Architecture Patterns with Python (TDD, DDD, EDM)
- 도메인 계층 테스트
def test_prefers_current_stock_batches_to_shipments():
in_stock_batch = Batch("in_stock_batch", "RETRO-CLOCK", 100, eta=None)
shipment_batch = Batch("shipment-batch", "RETRO-CLOCK", 100, eta=tomorrow)
line = OrderLine("oref", "RETRO-CLOCK", 10)
allocate(line, [in_stock_batch, shipment_batch])
assert in_stock_batch.available_quantity == 90
assert shipment_batch.available_quantity == 100- 서비스 계층 테스트
def test_prefers_warehouse_batches_to_shipments():
in_stock_batch = Batch("in-stock-batch", "RETRO-CLOCK", 100, eta=None)
shipment_batch = Batch("shipment-batch", "RETRO-CLOCK", 100, eta=tomorrow)
repo = FakeRepository([in_stock_batch, shipment_batch])
session = FakeSession()
line = OrderLine('oref', "RETRO-CLOCK", 10)
services.allocate(line, repo, session)
assert in_stock_batch.available_quantity == 90
assert shipment_batch.available_quantity == 100왜 도메인 계층의 테스트가 아닌 서비스 계층 테스트로 해야할까?
- 시스템을 바꾸는 데 어렵지 않다.
- 서비스 계층은 시스템을 다양한 방식으로 조정할 수 있는 API를 형성한다.
- 서비스 테스트에는 도메인 모델에 대한 의존성이 있다. 테스트 데이터를 설정하고 서비스 계층 함수를 호출하기 위해 도메인 객체를 사용하기 때문이다.
- API를 원시 타입만 사용하도록 다시 작성한다.
# 이전 allocate는 도메인 객체를 받았다.
def allocate(line: OrderLine, repoL AbstractRepository, session) -> str:
# 도메인 의존성을 줄이기 위해 문자열과 정수를 받는다. -> 원시 타입만 사용!
def allocate(orderid: str, sku: str, qty: int, repo:AbstractRepository, session) -> str:- ex) 직접 Batch 객체를 인스턴스화하므로 여전히 도메인에 의존하고 있다. 나중에 Batch 모델의 동작을 변경하면 수많은 테스트를 변경해야하기에 적합하지 않다.
def test_returns_allocation():
batch = model.Batch("batch1", "Coplicated-lamp", 100, eta=None)
repo = FakeRepository([batch])
result = services.allocate("o1", "Coplicated-lamp", 10, repo, FakeSession())
assert result == "batch1"###5.5.1 위 예시에 대한 해결책 - 마이그레이션: 모든 도메인 의존성을 픽스처 함수에 넣기
- FakeRepository에 팩토리 함수를 추가하여 추상화를 달성하는 방법 => 도메인 의존성을 한 군데로 모을 수 있다.
class FakeRepository(set):
@staticmethod
def for_batch(ref, sku, qty, eta=None):
return FakeRepository([
model.Batch(ref, sku, qty, eta)
])
...
def test_returns_allocation(self):
repo = FakeRepository.for_batch("batch1", "Complicated-lamp", 100, eta=None)
result = services.allocate("o1", "Complicated-lamp", 10, repo, FakeSession())
assert result == "batch1"###5.5.2 예시 해결책: 누락된 서비스 추가
- 재고를 추가하는 서비스가 있다면 이 서비스를 사용해 온전히 서비스 계층의 공식적인 유스 케이스만 사용하는 서비스 계층 테스트를 작성할 수 있다.
tip: 일반적으로 서비스 계층 테스트에서 도메인 계층에 있는 요소가 필요하다면 이는 서비스 계층이 완전하지 않다는 사실이다.
def test_add_batch():
repo, session = FakeSession([]), FakeSession()
services.add_batch("b1", "Crunchy-armchair", 100, None, repo, session)
assert repo.get("b1") is not None
assert session.committed- 서비스 계층 테스트가 오직 서비스 계층에만 의존하기 때문에 얼마든지 필요에 따라 모델을 리팩터링할 수 있다.
