当前位置:网站首页>What is the relationship between softmax and cross enterprise?
What is the relationship between softmax and cross enterprise?
2022-07-19 12:22:00 【Xiaobai learns vision】
Click on the above “ Xiaobai studies vision ”, Optional plus " Star standard " or “ Roof placement ”
Heavy dry goods , First time delivery come from | You know author | Dong Xin
https://www.zhihu.com/question/294679135/answer/885285177
This article is only for academic sharing , The copyright belongs to the author , If there is any infringement , Please contact to delete

softmax Simple though , But in fact, there are many details worth mentioning .
Let's go through them one by one .
1. What is? Softmax?
First ,softmax Its function is to turn A sequence , Become probability .


He can guarantee that :
All values are [0, 1] Between ( Because the probability has to be [0, 1])
All the values add up to 1
Explain in terms of probability softmax Words , Namely

2. The document says Softmax The relevant pit
Here's a little bit of “ Small pit ”, quite a lot deep learning frameworks Of file Inside (PyTorch,TensorFlow) It's like this softmax Of ,
take logits and produce probabilities
Obviously , Inside logits Namely Fully connected layer ( With or without activation Fine ) Output , probability Namely softmax Output result of . here logits In some places it is also called unscaled log probabilities. This is very interesting ,unscaled probability You can understand , Then why The full connection layer comes out directly, and the result will be with log It matters ?

There are two reasons :
because Fully connected layer The result , It's actually boundless ( There are positive and negative ), This is not consistent with the definition of probability , But if you look at him as Probabilistic log, You can understand .
softmax The role of , We all know it's normalize probability. stay softmax Inside , Input
 It's all exponential , All of them Think about it log of probability It's natural that .
It's all exponential , All of them Think about it log of probability It's natural that .
3. Softmax Namely Soft Version of ArgMax
well , Let's get back to softmax.
softmax, As the name suggests, it is soft Version of argmax. Let's see why ?
Take a chestnut , If softmax The input is :
softmax The result is :
Let's change the input a little bit , hold 3 Make it bigger , become 5, Input is
softmax The result is :
so softmax It's a very obvious “ Matthew effect ”: strong ( Big ) It's stronger ( Big ), weak ( Small ) Is weaker ( Small ). If you want to pick the largest number , This is actually called hardmax. that softmax Well , In fact, it's really soft Version of max, Choose a maximum value with a certain probability . stay hardmax in , The really biggest number , Must be based on 1(100%) The probability of being chosen , Other values have no chance at all . But in softmax in , All values have a chance to be selected as the maximum value . It's just , because softmax Of “ Matthew effect ”, The next largest number , Even if it's very little different from the really biggest number , It's much smaller than the real maximum number in probability .
therefore , I said before ,“softmax Its function is to turn A sequence , Become probability .” This probability is nothing else , It was chosen as max Probability .
such soft Version of max It's useful in many places . because hard Version of max Good is good , But there's a very serious gradient problem , The gradient of the function itself is very, very sparse ( For example, in neural networks max pooling), after hardmax after , Only the selected variable has a gradient on it , Everything else has no gradient . This is for some tasks ( Such as text generation ) It's almost unacceptable . So either use hard max Variants , such as Gumbel,
Categorical Reparameterization with Gumbel-Softmax
link :https://arxiv.org/abs/1611.01144
Or is it ARSM
ARSM: Augment-REINFORCE-Swap-Merge Estimator for Gradient Backpropagation Through Categorical Variable
link :http://proceedings.mlr.press/v97/yin19c.html
, Or directly softmax.
4. Softmax And numerical stability
softmax The implementation of the code seems to be relatively simple , It's a direct formula
def softmax(x):
"""Compute the softmax of vector x."""
exps = np.exp(x)
return exps / np.sum(exps)But this method is very unstable . Because this method is exponential , As long as your input is a little bit larger , such as :
The denominator is
Obviously , There's bound to be overflow in computation . The solution is simple , That is, we multiply the numerator and denominator by a coefficient , Reduce the value size , And make sure the whole thing is right

Put the constant C Absorb into the index
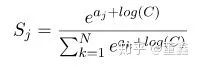
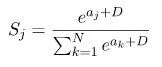
there D It's optional , Generally, you can choose

The concrete implementation can be written as follows
def stablesoftmax(x):
"""Compute the softmax of vector x in a numerically stable way."""
shiftx = x - np.max(x)
exps = np.exp(shiftx)
return exps / np.sum(exps)Such an approach to numerical stability is much better , But there are still problems with numerical stability . For example, when the input values are too different , such as
In this case, the above method is used , Maybe it's still a newspaper NaN Error of . But this is the problem of mathematics itself , Please pay attention to it when you use it .
One possible alternative is to use LogSoftmax ( And then ask exp), Numerical stability ratio softmax Better .
You can see , It saves an index calculation , It saves a division , The numerical value is relatively stable . in addition , Actually LogSoftmax That's how it works in it Softmax_Cross_Entropy
5. Softmax Gradient of
So let's see softmax The gradient problem of . Whole softmax The operations inside are differentiable , So the gradient is very simple , It's the derivation formula of the basis , Here's the result .


