当前位置:网站首页>7. Data warehouse environment preparation for data warehouse construction
7. Data warehouse environment preparation for data warehouse construction
2022-07-19 05:34:00 【Mmj666】
Data warehouse environment preparation for data warehouse construction
1.Hive Installation and deployment
(1) We first need to apache-hive-3.1.2-bin.tar.gz Upload to linux Of **/opt/software** Under the table of contents
(2) decompression apache-hive-3.1.2-bin.tar.gz To **/opt/module/** Below directory
[[email protected] software]$ tar -zxvf /opt/software/apache-hive-3.1.2-bin.tar.gz -C /opt/module/
(3) modify apache-hive-3.1.2-bin.tar.gz For the name of the hive
[[email protected] software]$ mv /opt/module/apache-hive-3.1.2-bin/ /opt/module/hive
(4) modify /etc/profile.d/my_env.sh, Add environment variables
[[email protected] software]$ sudo vim /etc/profile.d/my_env.sh
The specific additions are as follows :
#HIVE_HOME
export HIVE_HOME=/opt/module/hive
export PATH=$PATH:$HIVE_HOME/bin
Use source /etc/profile.d/my_env.sh, Enable environment variables
[[email protected] software]$ source /etc/profile.d/my_env.sh
(5) Resolution log Jar Packet collision , Get into /opt/module/hive/lib Catalog
[[email protected] lib]$ mv log4j-slf4j-impl-2.10.0.jar log4j-slf4j-impl-2.10.0.jar.bak
2.Hive Metadata configuration to Mysql
2.1 Why use Mysql As a metabase without Derby Well ?
Hive The default metabase makes Derby.Apache Derby It's very small , The core part of the derby.jar Only 2M, So it can be used as a separate database server , It can also be embedded in applications . therefore hive Adopted Derby As an embedded metabase , Can finish hive Simple test of installation .
hive After installation , You can go to hive shell Perform some basic operations in , Create table 、 Queries, etc. . But there will be an obvious problem :
When starting the terminal under a certain directory , Get into hive shell when ,hive By default, it will be generated in the current directory One derby file and One metastore_db Catalog , These two files are mainly saved in shell Some of the operations in sql Result , For example, a new table 、 Added partitions, etc
This storage method brings disadvantages
1. There can only be one in the same directory at the same time hive The client can use the database
2. Switch directories to start a new shell, Cannot view the previously created table , Cannot realize the sharing of table data
There are some drawbacks in using the default metabase , So using mysql preservation hive Metadata solves the above problem .hive All metadata is stored in the same database , In this way, the tables created by different developers can be shared .
2.2Hive Metadata configuration to Mysql
(1) First , We need to copy Mysql Of JDBC Drive to Hive Of lib Under the table of contents
[[email protected] lib]$ cp /opt/software/mysql-connector-java-5.1.27.jar /opt/module/hive/lib/
(2) To configure MySQL Store as metadata . We are /opt/module/hive/conf New under the directory hive-site.xml file
[[email protected] conf]$ vim hive-site.xml
We ask hive-site.xml To add the following :
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>******</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop102</value>
</property>
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
</configuration>
3. start-up HIve
3.1 Initialize metabase
(1) Sign in Mysql
[[email protected] conf]$ mysql -uroot -p123456
(2) newly build Hive Meta database
mysql> create database metastore;
mysql> quit;
(3) initialization Hive Meta database
[[email protected] conf]$ schematool -initSchema -dbType mysql -verbose
3.2 start-up Hive Client side test
(1) Use bin/hive start-up Hive Client side test
[[email protected] hive]$ bin/hive
(2) view the database
hive (default)> show databases;
4. Modify metabase character set
Hive The character set of the metabase defaults to Latin1, Because it does not support Chinese characters , Therefore, if the table creation statement contains Chinese Notes , There will be garbled code . If you need to solve the problem of garbled code , The following modifications must be made .
