当前位置:网站首页>垂直搜索
垂直搜索
2022-07-26 08:55:00 【还是转转】
垂直化搜索引擎在分布式系统中是一个非常重要的角色,它既能够满足用户对于全文检索、模糊匹配的需求,解决数据库like查询效率低下的问题,又能够解决分布式环境下,由于采用分库分表,或者使用NoSql数据库,导致无法进行多表关联或者复杂查询的问题。垂直化搜索引擎主要针对企业内部的自有数据的检索。
Lucene
Lucene是Apache旗下的一款高性能、可伸缩的开源的信息检索库。通过Lucene可以十分容易地为应用程序添加文本搜索功能。
这里就不介绍索引,分词等名词了,直接看代码示例。
Demo
依赖库:
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>8.0.0</version>
</dependency>
代码示例:
public class SearchDemo {
// 索引路径
private static String INDEX_PATH = "/data/soft/search/index";
// 文件路径
private static String FILE_PATH = "/data/soft/search/demo.txt";
private static void testIndex() throws Exception {
// 需要读入的文件目录
Path fileDoc = Paths.get(FILE_PATH);
// 指定索引位置
Directory directory = FSDirectory.open(Paths.get(INDEX_PATH));
// 创建分词器
Analyzer analyzer = new StandardAnalyzer();
// 写索引配置
IndexWriterConfig config = new IndexWriterConfig(analyzer);
config.setOpenMode(IndexWriterConfig.OpenMode.CREATE);
// IndexWriter是lucene的核心类,用于存储索引
IndexWriter indexWriter = new IndexWriter(directory, config);
// 写入索引
indexDocs(indexWriter);
indexWriter.close();
}
private static void indexDocs(IndexWriter indexWriter) throws IOException {
Document document = new Document();
File file = new File(FILE_PATH);
// 文件名
Field fileName = new StringField("fileName", file.getName(), Store.YES);
// 文件内容
String content = FileUtils.readFileToString(file);
Field fileContent = new TextField("content", content, Store.YES);
document.add(fileName);
document.add(fileContent);
System.out.println("adding files:" + file.getName());
//添加文档
indexWriter.addDocument(document);
}
private static void query(Query query, int maxResult) throws IOException {
Directory directory = FSDirectory.open(Paths.get(INDEX_PATH));
// 索引读取
DirectoryReader directoryReader = DirectoryReader.open(directory);
IndexSearcher indexSearcher = new IndexSearcher(directoryReader);
TopDocs topDocs = indexSearcher.search(query, maxResult);
TotalHits totalHits = topDocs.totalHits;
// 得分文档数组
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
int docId = scoreDoc.doc;
Document document = directoryReader.document(docId);
System.out.println("fileName: " + document.get("fileName"));
System.out.println("fileContent: " + document.get("content"));
System.out.println("Score: " + scoreDoc.score);
}
}
public static void main(String[] args) {
try {
testIndex();
// 模糊匹配
WildcardQuery query = new WildcardQuery(new Term("content", "*hello*"));
query(query, 10);
} catch (Exception e) {
e.printStackTrace();
}
}
}
其中,demo.txt的内容为:hello world
全文检索
对于非结构化数据的搜索方法有两种,顺序扫描和全文检索。顺序扫描即从头到尾的扫描,如windows系统的搜索文件,linux下的grep命令等,这种方法对于小数据量的文件比较方便,但对于大量文件就不合适了。
对于大量文件的检索,可以使用全文检索。其基本思路是:将非结构化数据中的一部分信息提取出来,重新组织成具有一定结构的数据,然后基于此结构化数据进行搜索。这部分提取出来的结构化数据称之为索引。
全文检索的过程如下: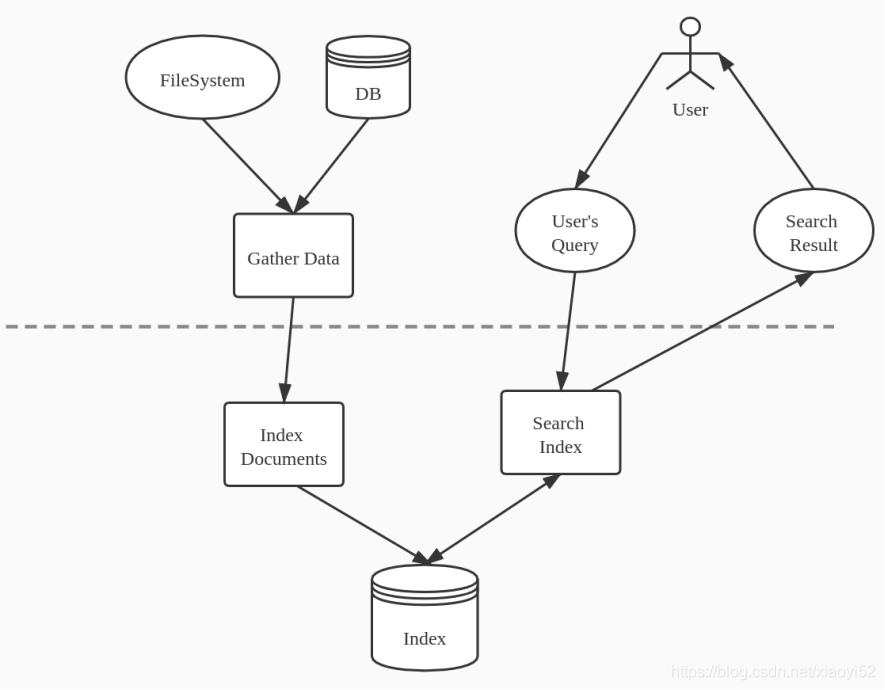
Index
非结构化数据中存储的信息:文件->字符串,而想要搜索的是:字符串->文件。
如果索引能够保存从字符串到文件的映射,则会大大提高搜索速度。保存这种信息的索引称为反向索引或倒排索引。
假设有100个文档,id为1-100,则倒排索引有如下的结构:
假设现在要搜索包含字符串keyWord1,KeyWord2的文档,则只需要对两个关键词对应的文档链表求交集,得到文档3,35,92三个文档。
通过以上介绍,现在来理解Demo示例代码应该比较容易了:先通过原始数据提取索引,再通过索引查询文档信息。
模糊查询
Lucene全文检索原理是:从每个document中提取出结构化数据,建立索引。最终通过索引进行查询。据此很容易想到,假如将每行数据记录当做一个document,然后提取出需要查询的字段建立索引,就能进行模糊查询了。
将Demo中的示例代码进行改造。首先将索引生成封装到Suggest类中。将testIndex改写成Index方法如下:
private void index(String indexPath, List<SuggestMeta> suggestMetaList) throws IOException {
// 指定索引位置
Directory directory = FSDirectory.open(Paths.get(indexPath));
// 写索引配置
IndexWriterConfig config = new IndexWriterConfig(new IKAnalyzer());
// IndexWriter是lucene的核心类,用于存储索引
IndexWriter indexWriter = new IndexWriter(directory, config);
// 写入索引
indexDocs(indexWriter, suggestMetaList);
indexWriter.close();
}
这里指定中文分词器IKAnalyzer(使用中文分词器需要两个配置文件,后面再说)来创建一个IndexWriteConfig对象,以支持中文分词。然后读取List源数据来创建索引。源数据怎么来?只需要从源文件(或其他方式)中读取,每行数据结构为一个SuggestMeta对象,将所有数据放到list中。最后通过indexDocs方法来实际执行索引生成:
private void indexDocs(IndexWriter indexWriter, List<SuggestMeta> metaList) throws IOException {
for (SuggestMeta suggestMeta : metaList) {
Document document = new Document();
Field id = new StringField("id", suggestMeta.getId(), Field.Store.YES);
Field weight = new DoublePoint("weight", suggestMeta.getWeight());
Field title = new StringField("name", suggestMeta.getWord(), Field.Store.YES);
document.add(id);
document.add(weight);
document.add(title);
indexWriter.addDocument(document);
}
System.out.println("index created");
}
Field有不同的实现,如StringField,DoublePoint,TextField,StoredField等。其中,基本类型的Field一定会被索引,但是不会被分词。查找的时候一定要匹配所有的内容,否则搜索不到。可以通过store字段来指定是否存储。TextField一定会被索引,同时会被分词。StoredField不会被索引,但是会被存储。
如果一个字段要显示到最终的结果中,那么一定要存储,否则就不存储。如果要根据这个字段进行搜索,那么这个字段就必须创建索引。如果一个字段的值是不可分割的,那么就不需要分词。
创建好索引后,通过WildcardQuery来进行模糊查询就可以了。如果要支持中文的话,则需要使用中文分词器IKAnalyzer,依赖库为:
<dependency>
<groupId>com.janeluo</groupId>
<artifactId>ikanalyzer</artifactId>
<version>2012_u6</version>
</dependency>
另外还需要两个配置文件,放到resources目录下。IKAnalyzer.cfg.xml如下:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典
<entry key="ext_dict">ext.dic;</entry>
-->
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">stopword.dic;</entry>
</properties>
停止词字典stopword.dic如下:
a
an
and
are
as
at
be
but
by
for
if
in
into
is
it
no
not
of
on
or
such
that
the
their
then
there
these
they
this
to
was
will
with
详细代码见:https://github.com/howetong/search
参考资料
[1]. https://www.jianshu.com/p/90451b77cd14
[2]. https://www.jianshu.com/p/c8793a06f5ae
[3]. https://www.jianshu.com/p/98a08a99d6b1
边栏推荐
- 【final关键字的使用】
- Kotlin properties and fields
- at、crontab
- JS file import of node
- 数据库操作技能7
- What are the differences in the performance of different usages such as count (*), count (primary key ID), count (field) and count (1)? That's more efficient
- ext4文件系统打开了DIR_NLINK特性后,link_count超过65000的后使用link_count=1来表示数量不可知
- Learning notes of automatic control principle - Performance Analysis of continuous time system
- 深度学习常用激活函数总结
- Learn more about the difference between B-tree and b+tree
猜你喜欢

