当前位置:网站首页>Nifi listsftp intensive talk
Nifi listsftp intensive talk
2022-07-18 05:17:00 【Qingdong】
order
since: 2021 year 5 month 20 Japan 22:29
auth :Hadi
Preface
It has been used since the end of last year NiFi, It has been nearly half a year so far , Here we will talk about ListSFTP Use of class related components .NiFi Can be regarded as Flink To use , But it is not recommended to use complex calculations , For my usage scenario, I mainly do the work related to data collection and preprocessing , Be responsible for the first step of the data process , At the same time, it also performs data conversion operations, such as streaming to file , File streaming and so on .
Then obtaining data is the first step of the whole data preprocessing , Generally, we use List & Fetch Data preprocessing based on the operation of , such as :

Pass in advance List Scan the data list , And then through Fetch Pull the data to form a band with real data FlowFile(FlowFile by NiFi The smallest processing unit of , For a file , Data sets ,message etc. ).List Only list output , such as XXX A file list on the server , hand Fetch, according to FlowFile Upper Attributes Pull files .
This article Blog Main explanation ListSFTP As a template , All kinds of List Explanation .
ListSFTP To configure
Directly above :

List policy
When scanning ,List All tasks are to scan the latest files , Or a modified file , Otherwise, there is no point in scanning . So on this premise , Four strategies were born :

Tracking Timestamps
Filter the file according to the timestamp , Simply put, it is through the last Scan it out The last modification time of the file T As the standard for the next scan , The standard for judging whether it is the latest document is : As long as the last modification time of the file is greater than or equal to the last time T, And greater than the last Generate Maximum file time , Then I think it's a new document .
A maximum time for scanning listing.timestamp, The other is the maximum time of the output file processed.timestamp.
So if we configure List after , First scan , It is impossible to scan all qualified data in the scanned object ; When no new documents come out , The last timestamp must be added the second time ( Inaccurate , The smallest unit is subjected to Target System TimeStamp Precision Influence ) The documents of .
What needs to be noted here is , Usually we use it a lot Listing Strategy by Tracking Timestamps Words , It may cause the following problems :
When the generated file is changed, the last modification time , that List It is probably impossible to pull data .1. For example, it is deliberately carried out touch -t 202105205200 file , Then this method is completely unable to pull data . This situation may not be common , But in the production environment, there is a great probability that files will be missing .2. In all List Related components , If a directory cannot be recursive , Then an error will be reported and the directory will be skipped ; When this happens , It may cause other folders to push the time limit forward , This will cause data loss in this folder for a period of time .
Therefore, it is strongly not recommended to use in the production environment Tracjing Timestamps, Unless you have the help of God and man , Or there are few types of data , Convenient maintenance , Steal laziness .
No Tracking
It's simpler , Just don't track , Directly output the full list , Then it doesn't matter whether the data is new or old , Take away directly .
Tracking Entities
Track according to each entity . This configuration is troublesome , You need to configure a buffer , Then configure the thread pool of the connection buffer .
stay Listing Strategy Choose from Tracking Entities, And then in Entity Tacking State Cache The cache methods selected for use in include :
CassandraDistributed、CouchBase、DistributedMapCacheClientService(NiFi Bring their own )、HBase、Hazelcast、Redis, There are six kinds .
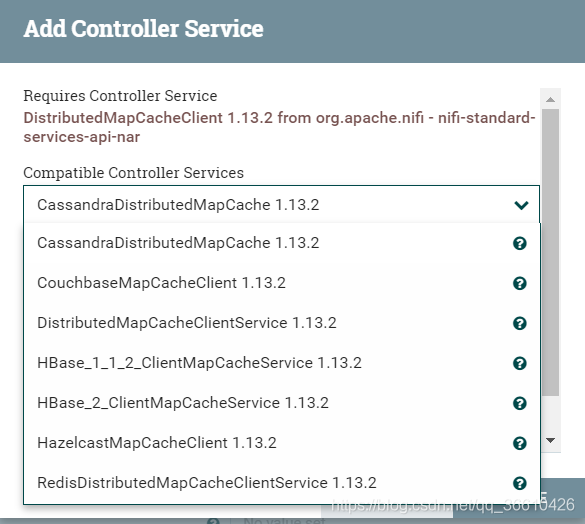
In use NiFi Of course, the self-contained is the simplest , But the less reliable it is , Recommended Cassandra and Hbase and Redis. Because big data systems generally have at least Hbase, Then we should Hbase Explain the column :
Created Hbase_XX_ClientMapCacheService after , We still need to do this Service Configuration of , Click here for the next configuration operation :

