当前位置:网站首页>机器学习笔记 - 使用 GAN 进行数据增强以进行缺陷检测
机器学习笔记 - 使用 GAN 进行数据增强以进行缺陷检测
2022-07-16 18:56:00 【坐望云起】
一、用于数据增强的 GAN
在机器学习中,训练数据量不足往往会阻碍分类算法的性能。经验表明,训练数据不足是常态,而不是例外,这就是为什么人们提出了数据增强方法。
我们可以使用数据增强,例如稍微旋转或翻转原始数据以生成新的训练数据。但这当然不会给我们带来真正的新形象。
反过来,GAN 确实输出了全新的图像。您可能听说过 GAN 作为一种创建极其逼真的假图像和视频的手段(在“Deepfake”一词下广为流传)。正如最近的研究(例如Antoniou 等人 2017、Wang 等人 2018和Frid-Adar 等人 2018)所表明的,它们还可以通过生成额外的训练数据来提高机器学习分类器的性能。
(1)工业应用
当我们处理稀缺的训练数据时,GAN 数据增强方法特别有前途。
想象一下,我们想要训练一个机器学习模型来识别工业生产流程中的缺陷组件。希望缺陷很少发生;但这也意味着我们可能只有少量图像显示出典型的缺陷来训练网络。
使用 GAN,我们可以为任何给定的缺陷类型生成额外的图像。
(2)数据
我们使用NEU 表面缺陷数据库,其中包含 300 张生产过程中出现的金属划痕图像。
 http://faculty.neu.edu.cn/yunhyan/NEU_surface_defect_database.html
http://faculty.neu.edu.cn/yunhyan/NEU_surface_defect_database.html
GAN 是一种无监督学习方法,因此我们不需要任何标签。我们没有想要区分的不同类型的标记图像,而是有一组我们试图模仿的未标记数据。
二、GAN网络
(1)工作原理概述
GAN 不是一个单一的神经网络。相反,它结合了两个互相玩游戏的神经网络。我将简要解释一下游戏规则。
首先,有一个鉴别器网络,它只是一个简单的卷积神经网络(CNN)。然后我们有生成器网络,它或多或少是一个反向的 CNN。它获得一个随机输入,并通过使用转置卷积对输入进行上采样来创建图像作为输出。
游戏进行如下:生成器获取随机输入并生成图片。鉴别器交替获取生成的图像和原始图像(不知道哪个是哪个),并尝试预测给定图像是原始图像还是生成的,仅考虑图像的特征。
随着时间的推移,这两个网络都试图变得更好。鉴别器试图将真实图像与生成的图像区分开来,而生成器旨在欺骗鉴别器,使其认为其图像是真实的。