Day06 homework - skill question 7

Study notes of automatic control principle --- stability analysis of control system

Okaleido launched the fusion mining mode, which is the only way for Oka to verify the current output

Learning notes of automatic control principle --- linear discrete system

Kept dual machine hot standby

tcp 解决short write问题

Database operation topic 1

Database operation skills 7

sklearn 机器学习基础(线性回归、欠拟合、过拟合、岭回归、模型加载保存)

Babbitt | metauniverse daily must read: does the future of metauniverse belong to large technology companies or to the decentralized Web3 world
随机推荐
合工大苍穹战队视觉组培训Day6——传统视觉,图像处理
Zipkin安装和使用
day06 作业--技能题1
[encryption weekly] has the encryption market recovered? The cold winter still hasn't thawed out. Take stock of the major events that occurred in the encryption market last week
209. Subarray with the smallest length
Nuxt - 项目打包部署及上线到服务器流程(SSR 服务端渲染)
idea快捷键 alt实现整列操作
数据库操作技能7
ONTAP 9文件系统的限制
NFT与数字藏品到底有何区别?
Learning notes of automatic control principle - Performance Analysis of continuous time system
[database] gbase 8A MPP cluster v95 installation and uninstall
Okaleido launched the fusion mining mode, which is the only way for Oka to verify the current output
Arbitrum Nova release! Create a low-cost and high-speed dedicated chain in the game social field
General file upload vulnerability getshell of a digital campus system (penetration test -0day)
Set of pl/sql
Day06 operation -- addition, deletion, modification and query
【无标题】
Study notes of automatic control principle -- dynamic model of feedback control system
What are the differences in the performance of different usages such as count (*), count (primary key ID), count (field) and count (1)? That's more efficient