当前位置:网站首页>OD-Paper【2】:Fast R-CNN
OD-Paper【2】:Fast R-CNN
2022-07-26 05:20:00 【zzzyzh】
List of articles
Target detection RCNN:
OD-Paper【1】:Rich feature hierarchies for accurate object detection and semantic segmentation
List of articles
Preface
This paper mainly interprets the paper , And explain about Fast RCNN Part of the frame
1. Abstract & Introduction
1.1. Abstract
In this paper, a fast region based convolution network method is proposed (Fast R-CNN) For target detection .Fast R-CNN It is based on the achievement that the previously used deep convolution network effectively classifies targets . Compared with previous research work ,Fast R-CNN A number of innovations have been adopted to improve the speed of training and testing , At the same time, it also improves the detection accuracy .
1.2. Introduction
The complexity arises because detection requires accurate positioning of the target , This leads to two main difficulties . First , A large number of candidate target locations must be processed ( Often referred to as “proposals”). second , These candidate boxes only provide rough positioning , It must be refined to achieve precise positioning . Solutions to these problems often affect speed 、 Accuracy or brevity .
In this paper , We simplify the training process of the most advanced target detector based on convolution network . We propose a single-stage training algorithm , Joint learning candidate box classification and correction of their spatial position .
1.2.1. R-CNN and SPPnet
Region based convolution network method (RCNN) Target candidate boxes are classified by using a deep convolution network , High target detection accuracy is obtained . However ,R-CNN Has obvious disadvantages :
- The training process is multi-level pipeline.R-CNN First, use the target candidate box to convolutional neural network log The loss is fine-tunes. then , It sends the features obtained by convolution neural network into SVM. these SVM As a target detector , Replace by fine-tunes Study of the softmax classifier . In the third training phase , Study bounding-box Regressor .
- Training costs a lot of time and space . about SVM and bounding-box Back to training , Extract features from each target candidate box in each image , And write to disk . about VOC07 trainval Upper 5k Images , Use as VGG16 Very deep network , This process is in a single GPU Upper needs 2.5 God . These features require hundreds of GB Storage space .
- Target detection speed is very slow . At testing time , Extract features from each target candidate box in each test image . use VGG16 When the network detects the target , Each image needs 47 second ( stay GPU On ).
R-CNN It is slow because it performs convolutional neural network forward transfer for each target candidate frame , Without shared computing .SPPnet The Internet [11] It is proposed to accelerate R-CNN.SPPnet Calculate the convolution feature of the whole input image , Then use the feature vector extracted from the shared feature map to classify each candidate box . By maximizing the pool, the feature map in the candidate box is transformed into a fixed size output ( for example 6×6) To extract features for candidate boxes . Multiple output sizes are pooled , Then connected into a spatial pyramid pool .SPPnet During the test R-CNN Speed up 10 To 100 times . Due to faster candidate Box feature extraction , Training time is also reduced 3 times .
SPP The Internet also has significant disadvantages . image R-CNN equally , The training process is a multi-level pipeline, It involves extracting features 、 Use log The loss of the network fine-tuning、 Training SVM Classifier and final fitting detection frame regression . Features are also written to disk . But with R-CNN Different ,fine-tuning The algorithm cannot update the convolution layer before the spatial pyramid pool . It is as expected , This limitation ( Fixed convolution layer ) It limits the accuracy of deep network .
1.2.2. Contributions
This paper presents a new training algorithm , Fixed a R-CNN and SPPnet The shortcomings of , At the same time, the speed and accuracy are improved . Because it can train and test faster , We call it Fast R-CNN.Fast RCNN The method has the following advantages :
- Than R-CNN and SPPnet It has higher target detection accuracy (mAP)
- Training is a single-stage training using multitasking loss
- Training can update all network layer parameters
- No need for disk space caching features
2. Fast R-CNN architecture and training
2.1. Algorithm process
Fast R-CNN The algorithm flow can be divided into 3 A step :
- One image generation 1000~2000 individual candidate region ( Use Selective Search Method )
- Input the image into the network to get the corresponding Characteristics of figure , take SS The generated feature is projected onto the corresponding candidate graph Characteristic matrix
- Pass each characteristic matrix through ROI(Region of Interest) pooling Layer shrink to 7 x 7 A feature map of size , Then flatten the feature map and get the prediction result through a series of fully connected layers

