当前位置:网站首页>flink. 14. How is the underlying layer of datastream module source implemented?
flink. 14. How is the underlying layer of datastream module source implemented?
2022-07-18 06:22:00 【Flying dried fish】
source The implementation of the
1. source The three core components of the underlying implementation
This page describes Flink Data source API And the concept and architecture behind it , No code involved .
source There are three core components : Splits, SplitEnumerator,SourceReader.
**
Overall process :SplitEnumerator-> [split01,split02…] <-SourceReader Initiate request
**
- SplitEnumerator
SplitEnumerator Generate some splits And assign them to sourcereader. It is used as a Job Manager A single instance on the machine runs , Responsible for maintaining the pending split backlog , And distribute them to sourcereader. - splits
Split yes source Part of the data .SplitEnumerator hold source Split into pieces split, By SourceReader Read . - SourceReader
SourceReader To request SplitEnumerator Segmented data source slices split Implement concurrent read source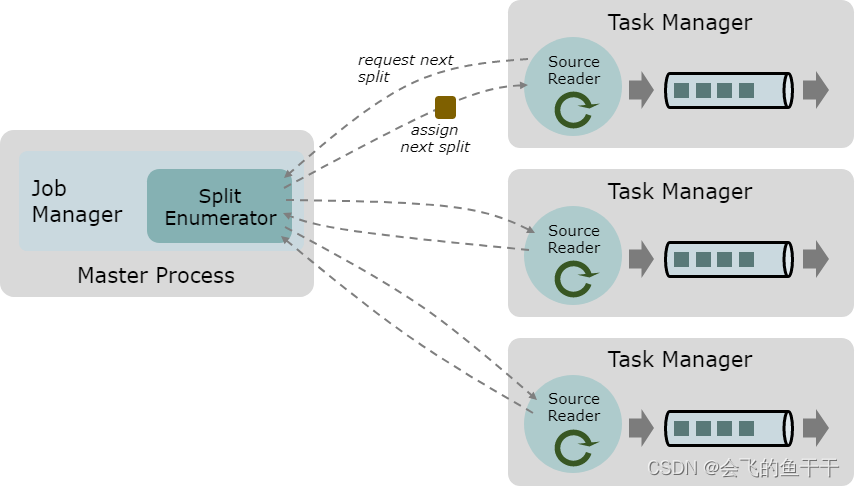
2. About bounded source And no solution source
bounded source When reading , from SplitEnumerator Generate data fragment set , The number of fragments of a set is limited .
Unsolvable source When reading , from SplitEnumerator The set of generated data slices is also infinite , however SplitEnumerator Will continue to generate fragments , And put the pieces into the set .
sourceReader To read data from the fragment set , Reading is parallel , See above .
2.1 example 1: Bounded file directory reader Reading :
source Code with directory to read URI/ route , And define how to parse the file format (format).
- SplitEnumerator List all files under the given directory path . It will split Assigned to the next reader requesting splitting . Once all splits have been allocated , It will use NoMoreSplits Response request .
- Regard a whole document or part of a document as split( This piece depends on format The concrete realization of )
- SourceReader Request the split and read the allocated split ( File or file area ) And use the given format to parse it . If it does not receive another split , Instead, I received a NoMoreSplits news , Then finish .
2.1 example 2: Unbounded stream file source
This source works the same way as above , except SplitEnumerator Never respond NoMoreSplits And regularly list the given URI/Path To check the new file . Once you find the new file , It will generate new splits for them , And they can be assigned to available SourceReader.
It means SplitEnumerator and SourceReader Kept similar to socket Long link function .
2.3 example 3: Infinite flow Kafka
source You need to specify the subscription topic list ( Support regular ), And define a deserializer to parse kafka Data in .
- SplitEnumerator And kafka Establishing a connection , obtain kafka Subscribed in the cluster topic All partitions of ,SplitEnumerator You can repeat the above behavior to find new topic and topic The partition .
- One kafka A partition is a partition
- SourceReader Use KafkaConsumer Read SplitEnumerator Assigned partition , And use the provided Deserializer Deserializing records .SplitEnumerator Keep detecting topic And zoning , therefore SourceReader It will never end .
2.4 example 4: Bounded flow kafka
Same as above , Just every one split Fragmentation ( Theme partition ) There is a definition End offset . once SourceReader arrive Split End offset of , It will complete the Split. be-all split When the offset position is reached , End of read .
3.The Data Source API
3.1 source
Source API It is a factory style interface , Used to create the following components .
1.Split Enumerator
2.Source Reader
3.Split Serializer
4.Enumerator Checkpoint Serialize
besides ,Source It also provides the bounded property of the source , In order to Flink You can choose the appropriate mode to run Flink Homework .
Source The implementation of is serializable , because Source The instance is serialized at run time and uploaded to Flink colony .
3.2 SplitEnumerator
First of all, it should be clear ,SplitEnumerator Should be Source Of “ The brain ”.
- SourceReader register hanlding Logic , This module establishes SplitEnumerator and SourceReader The connection of
- SourceReader failuer hanlding Logic , When SourceReader Read split When the failure , Will call addSplitsBack() Method .SplitEnumerator The failed information received should be recalled split.
- SourceEvent hanlding, This module is responsible for packaging SourceReader and SplitEnumerator Communication data , Be responsible for coordinating the two .
- split and assign,SplitEnumerator You can assign slices SourceReader To respond to various events , Including the discovery of new fragments 、 new SourceReader Registration of 、SourceReader Failure, etc . In a word, it's fragment discovery and distribution .
SplitEnumerator stay SplitEnumeratorContext The above work can be well completed under the coordination of ,SplitEnumeratorContext Is in SplitEnumerator Created or restored by Provide to Source. SplitEnumerator Can pass SplitEnumeratorContext recovery reader The necessary information .
Normally SplitEnumerator and SplitEnumeratorContext Coordination can work well , But sometimes we want to realize some flexible functions , For example, we want to realize a regular scan to find fragments , And assign the partition to reader When , You need to customize yourself , Here is a simple example :
class MySplitEnumerator implements SplitEnumerator<MySplit> {
private final long DISCOVER_INTERVAL = 60_000L;
/**
* A method to discover the splits.
*/
private List<MySplit> discoverSplits() {...}
@Override
public void start() {
...
enumContext.callAsync(this::discoverSplits, splits -> {
Map<Integer, List<MockSourceSplit>> assignments = new HashMap<>();
int parallelism = enumContext.currentParallelism();
for (MockSourceSplit split : splits) {
int owner = split.splitId().hashCode() % parallelism;
assignments.computeIfAbsent(owner, new ArrayList<>()).add(split);
}
enumContext.assignSplits(new SplitsAssignment<>(assignments));
}, 0L, DISCOVER_INTERVAL);
...
}
...
}
3.2 SourceReader