def test_allocate_returns_allocation():
repo, session = FakeRepository([]), FakeSession()
services.add_batch("batch1", "COMPLICATED-LAMP", 100, None, repo, session)
result = services.allocate("o1", "COMPLICATED-LAMP", 10, repo, session)
assert result == "batch1"
def test_allocate_errors_for_invalid_sku():
repo, session = FakeRepository([]), FakeSession()
services.add_batch("b1", "AREALSKU", 100, None, repo, session)
with pytest.raises(services.InvalidSku, match="Invalid sku NONEXISTENTSKU"):
services.allocate("o1", "NONEXISTENTSKU", 10, repo, FakeSession())- 서비스 함수 덕에 엔드포인트를 추가하는 것이 쉬워졌다 JSON을 약간 조작하고 함수를 한 번 호출하면 된다.
@app.route("/add_batch", methods=['POST'])
def add_batch():
session = get_session()
repo = repository.SqlAlchemyRepository(session)
eta = request.json["eta"]
if eta is not None:
eta = datetime.fromisoformat(eta).date()
# JSON 조작 함수 한번 호출
services.add_batch(
request.json["ref"],
request.json["sku"],
request.json["qty"],
eta,
repo,
session,
)
return "OK", 201
@app.route("/allocate", methods=["POST"])
def allocate_endpoint():
session = get_session()
repo = repository.SqlAlchemyRepository(session)
try:
# JSON 조작 함수 한번 호출
batchref = services.allocate(
request.json["orderid"],
request.json["sku"],
request.json["qty"],
repo,
session,
)
except (model.OutOfStock, services.InvalidSku) as e:
return {"message": str(e)}, 400
return {"batchref": batchref}, 201-
특성당 엔드투엔드 테스트를 하나씩 만든다는 목표를 세워야 한다.
- 예를 들어 이런 테스트는 HTTP API를 사용할 가능성이 높다. 목표는 어떤 특성이 잘 작동하는지 보고 움직이는 모든 부품이 서로 잘 연결되어 움직이는지 살펴보는 것이다.
-
테스트 대부분은 서비스 계층을 만드는 걸 권한다.
- 이런 테스트는 커버리지, 실행 시간, 효율 사이를 잘 절충할 수 있게 해준다. 각 테스트는 어떤 기능의 한 경로를 테스트하고 I/O에 가짜 객체를 사용하는 경향이 있다. 이 테스트는 모든 에지 케이스를 다루고, 비즈니스 로직의 모든 입력과 출력을 테스트해볼 수 있는 좋은 장소다.
-
도메인 모델을 사용하는 핵심 테스트를 적게 작성하고 유지하는 걸 권한다.
- 이런 테스트는 좀 더 커버리지가 작고(좁은 범위를 테스트), 더 깨지기 쉽다. 하지만 이런 테스트가 제공하는 피드백이 가장 크다. 이런 테스트를 나중에 서비스 계층 기반 테스트로 대신할 수 있다면 테스트를 주저하지 말고 삭제하는 것을 권한다.
-
오류 처리도 특성으로 취급하자.
- 이상적인 경우 애플리케이션은 모든 오류가 진입점(예: 플라스크)으로 거슬러 올라와서 처리되는 구조로 되어 있다. 단지 각 기능의 정상 경로만 테스트하고 모든 비정상 경로를 테스트하는 엔드투엔드 테스트를 하나만 유지하면 된다는 의미다(물론 비정상 경로를 테스트하는 단위 테스트가 많이 있어야 한다.).
