当前位置:网站首页>mysql20210906
mysql20210906
2022-07-26 10:36:00 【竹某】
0.内容概要:
a.连接查询的概念,分类
b.连接查询原理,笛卡尔积(两张表)
c.两表内连接查询语法,等值连接,非等值连接,自连接
d.外连接:左外连接和右外连接;外连接和内连接的关系
e.多表连接
1.连接查询概念和分类:
连接查询,或说跨表查询,区别于前面的单表查询,是指多张表联合起来查询数据。按照语法年代分,分为SQL1992和SQL1999;而按照连接对象分,分为内连接查询,外连接查询和全连接查询(略去不讲)。内连接查询和外连接查询的概念放到外连接查询处解决。
2.连接查询原理和笛卡尔积现象
笛卡尔现象发生于无条件的连接查询,体现了连接查询的本质。我们以两表之间的内连接为例。
有表emp:

表dep:

进行内连接:
select e.deptno, d.dname from emp as e, dep as d;
最后的结果为56行的表,表由于过长不展示。观察表可以发现,emp表中的每一条记录都和dep表中的所有4条记录一一匹配了过去,这导致了最终的记录条数为14 * 4 = 56条。我们把这样的现象称为笛卡积现象,即表连接结果的记录条数等于各表记录条数之积。
3.两表内连接查询语法
| select field1, field2 from table1,table2; | 无条件两表内连接,导致笛卡尔积现象 |
| select field1,field2 from table1,table2 where condition; | SQL1992,缺点在于将内连接查询条件和一般筛选条件混在where中,现在不用了 |
| select field1,field2 from table1 join table2 on condition; | SQL1999,实现了表连接条件和表筛选条件的分离,使得结构更加清晰 |
为了进一步提高表中第三条语句的效率,我们可以为table1,table2起别名,并且使用在field1和field2之前:
select t1.field1,t2.field2 from table1 as t1 inner join table2 as t2 on condition;在field1和field2指定表名防止了mysql同时在t1和t2中查找field1(field2),从而提高了效率。否则的话,mysql会在t1和t2中查找field1,也会在t1和t2中查找field2,这降低了效率。另外,加了condition之后,尽管从结果上看,我们避免了笛卡尔积现象。但是,两张表的记录之间的匹配次数仍没有减少,仍是各表中记录数的乘积。
我们可以这样认为:上述语句首先执行from和join语句,让两表按照笛卡尔积现象连接为一张新表,而后再执行on语句,筛选中符合condition的字段。最后才是select。 所以,笛卡尔积体现了表连接(以内连接为例)的原理,十分重要。
现在可以考虑一下condition了。对于内连接,如果condition是等式条件,那么称此次内连接为等值连接。例如:找到各员工的工作地点。
select e.ename, d.dname from emp as e join dep as d on e.deptno = d.deptno;这里的条件为:e.deptno = d.deptno,是一个等式。所以这次内连接是等值连接。
在使用的enterprise数据库中再导入一张表salgrade:

我们联合emp和salgrade查找员工薪资等级。这需要用到内连接之非等值连接(condition为非等式条件)。
select e.ename, s.grade
from emp as e
join salgrade as s
on e.sal between s.losal and s.hisal;自连接就是一张表和自己连接查询数据。思路是把一张表看为两张表。语法和等值连接和非等值连接一致,均符合内连接的语法。例如:查询员工的领导。
select e1.ename, e2.ename
from emp as e1
inner join emp as e2
on e1.mgr = e2.empno;4.两表外连接
两表外连接和内连接的区别在于两张表之间有无主从关系。对于内连接而言,两张表的地位等同,select之后指只会显示(笛卡尔积后)符合条件的记录;而对于外连接而言,两张表存在主从关系。外连接主要查主表,会显示主表的全部记录,不论是否符合条件;会顺带着显示从表中符合条件的记录。语法为:
//左连接
select t1.field1, t2.field2 from table1 t1 left join table2 t2 on condition;
//右连接
select t1.field1, t2.field2 from table1 t1 right join table2 t2 on condition;左连接选定join左侧的表为主表,右侧的为从表;而右连接反之。左右连接一定可以互相转化。
示例:查询所有员工的领导名,无论有无领导。
由于King没有领导,结果本来应该只有13条记录的;但是使用了外连接的语法后,有14条记录。
mysql> select e1.ename,e2.ename
-> from emp e1
-> left outer join emp e2
-> on e1.mgr = e2.empno;
不符合on后面条件的King这条记录也存在,这就是外连接区别于内连接的地方:显示了主表的全部记录和符合条件的从表记录。外连接可以被认为是以主表为主的内连接。
5.多表查询(三表或以上)
语法:
select
......
from
table1 t1
(inner/left/right)join
table2 t2
on
(t1,t2)condition
(inner/left/right)join
table3 t3
on
(t1,t2,t3)condition
...
...
//第一个问题,每次的条件都只能是join后的表名和from后的表名组成的吗?还是本次join后的表名
//和之前所有出现过的表名均可?
//实验结果是均可。join tablen tn on (t1,t2,t3,...,tn)在多表查询中,内外连接可以混合。但是需要注意的是,left连接不只是把前面的一张表作为主表,同理right连接不只是把后面一张表作为主表。
筛选出员工名,对应的部门名,薪资和薪资等级。要求打出全部的部门。
select e.ename, d.dname, e.sal, s.grade
from emp e
right outer join dep d
on e.deptno = d.deptno
join salgrade s
on e.sal between s.losal and s.hisal;
//e先与d外连接,d为主表;其结果由于s内连接,使前面的外连接被筛掉了。所以最后结果不是我们想要的。结果为:
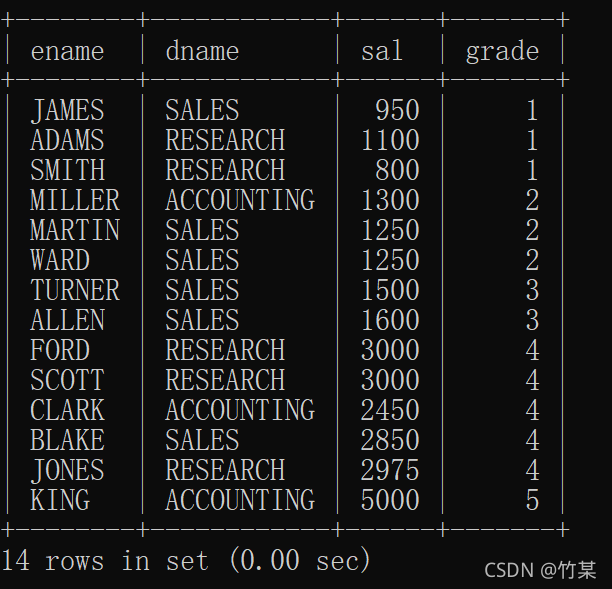
与目的不和。
只有这么做才能达到目的:
mysql> select e.ename, d.dname, e.sal, s.grade
-> from emp e
-> join salgrade s
-> on e.sal between s.losal and s.hisal
-> right outer join dep d
-> on e.deptno = d.deptno
-> \g
或是
select e.ename, d.dname, e.sal, s.grade
from emp e
right outer join dep d
on e.deptno = d.deptno
left join salgrade s
on e.sal between s.losal and s.hisal;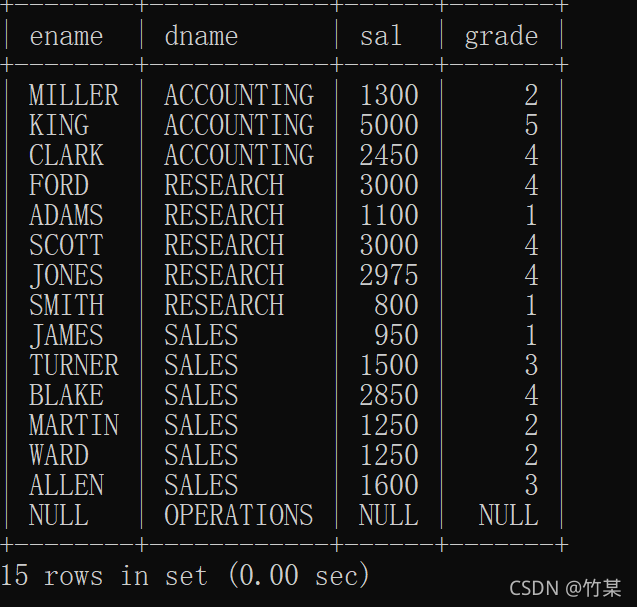
我认为合理的解释是:(假设以此连接的表为table1,table2,...,tablen)首先,table1会和table2进行连接(join),之后执行on进行筛选。筛选之后得到的结果再与table3进行join,之后再执行on后面的条件。以此类推。在所有的join和on都执行好了之后,执行from。
这个解释的合理之处在于:1.符合语言直观;2.筛选后再连接能提高执行效率;3.能够解释上面的那种现象。这也告诉了我们该如何在多表查询中混合使用内连接和外连接。如果想要把某张表作为主表的话,要么把它放在开头后使用left join或是放在结尾使用right join,要么在它之前使用right join在其之后使用left join。
边栏推荐
猜你喜欢

Phase 4: one of College Students' vocational skills preparation in advance

js 获得当前时间,时间与时间戳的转换

Mlx90640 infrared thermal imager temperature sensor module development notes (VI) pseudo color coding of infrared images

多目标优化系列1---NSGA2的非支配排序函数的讲解

uniapp使用简单方法signalR(仅用于web调试,无法打包app)

canvas上传图片base64-有裁剪功能-Jcrop.js

STM32 阿里云MQTT esp8266 AT命令

.NET 开源框架在工业生产中的应用

vscode上使用anaconda(已经配置好环境)

英语基础句型结构------起源
随机推荐
C语言回调函数
Using native JS to realize custom scroll bar (click to reach, drag to reach)
粽子大战 —— 猜猜谁能赢
Our Web3 entrepreneurship project is yellow
第4期:大学生提前职业技能准备之一
oracle 启动不了 tnslistener服务启动不了
Uniapp uses the simple method signalr (only for web debugging, cannot package apps)
[Halcon vision] Fourier transform of image
404页面和路由钩子
使用Geoprocessor 工具
STM32 阿里云MQTT esp8266 AT命令
.NET操作Redis Hash对象
QRcode二维码(C语言)遇到的问题
C语言计算日期间隔天数
多目标优化系列1---NSGA2的非支配排序函数的讲解
12 复制对象时勿忘其每一个成分
事务的传播性propagation
[leetcode每日一题2021/2/13]448. 找到所有数组中消失的数字
少了个分号
Perfect / buffer motion framework in sentence parsing JS (for beginners)