So , If a variable is done softmax And then it was very small , such as , So his gradient is very small , There's almost no gradient . Sometimes , This causes the gradient to be very sparse , Optimization does not move .
6. Softmax and Cross-Entropy The relationship between
Say first conclusion ,
softmax and cross-entropy It was a big relationship , If you just put the two together , It's faster to count , And more numerically stable .
cross-entropy It's not a unique concept of machine learning , Essentially, it's used to measure the similarity between two probability distributions . Simple understanding ( It's just a simple understanding of !) this is it ,
If you have two sets of variables :
If you ask for L2 distance , It's a long way to go , But you do it to these two cross entropy, So the distance is 0. therefore cross-entropy In fact, it is more “ flexible ” some .
So we know ,cross entropy Is used to measure the distance between two probability distributions ,softmax It turns everything into a probability distribution , So naturally, the two are often used together . But you just need to deduce , You will find ,softmax + cross entropy It's like
“ Five meters east , Another ten meters to the West ”,
Why don't we just
“ Five meters to the West ” Well ?
cross entropy The formula is

there That's what we said earlier LogSoftmax. This thing is compared to softmax It's easy to calculate , The numerical stability is a little better , Why not count him directly ?
So , This has PyTorch Inside torch.nn.CrossEntropyLoss ( Input is what we talked about earlier logits, That is to say Everything that comes directly out of the connection ). This CrossEntropyLoss In fact, it is equal to torch.nn.LogSoftmax + torch.nn.NLLLoss.
The good news !
Xiaobai learns visual knowledge about the planet
Open to the outside world

download 1:OpenCV-Contrib Chinese version of extension module
stay 「 Xiaobai studies vision 」 Official account back office reply : Extension module Chinese course , You can download the first copy of the whole network OpenCV Extension module tutorial Chinese version , Cover expansion module installation 、SFM Algorithm 、 Stereo vision 、 Target tracking 、 Biological vision 、 Super resolution processing and other more than 20 chapters .
download 2:Python Visual combat project 52 speak
stay 「 Xiaobai studies vision 」 Official account back office reply :Python Visual combat project , You can download, including image segmentation 、 Mask detection 、 Lane line detection 、 Vehicle count 、 Add Eyeliner 、 License plate recognition 、 Character recognition 、 Emotional tests 、 Text content extraction 、 Face recognition, etc 31 A visual combat project , Help fast school computer vision .
download 3:OpenCV Actual project 20 speak
stay 「 Xiaobai studies vision 」 Official account back office reply :OpenCV Actual project 20 speak , You can download the 20 Based on OpenCV Realization 20 A real project , Realization OpenCV Learn advanced .
Communication group
Welcome to join the official account reader group to communicate with your colleagues , There are SLAM、 3 d visual 、 sensor 、 Autopilot 、 Computational photography 、 testing 、 Division 、 distinguish 、 Medical imaging 、GAN、 Wechat groups such as algorithm competition ( It will be subdivided gradually in the future ), Please scan the following micro signal clustering , remarks :” nickname + School / company + Research direction “, for example :” Zhang San + Shanghai Jiaotong University + Vision SLAM“. Please note... According to the format , Otherwise, it will not pass . After successful addition, they will be invited to relevant wechat groups according to the research direction . Please do not send ads in the group , Or you'll be invited out , Thanks for your understanding ~边栏推荐
- How to apply applet container technology to develop hybrid app
- 熟悉NestJS (新手篇)
- Mysql学习笔记-分页-表的创建-数据类型
- [shutter] dart: some features that cannot be ignored
- Nature子刊 | 地下水固碳速率与寡营养海洋系统固碳速率相近
- Project construction depends on people, and success depends on people!
- Gradient button function button drawing C language example
- C language drawing example - trademark logo
- Application of semi supervised learning in malware traffic detection
- 2022安全员-C证上岗证题目及答案
猜你喜欢







随机推荐
mysql学习笔记-约束
【C语言编程7】BTB模型
Day 1 Experiment
GET 请求和 POST 请求的区别与使用示例
C语言绘图示例-分色调图20例
RAID 磁盘阵列详解,RAID分类及优缺点
How to delay loading JS
rman异机恢复报错RMAN-06026 RMAN-06023
HCIP(6)
Machine learning (I) Wu enda
Understanding of rapid exploring random trees (RRT) path planning method
解决:code ERESOLVE:ERESOLVE could not resolve 的报错问题
WAV和PCM的关系和区别
psd.js 解析PSD文件
Core base station_ The error "no gateways configured" is reported when starting the CPA file
Hcip fourth day notes
Genesis与BlueRun Ventures展开深度交流
getchar()
Overview of the application of air, space and sea Association
Configuring OSPF experiment in mGRE environment