当前位置:网站首页>对Crowdhuman数据集处理,根据生成的train.txt分离数据集
对Crowdhuman数据集处理,根据生成的train.txt分离数据集
2022-07-17 05:10:00 【Just do it!ට⋆*】
#分离数据集
最近想用YOLOv5训练Crowdhuman数据集,但发现此数据集不是txt格式,于是在网上搜索对Crowdhuman数据格式更改的代码工具,将Crowdhuman数据更改为txt格式后,发现所有的train和test文件数据都在一个文件夹里。要想用于YOLOv5的训练,需要对其分离,因为格式工具已经将train.txt和test.txt生成,根据这两个文件copy IMG和label即可。、
代码
#第一天学习
#第一天学习
# 根据train。txt和test。txt划分数据集
import os
import shutil
#原始路径
traintxt=r'D:\songjiahao\DATA\crowdhuman-608x608\train.txt'
testtxt=r'D:\songjiahao\DATA\crowdhuman-608x608\test.txt'
savedir='D:\songjiahao\DATA\crowhuman/'
#训练集路径
train_image_path = r'D:\songjiahao\DATA\crowhuman\trainJPEGImages/'
train_label_path = r'D:\songjiahao\DATA\crowhuman\trainAnnotations/'
#测试集路径
test_image_path = r'D:\songjiahao\DATA\crowhuman\testJPEGImages/'
test_label_path = r'D:\songjiahao\DATA\crowhuman\testAnnotations/'
#检查文件夹是否存在
'''
def mkdir():
if not os.path.exists(train_image_path):
os.makedirs(train_image_path)
if not os.path.exists(train_label_path):
os.makedirs(train_label_path)
if not os.path.exists(val_image_path):
os.makedirs(val_image_path)
if not os.path.exists(val_label_path):
os.makedirs(val_label_path)
if not os.path.exists(test_image_path):
os.makedirs(test_image_path)
if not os.path.exists(test_label_path):
os.makedirs(test_label_path)
'''
def main():
f = open(traintxt, 'r')
trainlist = f.readlines()
f = open(testtxt, 'r')
testlist = f.readlines()
f.close()
print("训练集数目:{},测试集数目:{}".format(len(trainlist),len(testlist)))
# for i in range(len(trainlist)):
#
# name = trainlist[i][24:-5]
#
# srcImage = traintxt.replace('train.txt','') + name + '.jpg'
# srcLabel = traintxt.replace('train.txt','') + name + '.txt'
#
# dst_train_Image = train_image_path + name + '.jpg'
#
# dst_train_Label = train_label_path + name + '.txt'
# shutil.copyfile(srcImage, dst_train_Image)
# shutil.copyfile(srcLabel, dst_train_Label)
# for i in range(len(testlist)):
# name = testlist[i][24:-5]
#
# srcImage = testtxt.replace('test.txt', '') + name + '.jpg'
# srcLabel = testtxt.replace('test.txt', '') + name + '.txt'
#
# dst_test_Image = test_image_path + name + '.jpg'
#
# dst_test_Label = test_label_path + name + '.txt'
# shutil.copyfile(srcImage, dst_test_Image)
# shutil.copyfile(srcLabel, dst_test_Label)
# print(i+1)
if __name__ == '__main__':
main()
需要填写的参数有原始路径 训练集路径 测试集路径。提前建好文件夹,再输入路径比较好。
边栏推荐
- 软件过程与管理复习(十)
- 11.数据仓库搭建之DWS层搭建
- 12. Ads layer construction of data warehouse construction
- C language dynamic memory management
- Ambari 2.7.5 integrated installation hue 4.6
- Idea import local package
- Time difference calculation
- 5.1 business data acquisition channel construction of data acquisition channel construction
- C语言&位域
- The future of data Lakehouse - Open
猜你喜欢
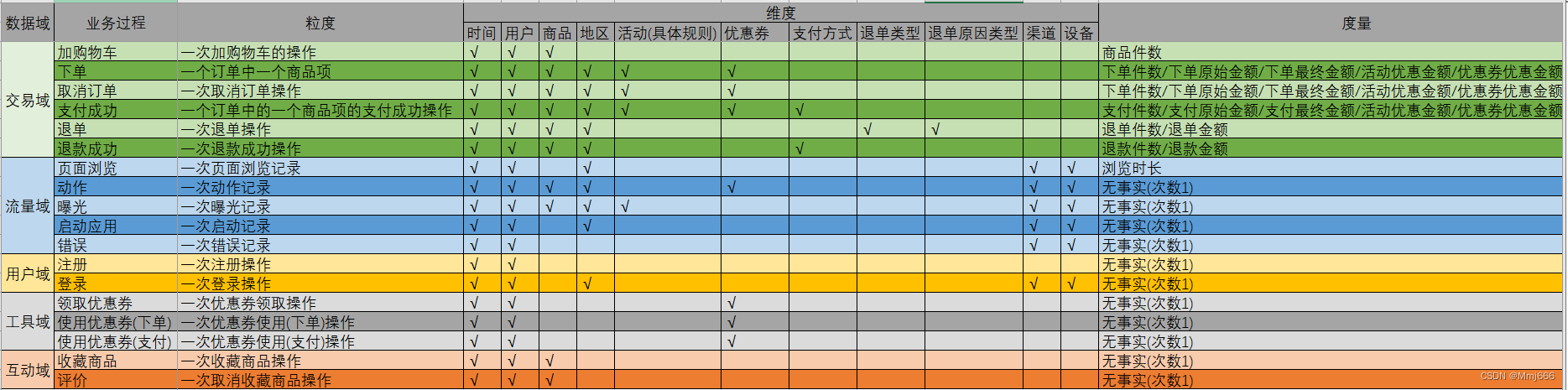
10. DWD layer construction of data warehouse construction

