当前位置:网站首页>OD-Paper【1】:Rich feature hierarchies for accurate object detection and semantic segmentation
OD-Paper【1】:Rich feature hierarchies for accurate object detection and semantic segmentation
2022-07-26 05:20:00 【zzzyzh】
List of articles
Preface
RCNN(Regions with CNN features) Yes, it will CNN This is a milestone in the application of the method to target detection , With the help of CNN Good feature extraction and classification performance , adopt RegionProposal Method to realize the transformation of target detection problem .
This paper mainly interprets the paper , And explain about RCNN Part of the frame
1. Abstract & Introduction
1.1. Abstract
The method of this paper combines two key factors :
- Use a high-capacity convolutional neural network from bottom to top on the candidate region (CNNs)( Network capacity : The ability of artificial neural network to shape complex functions ), Used to locate and segment objects .
- When the labeled training data is insufficient , First, carry out supervised pre training for auxiliary tasks, and the good model , Plus fine tuning on a specific domain , Can produce significant performance improvement .
In this paper, candidate regions (region proposals) And CNNs combination , Therefore, this method is called R-CNN(Regions with CNN features): have CNN Candidate areas for features .
1.2. Introduction
This paper focuses on two issues : Use deep network to locate targets and train high-capacity network models on small-scale labeled data sets .
Different from image classification , Detection requires locating many objects in an image . One way is to think of location as a regression problem . Another alternative is to build a sliding window detector , Use... In this way CNNs At least there are 20 It's been years . Usually used for some limited object categories , Like face , Pedestrians, etc . In order to maintain high spatial resolution , these CNNs Only two convolution layers and two pooling layers are used .
contrary , This paper is through the use of “ Use the identification of candidate areas ” Methods , It's solved CNN The problem of positioning ( This has achieved success in target detection and semantic segmentation ). When testing , The method of this paper is input image , Generated close 2000 Category independent candidate areas , utilize CNN Extract a fixed length feature vector from each candidate region , then With the help of linearity specific to specific categories SVM Classify each candidate area . We don't consider the size of the area , The method of radiograph deformation is used to generate a fixed length image for each candidate region CNN Input eigenvector ( That is to put candidate areas of different sizes into the same size ). The following figure shows an overview of our method and highlights some experimental results . Because our system combines candidate regions and CNNs, So it's called R-CNN(regions with CNN features): have CNN Candidate areas for features .
2. Object detection with R-CNN
2.1. Algorithm process
RCNN The algorithm flow can be divided into 4 A step :
- One image generation 1000~2000 Candidate areas ( Use Selective Search Method )
- For each candidate area , Use deep networks to extract features
- Features are fed into each type of SVM classifier , Judge whether it belongs to this category
- Use regression to fine tune candidate box position
2.2. Module design

