当前位置:网站首页>iFair: Learning Individually Fair Data Representations for Algorithmic Decision Making
iFair: Learning Individually Fair Data Representations for Algorithmic Decision Making
2022-07-19 01:57:00 【Chubby Zhu】
subject : Learn individual fair data representation for algorithmic decision making
This paper introduces a method of mapping user record probability to low rank representation , This method coordinates the fairness of individuals and the utility of classifiers and rankings in downstream applications . Learning low rank data representation by defining a combined loss function , This work solves the basic trade-off between utility and fairness . The author applies their method to the classification of various real data sets and learns the ranking task , Proved the universality of their method . Their experiments show that , Compared with the best preliminary work of this setting , There are substantial improvements .( low-rank : The rank of the matrix is low ,eg:r=1)
Research background : In general, group equity is considered , Then the trade-off between personal fairness and accuracy has become a problem to be solved . here , A loss function is proposed to solve .
Research methods : Map an individual to an input space , This input space is independent of a specific protected subgroup . Define mapping functions , The sum of fairness loss and accuracy loss is expressed as the objective function . This research method is called iFair frame .
Personal fair representation and calculation : When there are two user records with all attributes xi and xj When the difference between the distance between and two records without sensitive attributes is less than or equal to the threshold , It means that there is personal fairness between these two user records .


The transformation mapping is expressed as : among ,U Represents the previously recorded probability distribution ,V Represents the prototype vector .


The loss function includes data loss and fairness loss :


Objective function :


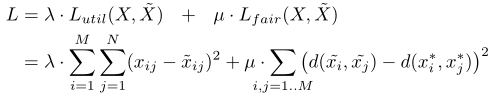
experiment :5 Data sets
| Data sets | Protected properties | Output | Number of instances |
| ProPublica’s COMPAS | race | Commit another crime ? | |
| Census Income | gender | income >50K? | 48842 |
| German Credit | age | Credit value ? | 1000 |
| Airbnb | gender | Housing rating / Price ? | 27597 |
| gender | Job recommendation ranking ? |
The author randomly divided the data set into three parts . Use a part of the training model to learn model parameters , The second part is the verification set , Select the superparameter by performing a grid search ( See below for details ), The third part is the test set . The same data segmentation is used in this paper to compare all methods , Altogether 6 Methods .
| Method | Full Data | Masked Data | SVD | LFR | FA*IR( Sort ) | iFair |
| Data set used | the original dataset | the original dataset without protected attributes | full data/masked data | the learned representation | the representation learned by our model |
The evaluation index is personal fairness (yNN) And accuracy (ACC)

Experiments show that , In general iFair The effect of is better than other methods .
summary : Our method contains two important criteria . First , We look at fairness from the perspective of application independence , This allows us to incorporate it into various tasks , Including general classifiers and regression for learning to rank . secondly , We regard personal equity as an attribute of the dataset ( In a sense , Like Privacy ), This can be achieved by preprocessing the data into a converted representation . There is no need to access protected properties at this stage . If necessary , We can also post process the representation of learning , And implement the standards of group fairness , For example, statistical equivalence .
We apply this model to five real data sets , Prove that utility and personal fairness can be coordinated to a great extent . Apply classifier and regression model to iFair In the middle , The resulting algorithm decision is more consistent than the decision made on the original data . Our method is the first method to calculate the fair result separately in the learning sorting task . For classification tasks , Its performance is better than the existing advanced work .
边栏推荐
- 数组定义格式
- rotoc-gen-go: unable to determine Go import path for **.proto
- [literature reading] tenet: a framework for modeling tensor dataflow based on relational centric notation
- 偏差(bias)和方差(variance)
- touchID 和 FaceID~1
- Yolov5训练建议
- 未成年人数字安全保护的问题与对策
- 爭奪存量用戶關鍵戰,助力企業構建完美標簽體系丨01期直播回顧
- 霍夫变换讲解
- Fairness in Deep Learning: A Computational Perspective
猜你喜欢

uniapp打包H5 空白页面 报错 Uncaught SyntaxError: Unexpected token ‘<‘

边缘检测方法 -- 一阶边缘检测

二阶边缘检测 - Laplacian of Guassian 高斯拉普拉斯算子

Mxnet network model (V) conditional Gan neural network

The popularity of NFT IP licensing is rising, and the era of nft2.0 is coming?

【文献阅读】Multi-state MRAM cells for hardware neuromorphic computing

What is "digital collection"?
![[literature reading] small footprint keyword spotting with multi scale temporary revolution](/img/18/ffa23bee826d78c388fde2f5d49282.png)
[literature reading] small footprint keyword spotting with multi scale temporary revolution
二階邊緣檢測 - Laplacian of Guassian 高斯拉普拉斯算子

Frustratingly Simple Few-Shot Object Detection
随机推荐
WKWebView 设置自定义UserAgent正确姿势
[translation] transformers in computer vision
【翻译】Transformers in Computer Vision
One vs One Mitigation of Intersectional Bias
windwos 下载安装OpenSSH
wkwebview白屏
Hands on deep learning - deep learning computing
The platform of digital collection NFT is good
Owl Eyes: Spotting UI Display Issues via Visual Understanding
动手学深度学习--线性神经网络篇
【文献阅读】isl: An Integer Set Library for the Polyhedral Model
【Go语言】代码覆盖测试(gcov)
Array definition format
3章 性能平台GodEye源码分析-内存模块
Rivaliser pour la guerre clé des utilisateurs de stock, aider les entreprises à construire un système d'étiquetage parfait 丨 01 examen en direct
[go language] code coverage test (Gcov)
[literature reading] multi state MRAM cells for hardware neural computing
通信感知一体化应用场景、关键技术和网络架构
一种5G空口单向时延及其可靠性的测量方法
【文献阅读】MCUNet: Tiny Deep Learning on IoT Devices