2.2. Architecture

2.2.1. Calculating image features
Calculate the whole image feature at one time
R-CNN The candidate box regions are input into convolutional neural network in turn to obtain features
- obtain SS The algorithm gets 2000 Candidate box , It needs to be done 2000 Secondary forward propagation
- There's a lot of redundancy
- The overlapping part can be calculated once

- obtain SS The algorithm gets 2000 Candidate box , It needs to be done 2000 Secondary forward propagation
Fast-RCNN Send the whole image to the network , Next, the corresponding candidate regions are extracted from the feature image . The characteristics of these candidate regions There is no need to double calculate
- Reference resources SPPNet
- From each candidate area , Through the mapping relationship between the original graph and the feature graph , Obtain the characteristic matrix on the characteristic graph
- Avoid double counting of candidate regions
- In fact, it means RCNN The first step of and part of the second part merge
- To calculate feature map, Again from feature map Middle selection , Save a space

2.2.2. Mini-batch sampling
Sampling of training data
- Positive sample
The candidate box does exist , Sample of the target to be detected - Negative sample
background , There is no target we want to detect - Classification reason
Suppose a cat and dog classifier is trained at this time , The number of samples of cats is much larger than that of dogs , That is, when the data is unbalanced , The network will be more inclined to cats in the process of prediction , But it's not right . More extreme , If there are only cats in the data set , The result of the prediction will be obviously wrong .- If only positive samples are trained in the network , Then the network will have a great probability , Think our candidate area is the target we need to detect , Even if the box is just a background , It will also think that that is the target we need to detect
- It can be understood as , Because the sample is uneven , Lead to some features that are not the targets to be classified , Be mistaken by the network for the characteristics of the target and train
