当前位置:网站首页>Redis 跳跃表实现原理 & 时间复杂度分析
Redis 跳跃表实现原理 & 时间复杂度分析
2022-07-17 05:41:00 【一个小码农的进阶之旅】
回顾一下跳表这种数据结构
跳表是在链表的基础上,增加了多级索引,通过索引位置的几个跳转,实现数据的快速定位
向跳表中插入一个元素的时间复杂度就为:O(logn)。这个时间复杂度等于二分查找的时间复杂度,所有有时我们又称跳表是实现了二分查找的链表。
Redis中跳跃表的结构
Redis使用跳跃表作为有序集合键的底层实现之一,如果一个有序集合包含的 元素数量比较多,又或者有序集合中元素的 成员是比较长的字符串时, Redis就会使用跳跃表来作为有序集合健的底层实现。
这里我们需要思考一个问题——为什么元素数量比较多或者成员是比较长的字符串的时候Redis要使用跳跃表来实现?
从上面我们可以知道,跳跃表在链表的基础上增加了多级索引以提升查找的效率,但其 是一个空间换时间的方案,必然会带来一个问题——索引是占内存的。原始链表中存储的有可能是很大的对象,而索引结点只需要存储关键值值和几个指针,并不需要存储对象,因此当节点本身比较大或者元素数量比较多的时候,其优势必然会被放大,而缺点则可以忽略。
Redis的跳跃表由 zskiplistNode 和 skiplist 两个结构定义:
- zskiplistNode结构用于表示跳跃表节点;
- zskiplist结构则用于保存跳跃表节点的相关信息,比如节点的数量,以及指向表头节点和表尾节点的指针等等。
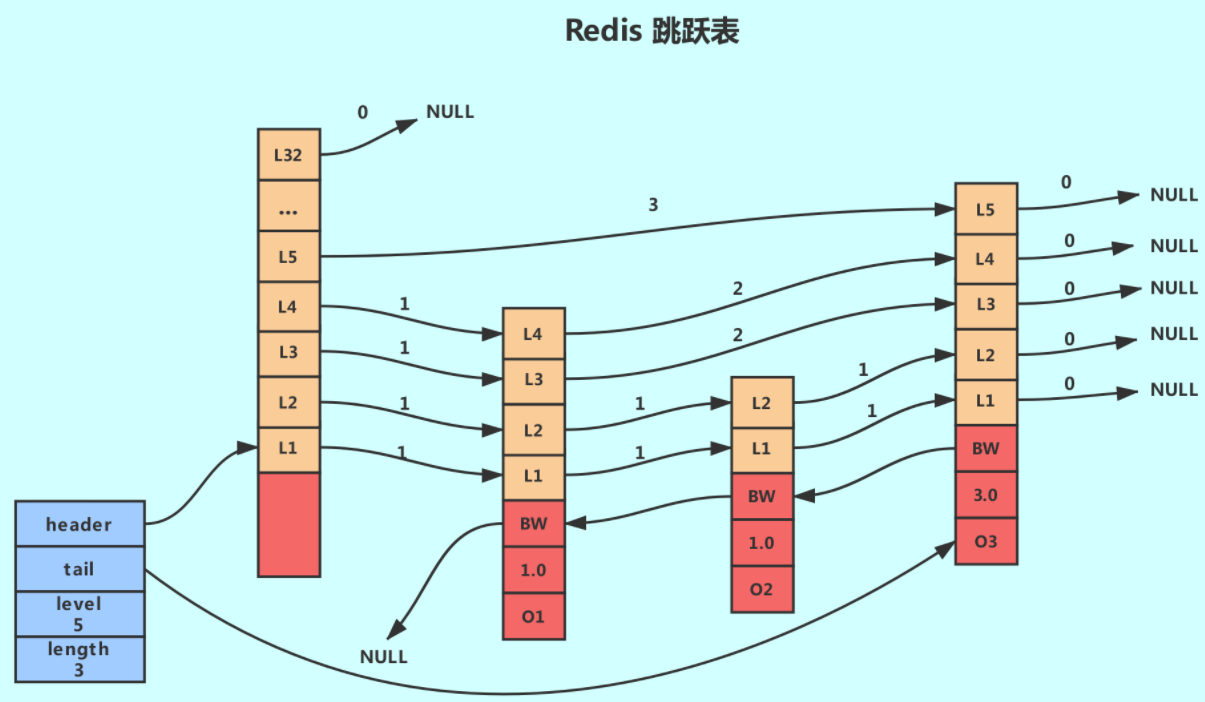
上图展示了一个跳跃表示例,其中最左边的是 skiplist结构,该结构包含以下属性:
- header:指向跳跃表的表头节点,通过这个指针程序定位表头节点的
时间复杂度就为O(1); - tail:指向跳跃表的表尾节点,通过这个指针程序定位表尾节点的
时间复杂度就为O(1); - level:
记录目前跳跃表内,层数最大的那个节点的层数(表头节点的层数不计算在内),通过这个属性可以再O(1)的时间复杂度内获取层高最好的节点的层数。 - length:记录跳跃表的长度,也即是,
跳跃表目前包含节点的数量(表头节点不计算在内),通过这个属性,程序可以再以O(1)的时间复杂度内返回跳跃表的长度。
结构右方的是四个 zskiplistNode结构,该结构包含以下属性:
- 层(level):节点中用L1、L2、L3等字样标记节点的各个层,L1代表第一层,L2代表第二层,以此类推。
- 每个层都带有两个属性:
前进指针和跨度。在上图中,连线上带有数字的箭头就代表前进指针,而那个数字就是跨度。当程序从表头向表尾进行遍历时,访问会沿着层的前进指针进行。- 前进指针用于访问位于表尾方向的其他节点;
- 跨度则记录了前进指针所指向节点和当前节点的距离(跨度越大、距离越远)。
- 每次创建一个新跳跃表节点的时候,程序都根据
幂次定律(powerlaw,越大的数出现的概率越小)随机生成一个介于1和32之间的值作为level数组的大小,这个大小就是层的“高度”。
- 每个层都带有两个属性:
- 后退(backward)指针:节点中用BW字样标记节点的后退指针,它指向位于当前节点的前一个节点。
后退指针在程序从表尾向表头遍历时使用。与前进指针所不同的是每个节点只有一个后退指针,因此每次只能后退一个节点。 - 分值(score):各个节点中的1.0、2.0和3.0是节点所保存的分值。在跳跃表中,
节点按各自所保存的分值从小到大排列。 - 成员对象(oj):各个节点中的o1、o2和o3是节点所保存的成员对象。
- 在同一个跳跃表中,
各个节点保存的成员对象必须是唯一的,但是多个节点保存的分值却可以是相同的; - 分值相同的节点将
按照成员对象在字典序中的大小来进行排序,成员对象较小的节点会排在前面(靠近表头的方向),而成员对象较大的节点则会排在后面(靠近表尾的方向)。