2.2.1. Region proposals
utilize Selective Search The algorithm obtains some original regions by image segmentation , Then use some merge strategies to merge these regions , Get a hierarchical regional structure , And these structures contain objects that might be needed .
2.2.2. Feature extraction
For each candidate area , Use deep networks to extract features . take 2000 Zoom candidate areas to 227 x 227 pixel , Then input the candidate area into the pre trained AlexNet CNN Internet access 4096 The feature of dimension is obtained 2000 x 4096 dimension matrix .
there CNN Image classification network , But remove the last full connection layer , Get the output 4096 Dimension vector .
2.2.3. SVM classifier
take 2000 x 4096 dimension Characteristics and 20 individual SVM The weight matrix 4096 x 20 Multiply , get 2000 x 20 dimension The matrix indicates that each suggestion box is the score of a certain goal . Respectively for the above 2000 x 20 dimension Each column in the matrix, that is, each class Non maximum suppression Eliminate overlapping suggestion boxes , Get this column, that is, some suggestion boxes with the highest scores in this category .
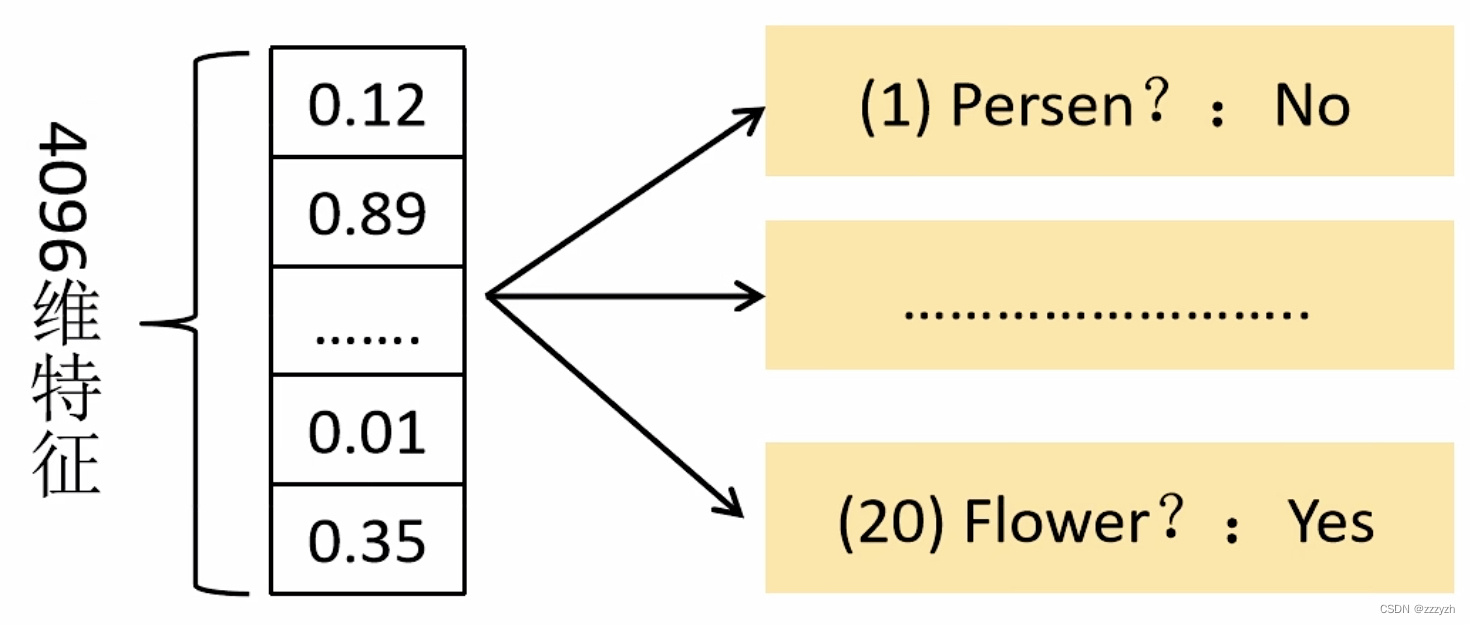
Be careful : To facilitate observation , The vector in the picture is transposed
It can be understood as , Each column vector represents the probability that the category box in the picture is the class corresponding to the column
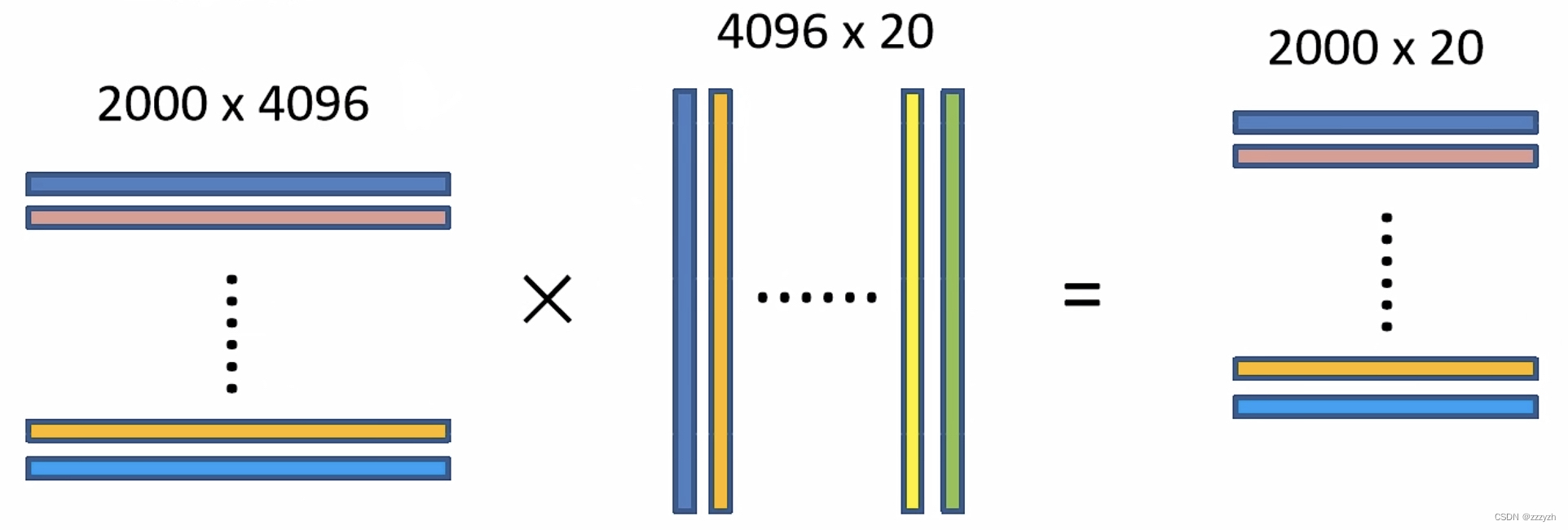
- The matrix on the left : Each line is where each feature box passes CNN The feature vector obtained after classifying the network
- The matrix in the middle : namely SVM A weight matrix , Each column corresponds to the weight vector of a category
- The matrix on the right : Suppose the first column of the matrix in the middle represents a cat , The second column represents dogs , Then the first row of the matrix on the left is multiplied by the first column of the intermediate matrix , Get the elements of the first row and the first column of the matrix on the right , That is, the probability that the first candidate box is a cat
- For each column of the matrix on the right ( That is, each type ), Carry out non maximum suppression , To eliminate some overlapping suggestion boxes
- For example, the first column of the matrix on the right represents the probability that all candidate boxes are cats
2.2.3.1. Non maximum suppression
IoU (Intersection over Union)
- The mathematical representation is : ( A ∩ B ) / ( A ∪ B ) (A\cap B) / (A\cup B) (A∩B)/(A∪B)