鉴别器试图最大化它的成功,而生成器试图最小化它。
下图是训练 GAN 时发生的情况的一个很好的可视化。图像来源
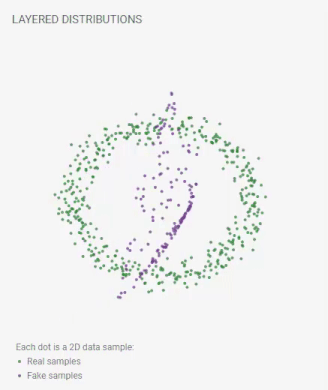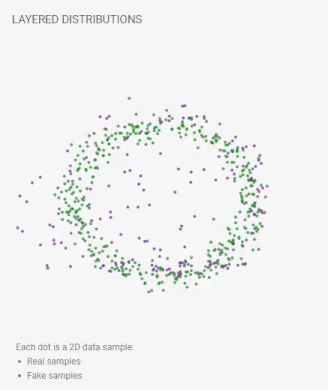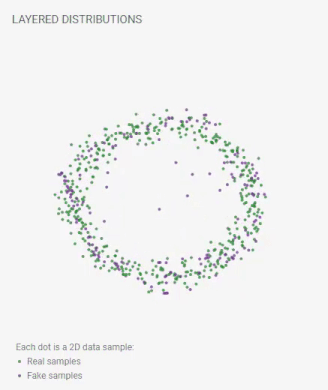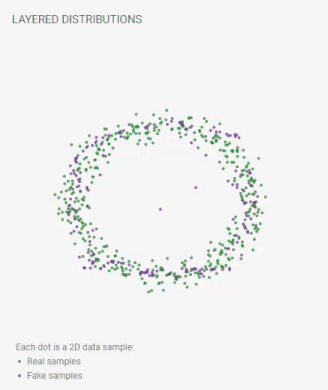
(2)网络配置
batch_size = 12
generator_depth = 64
discriminator_depth = 128 loss_function=nn.BCELoss()
number_of_epochs = 128
discriminator_optimizer = optim.Adam(discriminator.parameters(), lr=0.0004, betas(0.5,0.999))
generator_optimizer = optim.Adam(generator.parameters(), lr=0.0001, betas=(0.5,0.999))在下面的代码块中,我们定义了鉴别器,它将图像作为输入。我们定义了模型用来分类这个输入图像的一系列过滤器。当我们训练它时,我们会调整这些过滤器,以便它学会区分原始图像和生成的图像。
class Discriminator(nn.Module):
'''
The Discriminator that shall distinguish between dataset images and the ones generated by the generator.
'''
def __init__(self, number_of_gpus):
super(Discriminator, self).__init__()
self.ngpu = number_of_gpus
self.layer1 = nn.Sequential(
spectral_norm(nn.Conv2d(in_channels=3, out_channels=discriminator_depth,
kernel_size=(4,4), stride=2, padding=1, bias=False)),
nn.LeakyReLU(0.2, inplace=True)
)
self.layer2 = nn.Sequential(
spectral_norm(nn.Conv2d(in_channels=discriminator_depth, out_channels=discriminator_depth*2,
kernel_size=(4,4), stride=2, padding=1, bias=False)),
nn.BatchNorm2d(discriminator_depth*2),
nn.LeakyReLU(0.2, inplace=True)
)
self.layer3 = nn.Sequential(
spectral_norm(nn.Conv2d(in_channels=discriminator_depth*2, out_channels=discriminator_depth*4,
kernel_size=(4,4), stride=2, padding=1, bias=False)),
nn.BatchNorm2d(discriminator_depth*4),
nn.LeakyReLU(0.2, inplace=True)
)
self.layer4 = nn.Sequential(
spectral_norm(nn.Conv2d(in_channels=discriminator_depth*4, out_channels=discriminator_depth*8,
kernel_size=(4,4), stride=2, padding=1, bias=False)),
nn.BatchNorm2d(discriminator_depth*8),
nn.LeakyReLU(0.2, inplace=True)
)
self.layer5 = nn.Sequential(
spectral_norm(nn.Conv2d(in_channels=discriminator_depth*8, out_channels=discriminator_depth*16,
kernel_size=(4,4), stride=2, padding=1, bias=False)),
nn.BatchNorm2d(discriminator_depth*16),
nn.LeakyReLU(0.2, inplace=True)
)
self.output_layer = nn.Sequential(
nn.Conv2d(in_channels=discriminator_depth*16, out_channels=1,
kernel_size=(4,4), stride=1, padding=0, bias=False),
nn.Sigmoid()
)
def forward(self, input_image):
layer1 = self.layer1(input_image)
layer2 = self.layer2(layer1)
layer3 = self.layer3(layer2)
layer4 = self.layer4(layer3)
layer5 = self.layer5(layer4)
return self.output_layer(layer5)生成器具有与鉴别器相似的过滤器,只是相反。它不是查看图片来检测模式,而是根据我们教它绘制的模式返回图像。输入是一堆随机数,它们激活这些过滤器以绘制图像。
class Generator(nn.Module):
'''
The Generator Network. It is mostly a reversed discriminator with a random input noise which outputs an image.
'''
def __init__(self, number_of_gpus):
super(Generator, self).__init__()
self.ngpu = number_of_gpus
self.layer1 = nn.Sequential(
nn.ConvTranspose2d(in_channels=100, out_channels=generator_depth*16,
kernel_size=(4,4), stride=1, padding=0, bias=False),
nn.BatchNorm2d(num_features=generator_depth*16),
nn.ReLU(inplace=True)
)
self.layer2 = nn.Sequential(
nn.ConvTranspose2d(in_channels=generator_depth*16, out_channels=generator_depth*8,
kernel_size=(4,4), stride=2, padding=1, bias=False),
nn.BatchNorm2d(num_features=generator_depth*8),
nn.ReLU(inplace=True)
)
self.layer3 = nn.Sequential(
nn.ConvTranspose2d(in_channels=generator_depth*8, out_channels=generator_depth*4,