SourceReader It's a task Manager Components running in , Used to process a fragment split.
SourceReader A method based on pull Consumer interface .Flink task Thread tasks are constantly called in the loop pollNext(ReaderOutput) obtain sourceReade The data of . from pollNext The return value of can be seen sourceReader The state of , State the following :
1. MORE_AVAILABLE:SourceReader You can get more records immediately .
2. NOTHING_AVAILABLE-:SourceReader There are currently no more records available , But there may be more records in the future .
3. END_OF_INPUT: SourceReader Reach the end of the data . This means that it can be turned off SourceReader.
If necessary ,SourceReader It can be at one time pollNext() Sending out multiple records in the call . for example , Sometimes external systems work at block granularity . A block may contain multiple records , But the source can only check points at the block boundary . under these circumstances ,SourceReader All records in one block can be sent to ReaderOutput. however , Unless necessary , otherwise SourceReader Implementation should be avoided in a single pollNext(ReaderOutput) Multiple records are issued in the call . This is because from SourceReader The task thread polled in the event loop cannot be blocked .
SourceReader All of state It should be in snapshotState() Returned when called SourceSplits In the maintenance . Doing so allows SourceSplits Reassigned to others when needed sourcereader.
SourceReaderContext stay SourceReader Provided to Source.Source Pass context to SourceReader example .
SourceReader Can pass SourceReaderContext take SourceEvent Sent to it SplitEnumerator,
Source A typical design pattern of is to let sourcereader towards SplitEnumerator Report their local information ,SplitEnumerator Have a global view to make decisions .
SourceReader API It's a low-level API, It allows users to manually handle splitting , And has its own threading model to obtain and transfer records . For convenience SourceReader The implementation of the ,Flink Provides a SourceReaderBase class , It greatly reduces the writing SourceReader The amount of work required . Connector developers are strongly recommended to take advantage of SourceReaderBase, Instead of writing from scratch sourcereader. See more details Split Reader AP part .
4.use the source
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Source mySource = new MySource(...);
DataStream<Integer> stream = env.fromSource(
mySource,
WatermarkStrategy.noWatermarks(),
"MySourceName");
...
Be careful : stay DataStream API In the process of creating ,WatermarkStrategy Be passed on to Source, And create TimestampAssigner and WatermarkGenerator.
The TimestampAssigner and WatermarkGenerator run transparently as part of the ReaderOutput(or SourceOutput) so source implementors do not have to implement any timestamp extraction and watermark generation code.
4.1 Event Timestamps
There are two ways to extract events :
- by calling SourceOutput.collect(event, timestamp)
In this way source Of event record Only when time is included , And only in the built-in source connect It works , Realize it by yourself source It is not available when , About source connect There is no explanation here . - TimestampAssigner :use the source record timestamp or access a field of the event obtain the final event timestamp. Usage is the above code , Nothing to say .
5.The Split Reader AP Set up I
The core SourceReader API It's completely asynchronous , You need to manually manage asynchronous split reads . However , In practice , Most sources perform blocking operations , For example, blocking clients ( for example ) Upper poll()KafkaConsumer call , Or block the distributed file system (HDFS、S3 etc. ) Upper I/O operation . To make it asynchronous Source API compatible , These blockages ( Sync ) The operation needs to occur in a separate thread , These threads deliver data to the asynchronous part of the reader .
SplitReader It is used for simple synchronous reading / Advanced implementation of polling based sources API, For example, file reading 、Kafka etc. .
The core is SourceReaderBase class , It accepts SplitReader And create a run SplitReader Of fetcher Threads , Support different consumption thread models .
5.1 SplitReader
SplitReader There are only three ways .
- A blocking fetch method to return a RecordsWithSplitIds
- A non-blocking method to handle split changes.
- A non-blocking wake up method to wake up the blocking fetch operation.
The SplitReader only focuses on reading the records from the external system, therefore is much simpler compared with SourceReader. Please check the Java doc of the class for more details.
5.2 SourceReaderBase ( SourceReader Advanced way )
- List item There is a thread pool that gets from the split of the external system in a blocking way .
- Handle synchronization between internal fetch threads and other method calls , for example pollNext(ReaderOutput).
- Maintain each split watermark for watermark alignment .
- Maintain the status of each split of the checkpoint .// Used to recover
In order to reduce the writing of new work SourceReader, SourceReaderBase All the above work is out of the box . To write a new SourceReader, You can customize SourceReader Inherited from SourceReaderBase, Fill in some methods and implement an advanced SplitReader.
5.3 SplitFetcherManager
SourceReaderBase obtain splits It should be multi-threaded , Each thread processes one split Fragmentation , The choice of threading model depends on SplitFetcherManager ,SplitFetcherManager Create and manage a SplitFetchers Thread pool , Each in the pool splitfetcher All use one SplitReader Read a split Fragmentation .
SourceReaderBase The implementation of is called a SplitReader.
边栏推荐
- 杰理之入耳检测功能【篇】
- Matlab-mex
- R语言使用epiDisplay包的roc.from.table函数可视化临床诊断表格数据对应的ROC曲线并输出新的诊断表(diagnostic table)、输出灵敏度、1-特异度、AUC值等
- R语言dplyr包summarise_all函数计算dataframe数据中所有数值数据列的均值和中位数、使用sapply筛选数值数据列(Summarize all Numeric Variables
- 牛啊!2小时复现顶会论文,他的秘诀是——
- 企业在创建产品帮助中心时需要注意的问题!
- 爆肝万字,终于搞定这篇神经网络搭建全全全流程!学不会你来找我~
- 论文中的好文佳句摘录
- Symbol数据类型
- What's the use of games| Game application value research case collection
猜你喜欢
面对对象

