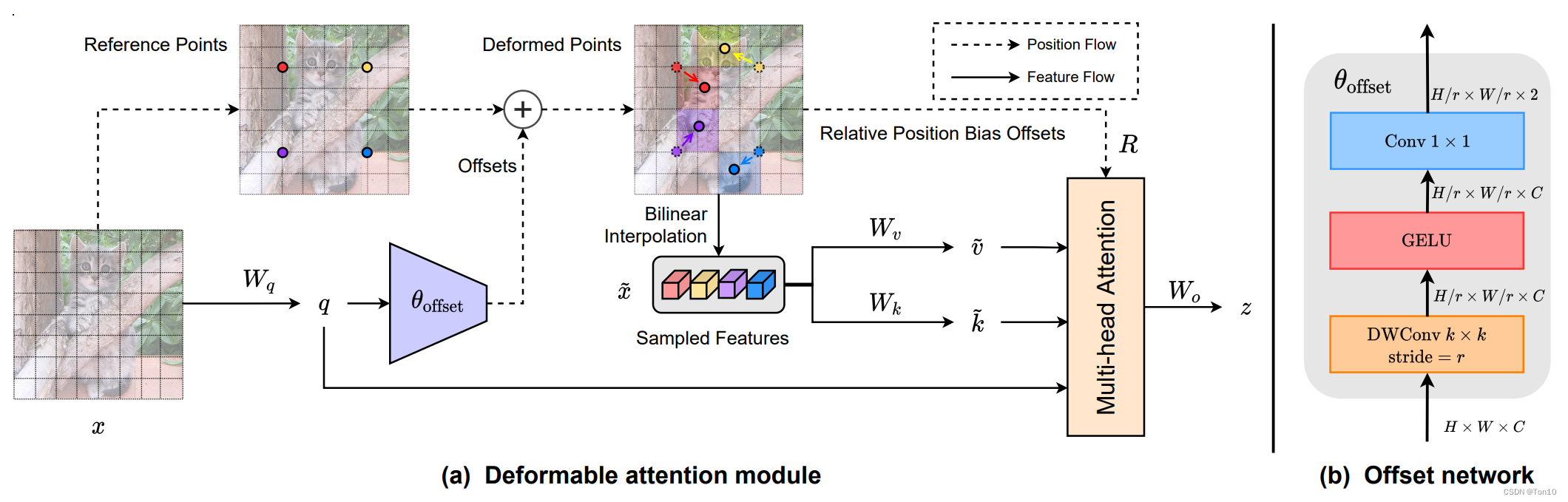
Dat of deep learning

Luoda development - audio stream processing - AAC / loopbacktest as an example

1311_硬件设计_ICT概念、应用以及优缺点学习小结
Summary of senior report development experience: understand this and do not make bad reports
Asemi rectifier bridge gbu1510 parameters, gbu1510 specifications, gbu1510 package
随机推荐
按键消抖的Verilog实现
Wechat applet realizes music player (5)
Basic principles of iptables
Save the image with gaussdb (for redis), and the recommended business can easily reduce the cost by 60%
UFS Clk Gate介绍
Working ideas of stability and high availability guarantee
Moco V2: further upgrade of Moco series
redux
How to build an enterprise level OLAP data engine for massive data and high real-time requirements?
Implementation of distributed lock
2.9.4 Ext JS的布尔对象类型处理及便捷方法
资深报表开发经验总结:明白这一点,没有做不好的报表
If you want to do a good job in software testing, you can first understand ast, SCA and penetration testing
STM32 state machine programming example - full automatic washing machine (Part 2)
2021 CIKM |GF-VAE: A Flow-based Variational Autoencoder for Molecule Generation
2022 Hangzhou Electric Multi school bowcraft
Maximum average value of continuous interval
(翻译)网站流程图和用户流程图的使用时机
Course selection information management system based on SSM
[Reading Notes - > data analysis] Introduction to BDA textbook data analysis