- 在同一个跳跃表中,
Redis跳跃表常用操作的时间复杂度 (重要)
| 常用API | 操作 | 时间复杂度 |
|---|---|---|
| zslCreate | 创建一个跳跃表 | O(1) |
| zslFree | 释放给定跳跃表以及其中包含的节点 | O(N),N为跳跃表长度 |
| zslInsert | 将包含给定成员和分值的新节点添加到跳跃表中 | 平均O(logN),最坏O(logN)(N为跳跃表的长度) |
| zslDelete | 删除除跳跃表中包含给定成员和分值的节点 | 平均O(logN),最坏O(logN)(N为跳跃表的长度) |
| zslGetRank | 返回给定成员和分值的节点在表中的排位 | 平均O(logN),最坏O(logN)(N为跳跃表的长度) |
| zslGetElementByRank | 返回在给定排位上的节点 | 平均O(logN),最坏O(logN)(N为跳跃表的长度) |
| zslIsInRange | 给定一个分值范固(range),比如0到15,20到28,诸如此类,如果跳跃表中有至少一个节点的分值在这个范間之内,那么返回1,否则返回0 | 通过跳跃表的表头节点和表尾节点,这个节点可以用O(1)复杂度完成 |
| zslFirstRange | 给定一个分值范围,返回跳跃表中第一个符合这个范围的节点 | 平均O(logN),最坏O(logN)(N为跳跃表的长度) |
| zslLastRange | 给定一个分值范围,返回跳跃表中最后一个符合这个范围的节点 | 平均O(logN),最坏O(logN)(N为跳跃表的长度) |
| zslDeleteRangeByScore | 给定一个分值范围,删除跳跃表中所有在这个范围之内的节点 | O(N),N为被除节点数量 |
| zslDeleteRangeByRange | 给定一个排位范围,移除跳跃表中所有在这个范围之内的节点 | O(N),N为被除节点数量 |
Redis为什么用跳表不用红黑树/B+树?
为什么不用红黑树?
- 红黑树的插入、删除、查找以及迭代输出有序序列这几个操作时间复杂度跟跳表一样。
- 但按照区间来查找数据这个操作红黑树的效率没有跳表高,
跳表可以做到 O(logn) 的时间复杂度定位区间的起点,再在原始链表中顺序往后遍历,非常高效。 - 其他原因还有跳表更容易代码实现;跳表更加灵活,它可以通过改变索引构建策略,有效平衡执行效率和内存消耗。
Tips: 跳表不能完全替代红黑树,红黑树比跳表的出现要早一些,很多编程语言中的 Map 类型都是通过红黑树来实现,做业务开发时可以直接拿来用,不用费劲自己去实现,但跳表没有现成的实现,所以在开发中如果想使用跳表必须要自己实现。
为什么不用B+树?
B+树的原理是叶子节点存储数据,非叶子节点存储索引,B+树的每个节点可以存储多个关键字,它将节点大小设置为磁盘页的大小,充分利用了磁盘预读的功能。每次读取磁盘页时就会读取一整个节点,每个叶子节点还有指向前后节点的指针,为的是最大限度的降低磁盘的IO;因为数据在内存中读取耗费的时间是从磁盘的IO读取的百万分之一。而Redis是内存中读取数据,不涉及IO,因此使用了跳表。
跳跃表小结
- 跳跃表基于单链表加索引的方式实现
- 跳跃表以空间换时间的方式提升了查找速度
Redis有序集合在节点元素较大或者元素数量较多时使用跳跃表实现- Redis的跳跃表实现由 zskiplist和 zskiplistnode两个结构组成,其中 zskiplist用于保存跳跃表信息(比如表头节点、表尾节点、长度),而zskiplistnode则用于表示跳跃表节点
Redis每个跳跃表节点的层高都是1至32之间的随机数- 在同一个跳跃表中,多个节点可以包含相同的分值,但每个节点的成员对象必须是唯一的跳跃表中的节点按照分值大小进行排序,当分值相同时,节点按照成员对象的大小进行排序。
边栏推荐
猜你喜欢