작업 단위 패턴? 저장소와 서비스 계층 패턴을 하나로 묶어 주는 패턴
저장소패턴 - 영속적 저장소 개념에 대한 추상화
작업 단위 패턴 - 원자적 연산(atomic operation)의 추상화
- UoW가 없는 경우: API는 세 가지 계층과 직접 대화 가능

- UoW가 있는 경우: 이제 UoW가 데이터베이스 상태 관리
- 플라스크의 일: 작업 단위 초기화, 서비스를 호출
- 서비스는 UoW와 협력하지만 서비스 함수 자체나 플라스크는 이제 데이터베이스와 직접 대화하지 않는다.
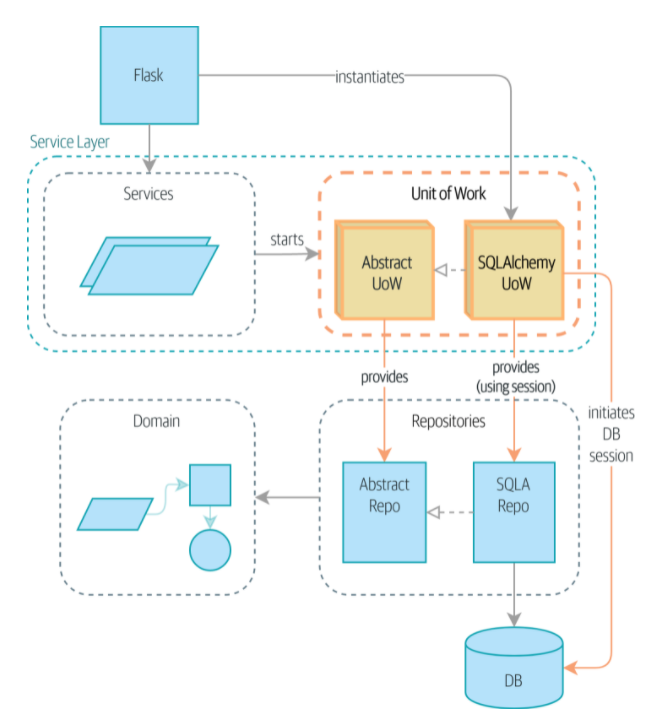
- 작업 단위가 작동하는 모습 예시
def allocate(orderid: str, sku: str, qty: int, uow: unit_of_work.AbstractUnitOfWork) -> str:
line = OrderLine(orderid, sku, qty)
with uow: # 콘텍스트 관리자로 UoW를 시작한다. => 영속적 저장소에 대한 단일 진입점 -> 어떤 객체가 메모리에 적재됐고 어떤 객체가 최종 상태인지를 기억한다.
batches = uow.batches.list() # uow.batches는 배치 저장소다. 따라서 UoW는 영속적 저장소에 대한 접근을 제공한다.
...
uow.commit() # 작업이 끝나면 UoW를 사용해 커밋하거나 롤백한다.- 작업 단위 사용의 장점
- 작업에 사용할 데이터베이스의 안정적 스냅샷을 제공, 연산을 진행하는 과정에서 변경하지 않은 객체에 대한 스냅샷도 제공
- 변경 내용을 한번에 영속화할 방법 제공, 어딘가 잘못되더라도 일관성이 없는 상태로 끝나지 않는다.
- 영속성을 처리하기 위한 간단한 API와 저장소를 쉽게 얻을 수 있는 장소를 제공한다.
def test_uow_can_retrieve_a_batch_and_allocate_to_it(session_factory):
session = session_factory()
insert_batch(session, 'batch1', 'HIPSTER-WORKBENCH', 100, None)
session.commit()
uow = unit_of_work.SqlAlchemyUnitOfWork(session_factory) # 커스텀 세션 팩토리를 사용해 UoW를 초기화하고 블록 안에서 사용할 uow 객체를 얻는다.