企业在创建产品帮助中心时需要注意的问题!

软件研发效能需求价值流分析专题

线性代数 笔记1

原厂直销MOS管 KNL42150 2.8A/1500V 适用光伏逆变器 可提供样品

2022安全员-C证特种作业证考试题库及答案
![[multithreading] CAS mechanism analysis and application (atomic class, spin lock), solving ABA problems](/img/5d/b544d25a9efeee9d1611399e440f06.png)
[multithreading] CAS mechanism analysis and application (atomic class, spin lock), solving ABA problems

如何將notepad++設置為默認打開方式
![[2022 wechat applet demining] how to correctly obtain openid in cloud development and non cloud development environments?](/img/36/b930cb179b60f5a31b119b7fb4c3f7.jpg)
[2022 wechat applet demining] how to correctly obtain openid in cloud development and non cloud development environments?

爆肝万字,终于搞定这篇神经网络搭建全全全流程!学不会你来找我~
随机推荐
Apache apisik meetup Nanjing station! See you at 7.30!
炒期货到哪里开户?如何开户更安全?
regular expression
What is the difference between reject and catch processing in promise
看完这5个理由,我终于知道FTP被替代的原因
Database daily question --- day 23: game play analysis L
24. 两两交换链表中的节点
迪文串口屏教程(2)
2022年安全员-A证考试题目及在线模拟考试
R语言ggplot2可视化:使用ggpubr包的ggstripchart函数可视化分组点状条带图(dot strip plot)、设置position参数配置不同分组数据点的分离并且是抖动数据点
Network connection scheme of overseas leisure games
forEach、for in、for of三者区别
医疗单据OCR识别+知识库校验,赋能保险智能理赔
杰理之调式时要修改 INI 文件配置【篇】
Jerry opened the key pairing, and after the first pairing TWS, it is difficult to pair successfully by cross pairing [article]
VII. Exception handling
Diwen serial port screen tutorial (2)
Symbol data type
R语言dplyr包summarise_at函数计算dataframe数据中多个数据列(通过向量指定)的计数个数、均值和中位数、使用list函数指定函数列表并指定自定义函数名称
蓝桥杯2022年第十三届省赛第三题-求和 (前缀和 或 公式法)