kernel_size=(4,4), stride=2, padding=1, bias=False),
nn.BatchNorm2d(num_features=generator_depth*4),
nn.ReLU(inplace=True)
)
self.layer4 = nn.Sequential(
nn.ConvTranspose2d(in_channels=generator_depth*4, out_channels=generator_depth*2,
kernel_size=(4,4), stride=2, padding=1, bias=False),
nn.BatchNorm2d(num_features=generator_depth*2),
nn.ReLU(inplace=True)
)
self.layer5 = nn.Sequential(
nn.ConvTranspose2d(in_channels=generator_depth*2, out_channels=generator_depth,
kernel_size=(4,4), stride=2, padding=1, bias=False),
nn.BatchNorm2d(num_features=generator_depth),
nn.ReLU(inplace=True)
)
self.output_layer = nn.Sequential(
nn.ConvTranspose2d(in_channels=generator_depth, out_channels=3,
kernel_size=(4,4), stride=2, padding=1, bias=False),
nn.Tanh()
)
def forward(self, input_noise):
layer1 = self.layer1(input_noise)
layer2 = self.layer2(layer1)
layer3 = self.layer3(layer2)
layer4 = self.layer4(layer3)
layer5 = self.layer5(layer4)
return self.output_layer(layer5)(3)训练
我们可以将训练分为三个部分。
用真实图像训练判别器:
discriminator.zero_grad()
prediction = discriminator(batch)
labels_for_dataset_images = torch.ones((batch_size,), device=device).view(-1)
loss_discriminator = loss_function(prediction.view(-1), labels_for_dataset_images)
loss_discriminator.backward()用生成器生成的图像训练鉴别器:
random_noise = torch.randn(batch_size,100,1,1, device=device)
generated_image = generator(random_noise)
labels_for_generated_images = torch.zeros(np.prod(prediction.size()), device=device)
prediction = discriminator(generated_image.detach())
loss_generator = loss_function(prediction.view(-1), labels_for_generated_images)
loss_generator.backward()
discriminator_optimizer.step()训练生成器:
generator.zero_grad()
prediction = discriminator(generated_image).view(-1)
loss_generator = loss_function(prediction, labels_for_dataset_images)
loss_generator.backward()
generator_optimizer.step()
如果生成器过拟合,我们可以从数据集中获得与图像非常相似甚至几乎相同的图像。这当然不是我们想要的结果。所以我们测试我们生成的图像与数据集中的图像有多相似。
使用k最近邻方法。这是一种分类算法,可以从要分类的图像中搜索“最近”的图像到数据集中的所有图像,以观察是否有过拟合产生。
def euclidean_distance(a, b):
'''
Calculates the euklidean Distance of two torch tensors of the same size.
'''
return torch.sqrt(((a - b) ** 2).sum())
def get_k_nearest_samples(image, k):
'''
Searches for the k-nearest samples in the dataset of a given image based on the euclidean distance.
'''
return np.argsort([euclidean_distance(image[0][0], sample[0][0]) for sample in dataset])[:k]
这些图像与数据集图像相似,但它们不太相似——因此生成器没有过度拟合。
三、结论
生成对抗网络确实学会了如何从给定的数据分布中生成新图像:它们是真正的新图像,因为它们不仅仅是原始图像的副本,而且仍然无法与原始图像区分开来。因此,我们可以使用这些新创建的图像来训练缺陷检测或缺陷分类模型。
当然,在实际情况下,您应该始终仔细检查 GAN 创建的图像是否真的对模型性能产生了积极影响。情况可能并非总是如此。
话虽如此,GAN(不仅限于)在工业生产中有很多潜在的用例。由于目前对 GAN 的研究兴趣,我们很快就会对何时以及如何使用它们有很多新的见解。
值得注意的是,调整GAN微小的变化可能会导致输出失真。
边栏推荐
- [C language brush leetcode] 134 Gas station (m)
- World Tour Finals 2019 D - special boxes
- R语言使用glm函数构建泊松对数线性回归模型处理三维列联表数据构建饱和模型、使用step函数基于AIC指标实现逐步回归筛选最佳模型
- LeetCode+ 86 - 90 双指针、回溯、区间 dp 专题
- 音视频中的语音信号处理都包括哪些方向?
- Initial redis (know redis and common commands)
- Kotlin correctly exits the foreach and foreachindexed loop functions
- UE4 Lights UWorld to FScene [2]
- Leetcode high frequency question: three unordered arrays a, B, C with length N, find the total number of combinations of (I, J, K) with a[i] + b[j] + c[k] = 64
- Redis implements distributed locks
猜你喜欢