软件过程与管理总复习
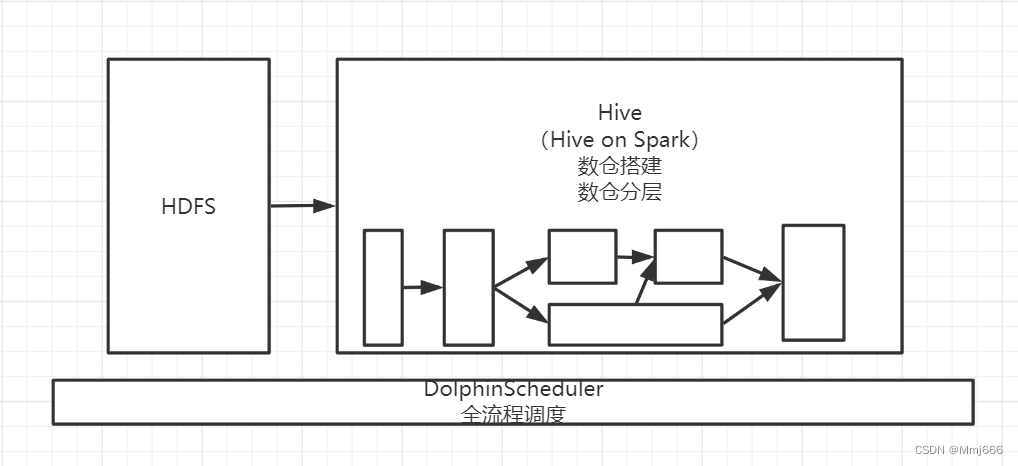
3.东软跨境电商数仓项目架构设计

Page navigation of wechat applet
3. Neusoft cross border e-commerce data warehouse project architecture design