During the fine-tuning period , Every SGD The small batch is made up of N=2 One image constitutes , Choose evenly and randomly ( As usual , We actually iterate the arrangement of data sets ). We use a size of R=128 A small batch of , For each picture , from 2000 In the candidate boxes , collection 64 Candidate areas (RoI). As long as the candidate box and the target bounding box of the truth value IoU Greater than 0.5, It is considered that the candidate box is a positive sample . Of course , Not all positive samples are used , But from the positive sample Random sampling Part of the . these RoI Include only samples marked with foreground object classes , namely u ≥ 1 u\ge 1 u≥1. remainder RoI From the candidate box Random sampling , The maximum of the true value of the candidate box and the detection box IoU In the interval [0.1, 0.5]. These are background samples , The negative samples , And use u=0 Mark . The next threshold is set to 0.1 Why , It is acquisition and reality bounding box The cross and merge ratio is at least 0.1 Of RoI Negative sample , That is, there is a certain overlap with the real goal , Negative samples that can make model learning more difficult .
2.2.3. The RoI pooling layer
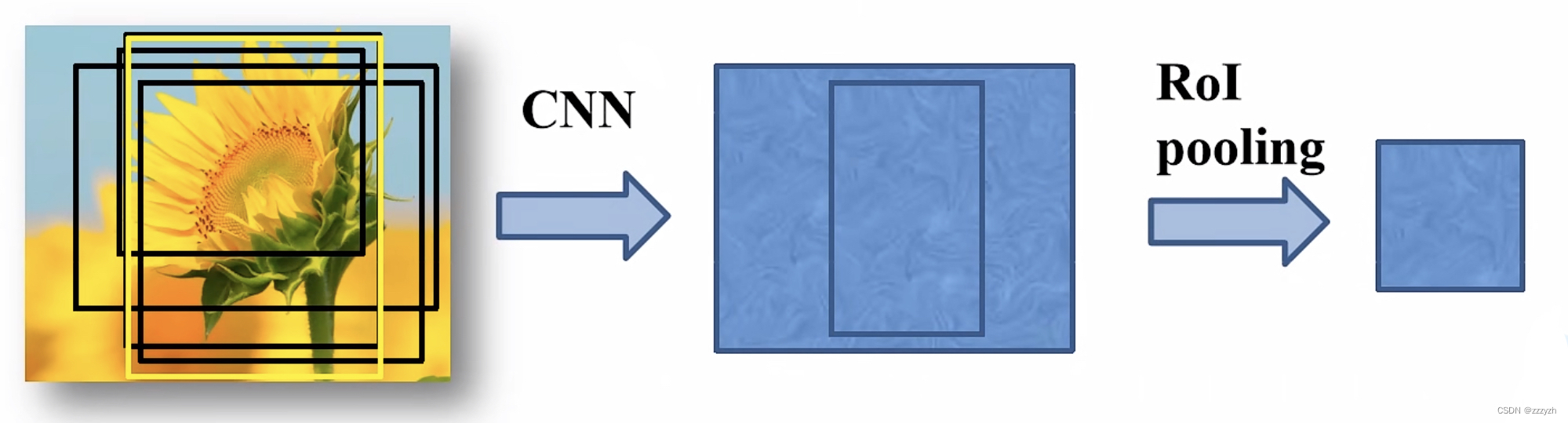
After obtaining training samples , Pass the candidate box for training samples through RoI pooling layer , Zoom to a uniform size
for instance , After simplifying the characteristic matrix of a picture , As shown in the figure below :
Divide each picture into 7 x 7 = 49 Equal parts , For each equally divided pixel block max pooling, Get one 7 x 7 Characteristic matrix of size ( At this time, the depth is ignored channel), be-all channel Do the same thing . The advantage of this is , The size of the input image is not limited .
2.2.4. Classifier
Output N+1 The probability of categories (N For the type of detection target ,1 In the background , common N+1 Nodes 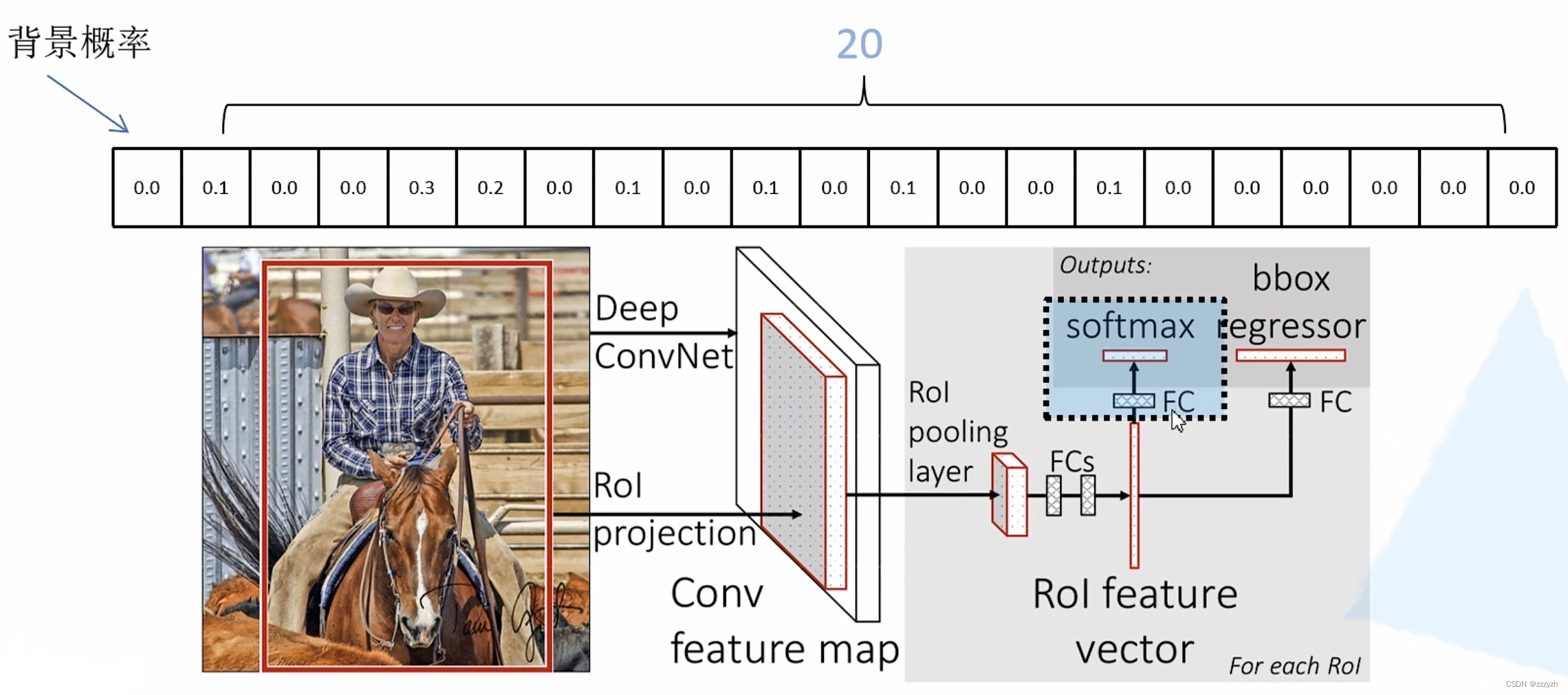
Input a picture into CNN In the network , Get one feature map, According to the mapping , You can find the characteristic matrix corresponding to each box , Pass the characteristic matrix through RoI pooling Shrink the layer to a specified size . after , Make the matrix flatten Handle , After passing through two full connection layers RoI feature vector, On the basis of this vector , Connect two fully connected layers in parallel . The first channel is used to predict the target probability .
here , adopt softmax To deal with , Output the probability of corresponding target ( And the output value satisfies the probability distribution , And for 1)
2.2.5. Bounding box regression
Output the corresponding N+1 Candidate bounding box regression parameters for categories ( d x , d y , d w , d h ) (d_x, d_y, d_w, d_h) (dx,dy,dw,dh), common (N+1) x 4 Nodes