modify Hive The character set of the field storing comments in the metabase is utf-8:
(1) Annotation fields
mysql> alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
(2) Table annotation
mysql> alter table TABLE_PARAMS modify column PARAM_VALUE mediumtext character set utf8;
After the modification hive-site.xml in JDBC URL, As shown below :
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false&useUnicode=true&characterEncoding=UTF-8</value>
</property>
5.Hive on Spark To configure
Hive Our engine includes MR( Default )、tez as well as spark.
5.1Hive on Spark and Spark on Hive Compare
Hive on Spark:Hive Both as storage metadata and responsible for SQL Analysis optimization of , Grammar is HQL grammar , The execution engine becomes Spark,Spark Responsible for adopting RDD perform .
Spark on Hive : Hive Only as storage metadata ,Spark be responsible for SQL Analytic optimization , Grammar is Spark SQL grammar ,Spark Responsible for adopting RDD perform .
The running speed of the two is not much different .
5.2Hive on Spark To configure
(1) Compatibility issues encountered
Download it on the official website Hive3.1.2 and Spark3.0.0 The default is incompatible . because Hive3.1.2 Supported by Spark The version is 2.4.5, So we need to recompile Hive3.1.2 edition .
The compilation steps are as follows :
1. Download from the official website Hive3.1.2 Source code , modify pom Referenced in file Spark Version is 3.0.0.
2. After compilation , Package directly to get jar package .
(2) stay Hive Deploy on the node Spark
Upload and unzip spark-3.0.0-bin-hadoop3.2.tgz
[[email protected] software]$ tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module/
modify spark-3.0.0-bin-hadoop3.2 by spark
[[email protected] module]$ mv /opt/module/spark-3.0.0-bin-hadoop3.2 /opt/module/spark
(3) To configure SPARK_HOME environment variable , stay /etc/profile.d/my_env.sh To add the following :
# SPARK_HOME
export SPARK_HOME=/opt/module/spark
export PATH=$PATH:$SPARK_HOME/bin
adopt source Make the document effective
[[email protected] module]$ source /etc/profile.d/my_env.sh
(4) stay hive Created in spark The configuration file
[[email protected] module]$ vim /opt/module/hive/conf/spark-defaults.conf
We add the following content to the configuration file , stay spark When performing tasks , It will be executed according to the following parameters
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop102:8020/spark-history
spark.executor.memory 1g
spark.driver.memory 1g
We are HDFS Create a path , Store historical logs
[[email protected] /]$ hadoop fs -mkdir /spark-history
(5) towards HDFS Upload Spark Pure version jar package
because Spark3.0.0 By default, the non pure version supports hive2.3.7 edition , Direct use and installation Hive3.1.2 There are compatibility issues . So using Spark Pure version jar package , It doesn't contain hadoop and hive Related dependencies , To avoid conflict .
Why upload to HDFS How about it ?
Hive The task is ultimately done by Spark To execute ,Spark Task resources are allocated by Yarn To dispatch , The task may be assigned to any node of the cluster . So we need to Spark Upload your dependencies to HDFS Cluster path , In this way, any node in the cluster can get .
1. Upload and unzip spark-3.0.0-bin-without-hadoop.tgz
[[email protected] software]$ tar -zxvf /opt/software/spark-3.0.0-bin-without-hadoop.tgz
2. Upload Spark Pure version jar Package to HDFS
[[email protected] software]$ hadoop fs -mkdir /spark-jars
[[email protected] software]$ hadoop fs -put spark-3.0.0-bin-without-hadoop/jars/* /spark-jars
(6) modify hive-site.xml file , stay /opt/module/hive/conf/hive-site.xml To add the following
<!--Spark Dependent location ( Be careful : Port number 8020 It has to be with namenode The port numbers are the same )-->
<property>
<name>spark.yarn.jars</name>
<value>hdfs://hadoop102:8020/spark-jars/*</value>
</property>
<!--Hive Execution engine -->
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
6.Hive on Spark test
(1) start-up hive client
[[email protected] hive]$ bin/hive