【语音识别入门】基础概念与框架

12.数据仓库搭建之ADS层搭建

1. Dongsoft Cross - Border E - commerce Data Warehouse Requirement specification document
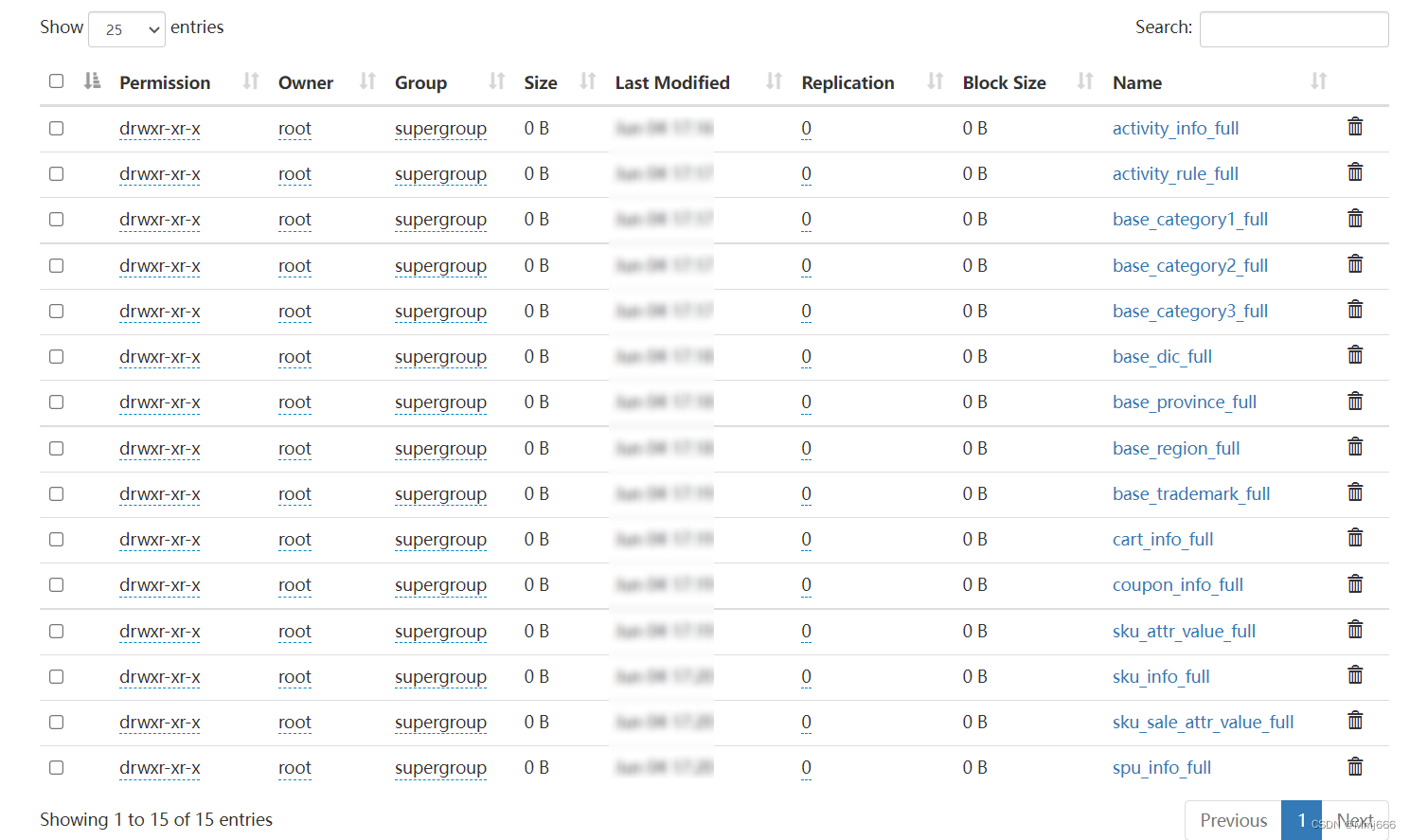
5.1数据采集通道搭建之业务数据采集通道搭建

Use Flink SQL to transfer market data 1: transfer VWAP
随机推荐
MySQL 服务正在启动 . MySQL 服务无法启动
时间差计算
C语言&位域
Coap在Andorid中的简单应用
MySQL 查询当天、本周,本月、上一个月的数据
pymongo模糊查询
ETL工具——kettle实现简单的数据迁移
Character processing function
class文件格式的理解
Common (Consortium)
Use iceberg in CDP to pressurize the data Lake warehouse
Pointer function of C language
[bug solution] org apache. ibatis. type. TypeException: The alias ‘xxxx‘ is already mapped to the value ‘xxx‘
正则替换group(n)内容
【语音识别】kaldi安装心得
gradle
软件过程与管理复习(六)
Constants and constant pointers
5. Spark core programming (1)
Using Flink SQL to fluidize market data 2: intraday var