After the jump , Click the pinion at the back to configure :

Continue configuration HbaseClientService:

above HBase The required documents are CoreSite.Xml,HbaseSite.Xml,HdfsSite.Xml Three files , Need to put in NiFi All server nodes in the cluster are under the same path , Use the path of three files “,” To splice .
After successful configuration , And then you can see :

You can see there are two Service, One is HBaseCache service , One is the connection HBase Cluster services , The former depends on the latter .
This time we run List, The cache will be stored in HBase In the table , And then every time List It will be carried out twice List Comparison of , To get the files . The advantage is that the data in the time window will also be compared , If this part of data is omitted , Then it will be List come out , Instead of being directly abandoned ; If the file timestamp is changed , Still in the time window , Then the data file will not be changed . The disadvantage is that : Configuration trouble ; Performance degradation ; And in HBase Is a List Component For a piece of data , this Component List The data is Value preservation , So this value It may be particularly large .
Time Window
Grab the files of the latest period , This meaning is not too great , It is generally used when updating data .
List BUG And transformation
List Tasks can only be performed by a single thread , In order to ensure the single thread of this task , until 1.13.2 Version of NiFi These tasks can only be configured on the master node , So much List Tasks will occupy too much of the primary node CPU And memory . And because of NiFi The mechanism of , Data on this node , If there is no follow-up balance Then it will only run on this node , So it's important to note that :1. You can't list Too much data , Prevent the master node GG.2. Must be in List Follow up balance And then Fetch, Allocate the data of the master node to each node .
NiFi It's open source. , So it's easy to find NiFi Source code , stay ListSFTP/FTP This piece of ,NiFi It seems that we are not ready to build it into a component that can scan big data scenes , But assuming NiFi Will not scan 50w,100w,1000w File system . When scanning so much data ,JVM The pile explodes directly GC, Lead to Stop The Word, It will also lead to ZooKeeper disconnect , Cause the master node to switch , The problem of brain splitting of all main node tasks occurs .
This problem is mainly caused by this reason : Use ArrayList Conduct Total quantity Data storage .
stay org.apache.nifi.processor.util.list.AbstractListProcessor The code in , You can read it carefully , The basic logic is clear .

The main issues can be directly focused org.apache.nifi.processors.standard.util.SFTPTransfer#getListing() in , We mainly look at SFTP The implementation of the :
Red line middle Lord listing It is mainly used for SFTPClient When scanning , Swept out Total quantity data , According to this listing Perform subsequent timestamp 、 Entities and so on , But this is a ArrayList, When there's a lot of data , Need to expand , As a result, there must be continuous space in the memory for him . second , Why do we need to do a full amount of data scanning ? It will be filtered according to the timestamp of the file . This logic is not quite right , As a result, a lot of data is crammed .
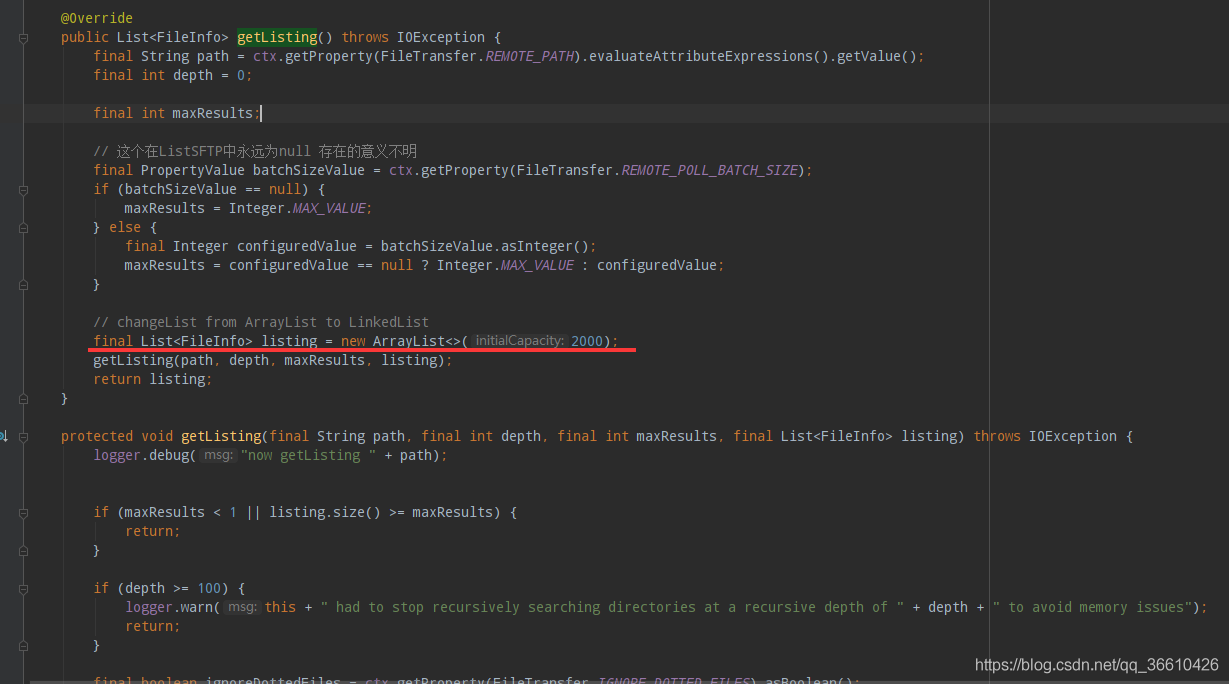
Then focus on the following getListing Recursive method :
In the subsequent definition of a filter, Used to recursively filter subsequent files and folders ; File put in listing in , Folder in subDirs in , But you can see that if it is a folder, it will be directly placed in the recursive queue , This is also unimaginable , Because when we configure the path, there are regular filters .(Path Filter Regex). therefore , If you need to optimize, you can optimize yourself , I optimized it , But it's the company code , So it can't be announced yet .