3D可视化入门基础:看渲染管线如何在GPU运作

912. 排序数组(数组排序)

TSN security protocol (802.1qci)

Spark3.x入门到精通-阶段七(spark动态资源分配)

Flink入门到实战-阶段二(图解运行时架构)
实时数据仓库-从0到1实时数据仓库设计&实现(SparkStreaming3.x)

Spark3.x source code compilation

Flutter3.0(framework框架)——UI渲染
导出文件or下载文件

Solve MySQL (1064) error: 1064 - you have an error in your SQL syntax;
随机推荐
Web Security (XSS and CSRF)
MySql02 函数substr mod 视图view
Prevent blackmail attacks through data encryption schemes
A2B音频总线在智能座舱中的应用
Canel Introduction & use
Spark3.x源码编译
正则表达示提取匹配内容
CAN FD如何应用Vector诊断工具链?
What if Jenkins forgets his password?
175. 组合两个表(MySQL数据库连接)
VMware Cloud Director 10.4 发布 (含下载) - 云计算调配和管理平台
Review - 5703 Statistical Inference and Modeling
V2X测试系列之认识V2X第二阶段应用场景
Component emit Foundation
redis 存储结构原理 2
京东购买意向预测(三)
面部关键点检测-CNN
Summary of Statistics for Interview
实时数据仓库-从0到1实时数据仓库设计&实现(SparkStreaming3.x)
传递多图片,是空情况的判断。