(2) Create a test table
hive (default)> create table student(id int, name string);
(3) adopt insert The test results
hive (default)> insert into table student values(1,'abc');

8. Data warehouse development environment DataGrip To configure
The data warehouse development tool we choose for this project is DataGrip, As a college student , Therefore, it has the right to use it for free :D.
We just need to use DataGrip Connect our hive that will do
(1) stay hadoop102 Start the hiveserver2 service
[[email protected] hive]# hiveserver2
(2) Create connection

(3) Configure connection properties 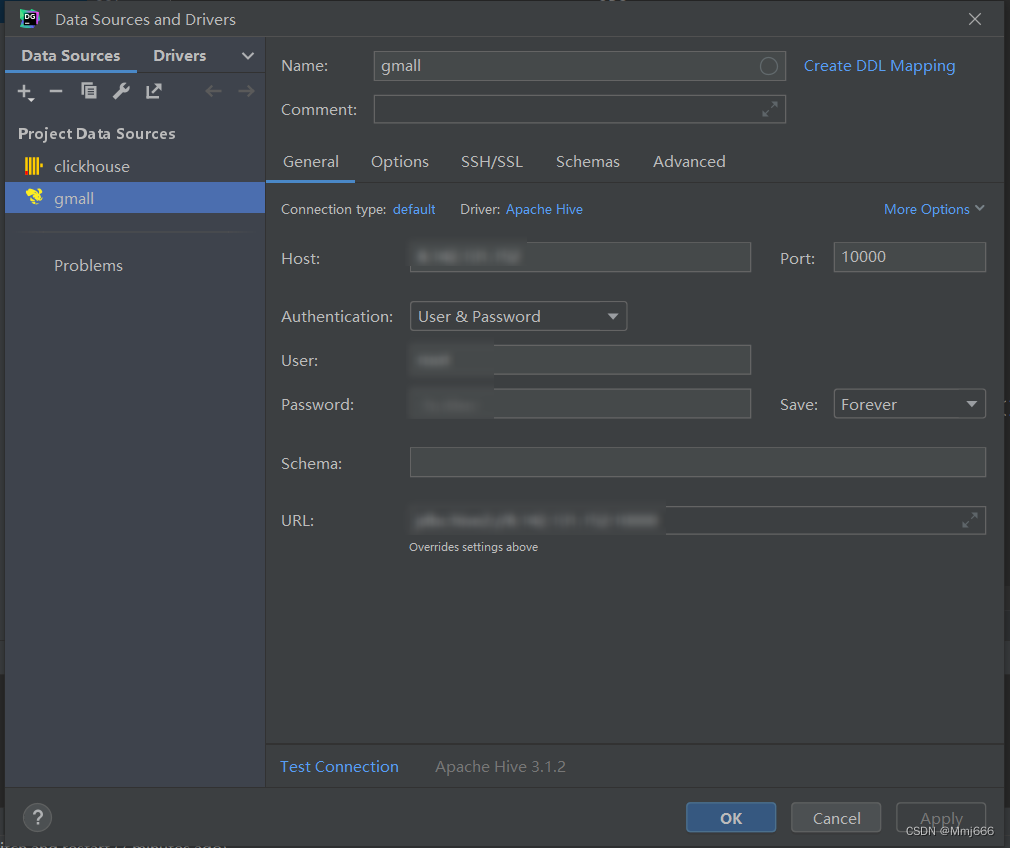
(4) Successful connection

