当前位置:网站首页>Li Hongyi machine learning 2022.7.15 -- gradient descent
Li Hongyi machine learning 2022.7.15 -- gradient descent
2022-07-19 15:09:00 【ww9878】
Introduction to gradient descent
In solving optimization problems 
We need to find the smallest group θ, Let the loss function be as small as possible .
First, choose any w0 and b0 Value , about w1 and b1 Conduct update:
η For learning rate , Manual setting . Repeat the above steps and keep updating wi and bi Until there is no change . stay update wi and bi The process of is gradient descent .
The partial differential part is the gradient part 
Learning rate η
Learning rate η The adjustment should be appropriate and just , It is easy to get stuck in a certain position if it is too large . If it is too small, the moving distance is small , The results appear slowly . Pictured :
Usually at the beginning, the distance from the lowest point is large , You can choose η It's worth more , As the moving distance is getting closer and closer to the lowest point, it can be appropriately lowered η Value . Different parameters require different learning rates .
Adagrad Algorithm
The learning rate of each parameter divides it by the root mean square of the previous differential ,σ^t: The root mean square of all the differential of the previous parameter , It's different for each parameter .
g^ t The greater the gradient . The greater the distance you move , and σ^t The greater the gradient , The smaller the step . There is a contradiction between the two . Consider the problem of cross parameters , So the best step should be : A differential / Quadratic differential . Directly proportional to the first derivative , It is inversely proportional to the quadratic differential , The quadratic differential is larger , Parameters update The larger . Only by considering quadratic differentiation can we truly reflect the distance of the lowest point .
Stochastic gradient descent
The random gradient descent method is faster than the previous gradient descent , Select one randomly or in order X^n, After calculating the loss function update gradient .
The general gradient descent step may include several examples , Random gradient descent has taken many steps .
Feature scaling
Scale its input feature range , Make the range of different features the same .
When xi The input value of is larger wi When the same changes , It has a great influence on the output value . As you can see from the diagram x2 It has a great influence on the loss function , be w2 It's steep around .
Zoom method

In the i Calculator average in dimensions mi, And its standard deviation σi, Then use the r The... In the first example i Inputs , Subtract the average mi, Then divide by the standard deviation σi, The result is that all dimensions are 0, All variances are 1.
Basis of mathematical theory of gradient descent
There are some places I still don't understand , Temporary remarks
Taylor expansion
if h(x) stay x=x0 There is an infinite derivative in a field of points ( Infinitely differentiable ,infinitely differentiable), So there are... In this field :

When x Very close to x0 when , Yes h(x)≈h(x0)+h′(x0)(x−x0) The above formula is a function h(x) stay x=x0 Near the point about x Power function expansion of , Also known as Taylor expansion .
Multivariate Taylor expansion

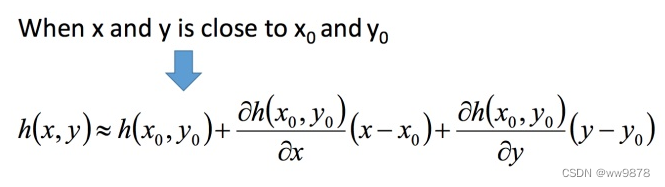
Based on Taylor expansion , stay (a,b) Within the red circle of the dot , The loss function can be simplified by Taylor expansion :

To get 
Minimize the loss function take (u,v) In the opposite direction 
u and v Into the :
Taylor expansion is pushed to process

Limitation of gradient descent
In the process of gradient descent , Because partial differential equals 0, It is easy to stop at a non minimum point .
边栏推荐
- ORA-08103
- 背包问题 (Knapsack problem)
- PKI: TLS handshake
- 人脸技术:不清楚人照片修复成高质量高清晰图像框架(附源代码下载)
- Leetcode 1275. Trouver le vainqueur de "Jingzi"
- Setup的使用技巧
- Icml2022 | geometric multimodal comparative representation learning
- 两种虚拟机的比较
- 买股票开户应该选哪个证券公司?什么证券公司是更安全的
- Natural language processing model of bigscience open source bloom
猜你喜欢
End repeated development and personalize the login system in twoorthree times

ORA-00054
A - Trees on the level(树的层序遍历)

UCAS. Deep learning Final examination questions and brief thinking analysis

Maximum heap and heap sort and priority queue

微信小程序6-云开发-云数据库

Icml2022 | geometric multimodal comparative representation learning

Google Earth Engine——无人机影像进行分类处理
ORA-00054

2021.07.13【B站】是这样崩的
随机推荐
Leetcode 1275. Trouver le vainqueur de "Jingzi"
ORA-08103
FPGA(VGA协议实现)
SQL wrong questions set of Niuke brush questions
08_服务熔断Hystrix
2021.07.13 [station B] collapsed like this
3438. Number system conversion
Unveil the mystery of service grid istio service mesh
[flask introduction series] request hook and context
实习是步入社会的一道坎
Top domestic experts gathered in Guangzhou to discuss the safety application of health care data
P1004 [NOIP2000 提高组] 方格取数
国科大. 深度学习. 期末试题与简要思路分析
人脸技术:不清楚人照片修复成高质量高清晰图像框架(附源代码下载)
ORA-00054
Behind the high salary of programmers' operation and maintenance
Natural language processing model of bigscience open source bloom
买股票开户应该选哪个证券公司?什么证券公司是更安全的
2020 ICPC Asia East Continent Final G. Prof. Pang‘s sequence 线段树/扫描线
Read the paper: temporary graph networks for deep learning on dynamic graphs