Optimize : For most of us , Generally speaking, it is to scan the directory of the same level , must /XXX Data category /XXX Data subclass /XXX identification /20210520/ data , Accumulate in this way , Then it is inevitable that I will scan all the data in the time layer every time , But according to the time stamp , When we can scan the time folder , Judge this time folder , Look inside, there are new data . If we only enter for scanning within a period of time .
similar List
about SFTP That's true , Year on year FTP、HDFS、File And so on List,NiFi All components have this problem , Time stamps are not used to the extreme , A lot of resources are wasted for scanning . When you are optimizing components , It is also the most reasonable to develop actual components according to the business situation of the company .
For example, yes. Hive Offline table scanning , If you use native ListHDFS So for SQL Mission , It is probably impossible to scan .(SQL It's about generating .Hive-staging file , Then migrate the entire folder ; It is not directly generated in the partition of the table ) It is likely to lead to the lack of data .
Postscript
In the big data scenario , I have always suspected NiFi Whether it can support my imagination , Judging from the current development , There are good and bad .
I want to express a little ,NiFi Such visual interface operation , Make the whole development process very simple , The same will lead to the lowering of the whole threshold . Uneven, some good and some bad , Not making progress , love pleasure and comfort , After having tools , What we need to imagine is to use the tools better , Go to the community more issue, Improving the code environment is true .
边栏推荐
- CRC16 verification
- The seventh day of learning C language with small Bai challenge -- Enumeration, structure, community
- Information system project managers must memorize the core examination points (III) 14 graphic tools of UML
- VSS技巧:搜索所有签出的文件(根据用户搜索签出文件)
- Do you know the debugging skills of the most commonly used Chrome browser console.
- E-commerce platform background management system --- > system detailed design (user management module)
- LSM存储模型
- [kekeguo information management] how to write the procurement management of information management papers
- Dynamic programming | matrix multiplication
- STM32F103 串口 +DMA中断实现数据收发
猜你喜欢
Profiles vs Permission Sets

Salesforce发布的振奋人心的新功能集锦

Salesforce Certified Sharing and Visibility Designer (SU20)认证考试总结

Salesforce中使用LWC本地开发

Core examination sites for information system project managers (VI) layering of OSI protocol, mapping + real questions

Salesforce中解析合并字段Merge Fields

Chess all in one

1 start.s分析

uni-app表单数据不复现

uni-app请求获取数据
随机推荐
Salesforce Dynamic Dashboard动态报表、限制与解决方案
SourceInsight 插件使用
v-bind和v-for
FreeModbus 在 STM32F1 平台的移植和解析
About solving the problem of token expiration
volatile低配版syn,实现可见性和有序性
uni-app表单数据不复现
What fault simulation does the chaosblade now support for the database? Do the teachers have any information?
酷狗音乐接口开放程度令人咂舌
virtual box挂载共享文件夹
现在ChaosBlade对数据库支持哪些故障的模拟呀?老师们有什么资料吗?
信息系统项目管理师核心考点(八)软件集成技术
动态规划 | 0-1背包问题
nifi ListSFTP等代理设置
STM32 IAP remote update
Redis03: five common data types of redis
CRC16校验
@tap是什么
E-commerce platform background management system -- > operation method description
STM32 IAP远程更新