当前位置:网站首页>Learning Transferable Visual Models From Natural Language Supervision
Learning Transferable Visual Models From Natural Language Supervision
2022-07-19 01:50:00 【Chubby Zhu】
At present, I begin to understand the knowledge related to multimodality , Welcome criticism !
This paper comes from 2021 Year of International Conference on Machine Learning, Sort out and revise the main contents of the paper , Reference resources 【 Paper reading 】CLIP:Learning Transferable Visual Models From Natural Language Supervision ------ Multimodal , Vision , Pre training model _me_yundou The blog of -CSDN Blog Learning Transferable Visual Models From Natural Language Supervision - John_Ran - Blog Garden Two articles .
Thesis title : Learn transferable visual models from natural language supervision
Research questions : Combine text data and image data , Put forward CLIP, Use the method of comparative learning to study language - Image pre training , It's an efficient 、 Extensible supervised learning method of natural language .
Research ideas : Use pictures on the Internet , Training CLIP. After training , Natural language is used to refer to learned visual concepts , Then proceed zero-shot transfer learning.
(1) The first is to build CLIP,CLIP It's actually a pre training model , Including text editor and image editor , Calculate the similarity of text vector and image vector respectively , To predict whether they are a pair , Pictured 1 Shown .CLIP Input the image and text into an image encoder respectively image_encoder And a text encoder text_encoder, Get the vector representation of image and text I-f and T_f . Then map the vector representation of image and text to a joint multi-channel space , Get a new vector representation of image and text that can be directly compared I_e and T_e . Then calculate the distance between the image vector and the text vector cosine Similarity degree . Last , The objective function of comparative learning is to make the similarity of positive sample pairs higher , The similarity of negative sample pairs is low .
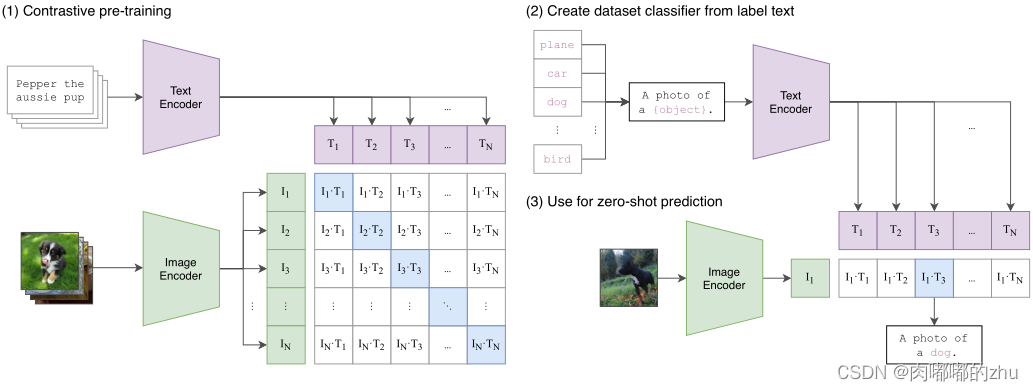 chart 1
chart 1
CLIP Jointly train image encoder and text encoder to predict a batch ( Images , Text ) Correct pairing of training examples . At testing time , Learn the text encoder by embedding the name or description of the target dataset class , Synthesize a zero shot linear classifier .CLIP Code as shown 2 Shown :

chart 2
(2) Conduct zero-shot transfer learning
Research process :1. Build a large enough data set -----》WebImageText(4 100 million texts - The image is right )
2. Choose an effective pre training model -----》CLIP
3. Select and scale the model ------》 The author chooses two models , One is ResNet-D, Smoothed rect-2 blur pooling. take global average pooling Use one attention pooling To improve . Among them the transformer Type of layer , In order to global average-pooled representation As query. second vision The structure of is ViT, Few changes : stay patch embbeding and position embedding combination after , Added a layer normalization. Then when it comes to implementation , A little different initialization is used Strategy .
4. Preliminary training ------》 Trained scale Strategy ,5 individual ResNet,3 individual vit.ResNet-50, ResNet-101, RN50x4, RN50x16, and RN50x64. ViT-B/32, a ViT-B/16, and a ViT-L/14. Finally make With 32,768 Of batch size. Used gradient checkpoint. Semi precision .The largest ResNet model, RN50x64, took 18 days to train on 592 V100 GPUs while the largest Vision . Transformer took 12 days on 256 V100 GPUs. One more vit Use 336 Of pixel resolution.
5. utilize CLIP------》 For each data set , Use the names of all classes in the dataset as a set of potential text pairs close , And according to CLIP Predict the most likely ( Images 、 Text ) Yes . Besides , Also try for CLIP Provide text prompts To help assign tasks , And integrating multiple of these templates to improve performance .
Data sets and experimental results : For the performance of the model , The author in 27 Experiments were carried out on two data sets , Found in 16 Better performance on data sets :