C language as a push box

淺學js中的關系運算符

High numbers | calculation of double integral 1 | high numbers | handwritten notes

I2C communication protocol realizes data display on OLED display screen
![leetcode:1552. Magnetic force between two balls [maximum value of maximum value = two points]](/img/42/138282c12bf9972a9e92b6fe8e9b8b.png)
leetcode:1552. Magnetic force between two balls [maximum value of maximum value = two points]

MySQL --- 多表查询 - 表与表之间的关系

Use of prettier code formatting tool

On array method reconstruction and re encapsulation -foreach map -- push (), unshift (), shift (), map (), filter (), every (), some (), reduce ()
![[JS encapsulates a simple asynchronous API to obtain asynchronous operation results and process parsing]](/img/98/fa6006639acfff1b49f47b9a64688e.png)
[JS encapsulates a simple asynchronous API to obtain asynchronous operation results and process parsing]

The University of Leuven recruited postdoctoral researchers to use ai/ml to analyze images of solar activity areas and predict flares
随机推荐
Sql笔记
Huaweiyun online classroom AI technology field course "deep learning" learning experience - the second week
Machine learning BP (back propagation) neural network
Activity component export experiment
第十三篇,STM32 I2C串行总线通信实现
Current mirror automatic layout symmetry: quantification and application to eliminate nonlinear process gradients
Classic application method of installing HAP on Hongmeng development board
Do you know the answers to the common questions in the interview of senior programmers? With answer
不同的图像patch由不同的专家模型来处理!南洋理工&Mila稀疏融合混合专家模型SF-MoE,具有超强泛化能力!代码已开源!...
Duplicate disk: problems when BN and dropout are used together
True question of CCF (anger takes 100 faints)
音视频中的语音信号处理都包括哪些方向?
【我的OpenGL学习进阶之旅】NDK开发中find_library查找的系统动态库在哪里?
Dynamically adding routes and refreshing the page will show a blank screen
Transaction isolation level
World Tour Finals 2019 D - Distinct Boxes 题解
On array method reconstruction and re encapsulation -foreach map -- push (), unshift (), shift (), map (), filter (), every (), some (), reduce ()
Part 13: implementation of STM32 I2C serial bus communication
[JS encapsulates a simple asynchronous API to obtain asynchronous operation results and process parsing]
R language uses GLM function to build Poisson logarithm linear regression model, processes three-dimensional contingency table data to build saturation model, and uses step function to realize stepwis