Be careful , Every category has 4 Parameters : The center point of the goal suggestion box x Offset 、y Offset , Scaling factor of bounding box Height 、 Width scaling factor . Through this 4 Parameters , You can use the following formula , Get the corresponding bounding box :

2.2.5. Multi-task loss

- p p p It is predicted by the classifier softmax A probability distribution : p = ( p 0 , . . . , p k ) p = (p_0, ..., p_k) p=(p0,...,pk)
- u u u Corresponding to the target real category label

- p u p_u pu That is, the classifier predicts that the current candidate region is a category u u u Probability
- Cross Entropy Loss Cross entropy loss
- For the multi classification problem (softmax Output , The sum of all output probabilities is 1)

- For the problem of two categories (sigmoid Output , Each output node is irrelevant to each other )

- o i ∗ o_i^* oi∗ Only in the correct label position is 1, Other positions are 0(one-hot code )
- So at this time H = − 1 × l o g ( u ) H = -1 \times log(u) H=−1×log(u) , That is, the corresponding classification loss
- For the multi classification problem (softmax Output , The sum of all output probabilities is 1)
- t u t^u tu The corresponding category predicted by the corresponding bounding box regressor u u u Regression parameters of ( t x u , t y u , t w u , t h u ) (t_x^u, t_y^u, t_w^u, t_h^u) (txu,tyu,twu,thu)
- v v v Bounding box regression parameters corresponding to real targets ( v x , v y , v w , v h ) (v_x, v_y, v_w, v_h) (vx,vy,vw,vh)
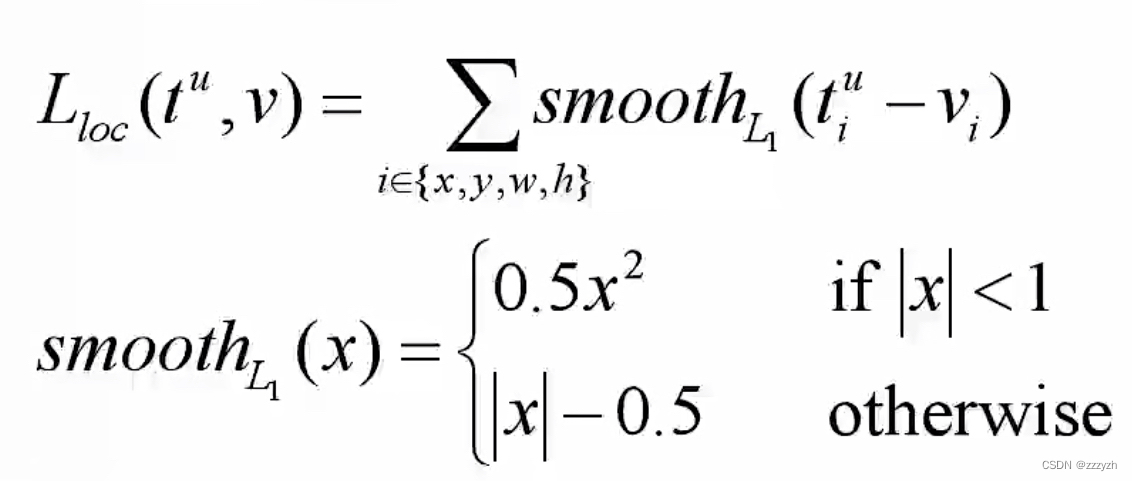
- [ u ≥ 1 ] [u \ge 1] [u≥1] It's Iverson
- If the conditions in brackets are met , The value is 1, Dissatisfaction is 0
- u It is the real label of the target to be detected
- u ≥ 1 u \ge 1 u≥1 It indicates that the candidate area belongs to a category to be detected , Corresponding to positive sample , Take the bounding box regression loss
- u < 1 u < 1 u<1 Indicates that the candidate area is the background , The negative samples , There is no boundary box regression loss
- of v v v The calculation of