- For the use of each category
- Looking for the highest scoring target
- Calculate the relationship between other goals and that goal IoU value
- Delete all IoU Targets with values greater than a given threshold
- The deleted targets here refer to those parts that overlap with the highest score much ,IoU Although big , But the score is not the highest , One with the highest score is enough
- The purpose is to eliminate overlapping frames ,IoU The larger the value, the more overlapping areas

2.2.4. Regressor correction
Use regression to fine tune candidate box position , Yes NMS (Non-Maximum Suppression) After processing, the remaining suggestion boxes are further filtered . Then separately use 20 A regressor for the above 20 The suggestion boxes belonging to the category are regressed , Finally get the highest score of each category after correction bounding box.
After regression classifier , You'll get 4 Parameters : The center point of the goal suggestion box x Offset 、y Offset , Scaling factor of bounding box Height 、 Width scaling factor

Pictured , Yellow frame P P P A suggestion box Region Proposal, Green window G G G Represents the actual box Ground Truth, The red window G ^ \hat{G} G^ Express Region Proposal The prediction window after regression , Linear regression problems that can be solved by the least square method .
3. R-CNN The problem is
- The test speed is slow
Test a picture about 53s(CPU). use Selective Search The algorithm takes about 2s, There is a lot of overlap between candidate frames in an image , Feature extraction operation redundancy . - Training is slow
The process is extremely cumbersome - Training needs a lot of space
about SVM and bbox Back to training , We need to extract features from each target candidate box in each image , And write to disk . For very deep networks , Such as VGG16, from VOC07 From the training set 5k The features extracted from the image need hundreds of G Storage space
summary
边栏推荐
- Day011 一维数组
- 一次线上事故,我顿悟了异步的精髓
- no networks found in /etc/cni/net.d
- C语言实现发牌功能基本方法
- nacos注册中心
- Shell的read 读取控制台输入、read的使用
- Embedded sharing collection 21
- @Principle of Autowired annotation
- Leetcode linked list problem - 206. reverse linked list (learn linked list by one question and one article)
- No background, no education? Is it really hopeless for specialist testers to enter Internet factories?
猜你喜欢

Go-Excelize API源码阅读(六)—— DeleteSheet(sheet string)

一次线上事故,我顿悟了异步的精髓

Black eat black? The man cracked the loopholes in the gambling website and "collected wool" for more than 100000 yuan per month

Basic methods of realizing licensing function in C language

提高shuffle操作中的reduce并行度

手把手教你用代码实现SSO单点登录

JVM Lecture 2: class loading mechanism
kubernetes install completed

真正的科学减肥

Recommend 12 academic websites for free literature search, and suggest to like and collect!
随机推荐
嵌入式开发小记,实用小知识分享
An online accident, I suddenly realized the essence of asynchrony
元宇宙为服装设计展示提供数字化社交平台
[acwing] 2983. Toys
DOM事件流 事件冒泡-事件捕获-事件委托
ABAP语法学习(ALV)
Go-Excelize API源码阅读(六)—— DeleteSheet(sheet string)
How to conduct test case review
LAMP架构
Okaleido launched the fusion mining mode, which is the only way for Oka to verify the current output
“双碳”目标下资源环境中的可计算一般均衡(CGE)模型实践技术
[Luogu] p3919 [template] persistent segment tree 1 (persistent array)
Date and time function of MySQL function summary
攻防世界--easy_web
Full analysis of domain name resolution process means better text understanding
Webassembly 01 basic information
Practical technology of SWAT Model in simulation of hydrology, water resources and non-point source pollution
ThreadLocal transfer between parent and child threads in asynchronous
【个人总结】2022.7.24周结
Recommended reading: how can testers get familiar with new businesses quickly?