with uow:
batch = uow.batches.get(reference='batch1') # uow는 uow.batches를 통해 배치 저장소에 대한 접근을 제공
line = model.OrderLine('o1', 'HIPSTER-WORKBENCH')
uow.commit() # 작업 후 commit
batchref = get_allocated_batch_ref(session, 'o1', 'HIPSTER-WORKBENCH')
assert batchref == 'batch1'추상 기반 클래스 인터페이스
class AbstractUnitOfWork(abc.ABC):
batches: repository.AbstractRepository
def __exit__(self, *args):
self.rollback()
@abc.abstractmethod
def rollback(self):
raise NotImplementedError
@abc.abstractmethod
def commit(self):
raise NotImplementedErrorDEFAULT_SESSION_FACTORY = sessionmaker(bine=create_engine(
config.get_postgres_uri()
))
class SqlAlchemyUnitOfWork(AbstractUnitOfWork):
def __init__(self, session_factory=DEFAULT_SESSION_FACTORY):
self.session_factory = session_factory
def __enter__(self): # 데이터베이스 세션 시작하고 이 데이터베이스 세션을 사용할 실제 저장소를 인스턴스화한다.
self.session = self.session_factory()
def __exit__(self, *args):
super().__exit__(*args)
self.session.close()
def commit(self):
self.session.commit()
def rollback(self):
self.session.rollback()FakeUnitOfWork는 FakeSession에서 진행하던 commited 기능과 저장소의 기능을 아우른다.
class FakeUnitOfWork(unit_of_work.AbstractUnitOfWork):
def __init__(self):
# FakeUnitWork와 FakeRepository는 실제 UnitofWork와 Repository 클래스가 결합되어 있는 것처럼 밀접하게 결합되어 있다. 이 객체들은 협렵자라고 인식하므로 문제가 되지 않는다.
self.batches = FakeRepository([])
self.committed = False
def commit(self):
self.committed = True
def rollback(self):
pass
def test_add_batch():
# 테스트에서는 UoW를 인스턴스화하고, 서비스 계층에 저장소와 세션을 넘기는 대신 인스턴스화한 UOW를 넘길 수 있다. 이런 구조는(저장소와 세션을 넘기는 것보다)훨씬 덜 번거롭다.
uow = FakeUnitOfWork()
services.add_batch("b1", "CRUNCHY-ARMCHAIR", 100, None, uow)
assert uow.batches.get("b1") is not None
assert uow.committed
def test_allocate_returns_allocation():
uow = FakeUnitOfWork()
services.add_batch("batch1", "COMPLICATED-LAMP", 100, None, uow)
result = services.allocate("o1", "COMPLICATED-LAMP", 10, uow)
assert result == "batch1"세션보다 UoW를 모킹하는 것이 더 편한 이유는 무엇인가?
- 실제 데이터베이스를 사용하지 않고도 메모리상에서 테스트를 진행할 수 있게 해준다.
- 실행이 빠른 테스트를 만들고 싶다면? SQLAlchemy 대신 mock을 만들고, 코드베이스 전체에 적용한다.
- service 계층에서의 의존성은 UoW 추상화 하나뿐이다. (이전까지는 repository와 session에 대한 의존성이 존재했다.)
def add_batch(
ref: str, sku: str, qty: int, eta: Optional[date],
uow: unit_of_work.AbstractUnitOfWork,
):
with uow:
uow.batches.add(model.Batch(ref, sku, qty, eta))
uow.commit()
def allocate(orderid: str, sku: str, qty: int, uow: unit_of_work.AbstractUnitOfWork) -> str:
line = OrderLine(orderid, sku, qty)
with uow: # 콘텍스트 관리자로 UoW를 시작한다. => 영속적 저장소에 대한 단일 진입점 -> 어떤 객체가 메모리에 적재됐고 어떤 객체가 최종 상태인지를 기억한다.
batches = uow.batches.list() # uow.batches는 배치 저장소다. 따라서 UoW는 영속적 저장소에 대한 접근을 제공한다.