- v x = ( G x − P x ) / P w v_x = (G_x - P_x) / P_w vx=(Gx−Px)/Pw
- v y = ( G y − P y ) / P h v_y = (G_y - P_y) / P_h vy=(Gy−Py)/Ph
- v w = l n ( G w ^ / P w ) v_w = ln(\hat{G_w} / P_w) vw=ln(Gw^/Pw)
- v h = l n ( G h ^ / P h ) v_h = ln(\hat{G_h} / P_h) vh=ln(Gh^/Ph)
- [ u ≥ 1 ] [u \ge 1] [u≥1] It's Iverson
summary
In this paper, Fast R-CNN, One right R-CNN and SPPnet Updated simplicity 、 Fast version . In addition to reporting the most advanced test results at present , We also provide detailed experiments , Hope to provide new ideas . Of particular note , Sparse target candidate regions seem to improve the quality of the detector . In the past, this problem cost too much ( In time ) And has been unable to explore in depth , but Fast R-CNN Make it possible . Of course , There may be undiscovered technologies , So that the dense box can achieve the effect similar to the sparse candidate box . If such a method is developed , Can help further accelerate target detection .
边栏推荐
- 使用Ansible中的playbook
- MODFLOW flex, GMS, FEFLOW, hydraus practical application
- Recommendation system - machine learning
- 517. 超级洗衣机
- ALV入门
- Week 6 Learning Representation: Word Embedding (symbolic →numeric)
- [Luogu] p1383 advanced typewriter
- NPM operation instruction
- 安装NCCL\mpirun\horovod\nvidia-tensorflow(3090Ti)
- DOM事件流 事件冒泡-事件捕获-事件委托
猜你喜欢
![[acwing] 1268. Simple questions](/img/f3/7eeae566dd74d77cf6f8b4640e4f29.png)
[acwing] 1268. Simple questions

Development to testing: a six-year road to automation from scratch

Day011 一维数组

Nacos 介绍和部署

C语言函数

Uniapp applet framework - a set of code, multi segment coverage

CLM land surface process model

Full analysis of domain name resolution process means better text understanding

Go-Excelize API源码阅读(六)—— DeleteSheet(sheet string)

nacos注册中心
随机推荐
普林斯顿微积分读本02第一章--函数的复合、奇偶函数、函数图像
Compilation method of flood control evaluation report and flood modeling under the new guidelines
C语言详解系列——函数的认识(3)形参,实参,嵌套调用和链式访问
Shell read read console input, use of read
no networks found in /etc/cni/net.d
MySQL basic learning
如何优雅的复现YOLOv5官方历程(二)——标注并训练自己的数据集
Okaleido上线聚变Mining模式,OKA通证当下产出的唯一方式
35. 搜索插入位置
ABAP语法学习(ALV)
How to conduct test case review
Test of countlaunch demo
nacos注册中心
TZC 1283: simple sort - select sort
Okaleido launched the fusion mining mode, which is the only way for Oka to verify the current output
没背景、没学历?专科测试员进入互联网大厂是不是真的没希望?
Basic methods of realizing licensing function in C language
Teach you how to use code to realize SSO single sign on
Improve reduce parallelism in shuffle operation
Go exceed API source code reading (VI) -- deletesheet (sheet string)