Major innovations :CLIP It's a pre training model , It's like BERT、GPT、ViT Just like the pre training model . First, these models are trained with a large amount of unlabeled data , Then the trained model can be realized , Enter a piece of text ( Or an image ), The output text ( Images ) Vector representation of .CLIP and BERT、GPT、ViT The difference is that ,CLIP It's multimodal , Including image processing and text processing , and BERT、GPT Is single text modal ,ViT It's single image mode .
summary :
About CLIP Some limitations of :
The author thinks that , Only with baseline Draw is not the ultimate goal . Because it is completely supervised with these data sets SOTA Compare to ,CLIP I can't beat them . You need to enlarge the current calculation amount to 1000x To achieve the present SOTA, This is impossible under the current hardware conditions .
The author thinks that ,CLIP In some special type especially strong task Not very work. such as , On some fine-grained data sets , Or some more abstract 、 symmetrical task. these task Pictures of the , stay CLIP Of pre-train The data set of appears less . The author thinks that , There are still a lot of it task On ,CLIP I'm guessing .
CLIP It works well in many natural image distributions , But in some real out-of-distributiob Is still not very good on the data set , For example OCR On . stay rendered text The performance is quite good , Because this is CLIP Of pre-training It is very common . But in handwritten numeral recognition, it collapsed , Only 88% The accuracy of . Because from semantic and near-duplicate nearest-neighbor retrieval We didn't find .
边栏推荐
- js数组处理【splice 实现数组的删除、插入、替换】
- 【文献阅读】TENET: A Framework for Modeling Tensor Dataflow Based on Relation-centric Notation
- 未成年人数字安全保护的问题与对策
- 【pycharm】Cannot find reference ‘XXX‘ in ‘__init__.py‘ 解决办法
- Redis 突然变慢了?
- Xcode11新建项目后的一些问题
- 面向NDN的网络攻击检测技术分析
- The popularity of NFT IP licensing is rising, and the era of nft2.0 is coming?
- 监听浏览器返回操作-禁止返回上一页
- phthon3 安装 MySQLdb 报错问题解决 Reason: image not found
猜你喜欢

【文献阅读】VAQF: Fully Automatic Software-Hardware Co-Design Framework for Low-Bit Vision Transformer

How to use express and how to match and use routes

NFT排行榜-NFT实盘最新地址:NFT排行榜.COM

Red sun range 2

何为“数字藏品”?

【文献阅读】Multi-state MRAM cells for hardware neuromorphic computing

windwos 下载安装OpenSSH

【MySQL】windows安装MySQL 5.7

1章 性能平台GodEye源码分析-整体架构

字节二面:什么是伪共享?如何避免?
随机推荐
windwos 下载安装OpenSSH
The following packages have unmet dependencies: deepin.com.wechat:i386 : Depends: deepin-wine:i386
What are the NFT digital collection platforms? Which platforms are worth collecting?
Laravel之文件上传
普通异步发送代码编写
rotoc-gen-go: unable to determine Go import path for **.proto
Common asynchronous sending code writing
yum源的安装
【文献阅读】isl: An Integer Set Library for the Polyhedral Model
6章 性能平台GodEye源码分析-自定义拓展模块
Mysql 安装(rpm包方式)
蛟分承影,雁落忘归——袋鼠云一站式全自动化运维管家ChengYing(承影)正式开源
iPhone 各大机型设备号
【文献阅读】TENET: A Framework for Modeling Tensor Dataflow Based on Relation-centric Notation
ipfs 文件持久化操作
3章 性能平台GodEye源码分析-内存模块
Scala环境搭建
Solve the problem that Scala cannot initialize the class of native
README.md添加目录
Red sun range 2