if not is_valid_sku(line.sku, batches):
raise InvalidSku('Invalid sku {line.sku}')
batchref = model.allocate(line, batches)
uow.commit() # 작업이 끝나면 UoW를 사용해 커밋하거나 롤백한다.
return batchrefdef test_rolls_back_uncommitted_work_by_default(session_factory):
uow = unit_of_work.SqlAlchemyUnitOfWork(session_factory)
with uow:
insert_batch(uow.session, "batch1", "MEDIUM-PLINTH", 100, None)
new_session = session_factory()
rows = list(new_session.execute('SELECT * FROM "batches"'))
assert rows == []
def test_rolls_back_on_error(session_factory):
class MyException(Exception):
pass
uow = unit_of_work.SqlAlchemyUnitOfWork(session_factory)
with pytest.raises(MyException):
with uow:
insert_batch(uow.session, "batch1", "LARGE-FORK", 100, None)
raise MyException()
new_session = session_factory()
rows = list(new_session.execute('SELECT * FROM "batches"'))
assert rows == []- UoW 패턴: 디폴트로 결과를 커밋하고 예외가 발생한 경우에만 롤백 수행
def __enter__(self):
return self
def __exit__(self, exn_type, exm_value, traceback):
if exn_type:
self.commit()
else:
self.rollback()- UoW를 사용하면 클라이언트 코드에서 명시적인 커밋을 생략해 코드 한 줄을 줄일 수 있다.(기존 코드에서 commit 부분 제거)
- 아래 예제를 통해 UoW 사용하면 코드 블록에서 벌어지는 일에 대한 추론이 간단해 짐을 알 수 있다.
def reallocate(line: OrderLine, uow: unit_of_work.AbtractUnitOfWork) -> str:
with uow:
batch = uow.batches.get(sku=line.sku)
if batch is None:
raise InvalidSku('Invalid sku {line.sku}')
# 실제로 Uow에 예외 커밋 조건을 설정하여 실패했을 경우 커밋이 진행되지 않는다.
batch.deallocate(line) # deallocate() 가 실패하면 당연히 allocate()를 호출하는 걸 원치 않는다.
allocate(line) # 실제로 allocate()가 실패한다면 deallocate()한 결과만 커밋하고 싶지는 않을것이다.
uow.commit()
def change_batch_quantity(batchref: str, new_qty: int, uow: AbstractUnitOfWork):
with uow:
batch = uow.batches.get(reference=batchref)
batch.change_purchased_quantity(new_qty)
while batch.available_quantity < 0:
line = batch.deallocate_one()
uow.commit() -
작업 단위 패턴은 데이터 무결성 중심 추상화다.
- 작업 단위 패턴을 사용하면 연산의 끝에 플러시 연산을 한 번만 수행해 도메인 모델의 일관성을 강화하고 성능을 향상시킬 때 도움이 된다.
-
작업 단위 패턴은 저장소와 서비스 꼐층 패턴과 밀접하게 연관되어 작동한다.
- 작업 단위 패턴은 원자적 업데이트를 표현해 데이터 접근에 대한 추상화를 완성시켜준다. 서비스 계층의 유스 케이스들은 각각 블록단위로 성공하거나 실패하는 별도의 작업 단위로 실행된다.
-
콘텍스트 관리자를 사용하는 멋진 유스 케이스다.
- 콘텍스트 관리자는 파이썬에서 영역을 정의하는 전형적인 방법이다. 콘텍스트 관리자를 사용해 요청 처리가 커밋을 호출하지 않고 끝나면 자동으로 작업을 롤백할 수 있다. 이런 식으로 구현하면 시스템은 기본적으로 항상 안전한 상태가 된다.
-
SQLAlchemy는 이미 작업 단위 패턴을 제공한다.
- SQLAlchemy Session 객체를 더 간단하게 추상화해서 ORM과 코드 사이의 인터페이스를 더 좁힌다. 이렇게 하면 코드의 각 부분의 결합을 느슨하게 유지할 수 있다.