9.2022-05-01 Analog data preparation
Simulate user behavior data , User behavior log , Generally, there is no historical data , Therefore, the log only needs to be prepared 2022-05-01 One day's data . We use the previously built data acquisition channel to collect HDFS On .
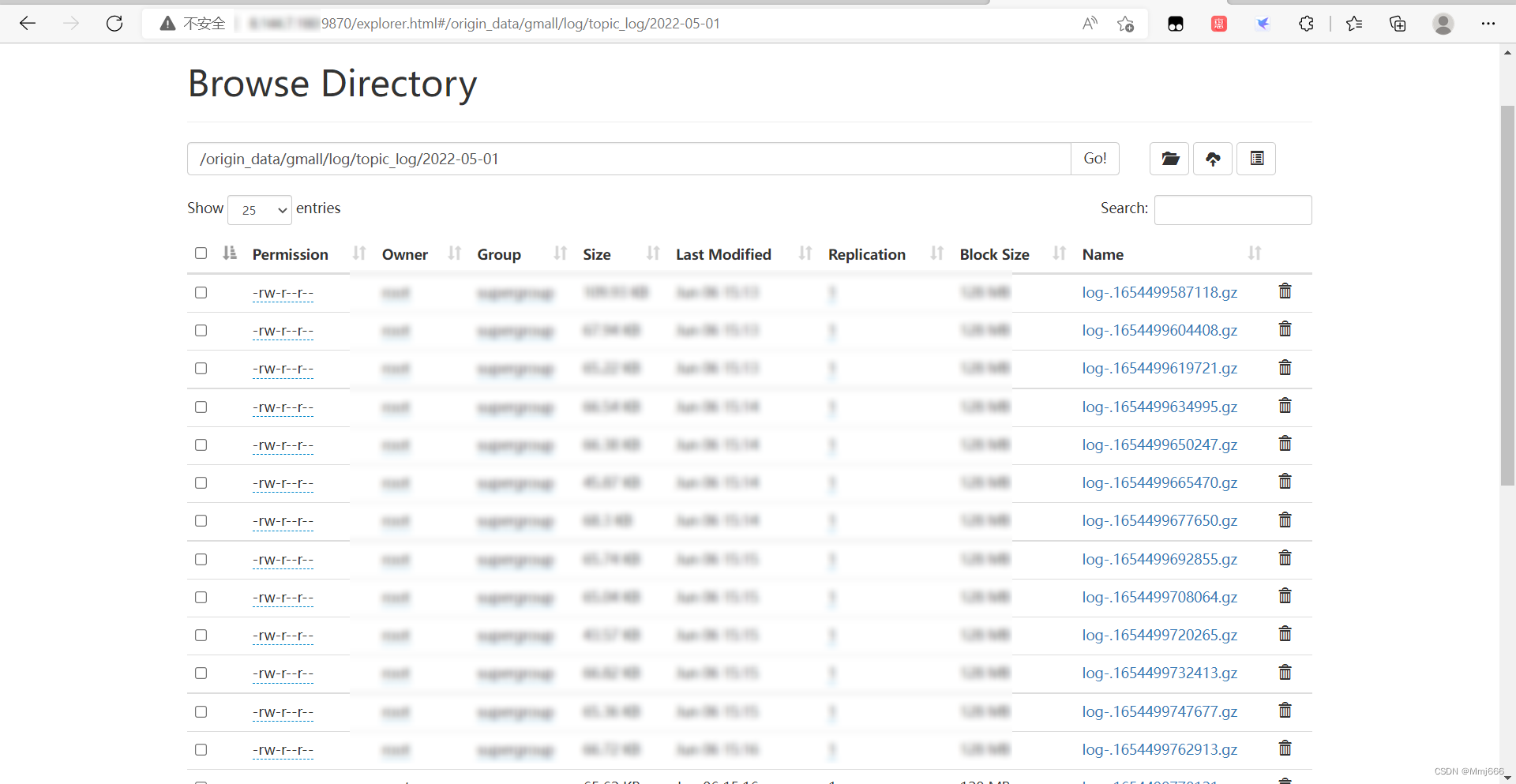
Simulate business data , Business data generally contains historical data , Here you need to prepare 2022-04-28 to 2022-05-01 The data of . We use the previously built data acquisition channel to collect HDFS On .

边栏推荐
猜你喜欢

Operation of C language files
![[first launch in the whole network] one month later, we switched from MySQL dual master to master-slave](/img/2f/b894569c8d13c9c18fd201c12a5d07.png)
[first launch in the whole network] one month later, we switched from MySQL dual master to master-slave

一次全面的性能优化,从5秒优化到1秒

MySQL事务

What is the employment prospect of software testing? There is a large demand for talents and strong job stability
电商用户行为实时分析系统(Flink1.10.1)

5. Spark核心编程(1)

Face scum counter attack: thread pool lethal serial eighteen questions, the interviewer praised me straight

Using Flink SQL to fluidize market data 2: intraday var

Talk about 12 business scenarios of concurrent programming
随机推荐
10.数据仓库搭建之DWD层搭建
7.数据仓库搭建之数据仓库环境准备
Distributed storage fastdfs
MySQL cache strategy and solution
线上软件测试培训机构柠檬班与iTest.AI平台达成战略合作
Use iceberg in CDP to pressurize the data Lake warehouse
Face scum counter attack: thread pool lethal serial eighteen questions, the interviewer praised me straight
H5 how to obtain intranet IP and public IP
操作系統常見面試題
【Bug解决】org.apache.ibatis.type.TypeException: The alias ‘xxxx‘ is already mapped to the value ‘xxx‘
Common (Consortium)
Flutter Intl的使用
sql时间对比
10 question 10 answer: do you really know thread pools?
gradle
[efficiency of function]
聊聊写代码的20个反面教材
Questions d'entrevue courantes du système d'exploitation
Online software testing training institutions lemon class and itest AI platform achieves strategic cooperation
使用Flink SQL传输市场数据1:传输VWAP