当前位置:网站首页>Web crawler technology from entry to mastery (penetration of high-end operations) Chapter 2
Web crawler technology from entry to mastery (penetration of high-end operations) Chapter 2
2022-07-18 23:21:00 【Lan Zhou Qianfan】
One :url relevant
1:url Concept :( Simple understanding )URL yes (UniformResourceLocator, Uniform resource locator ) Abbreviation , It is WWW The unified resource positioning mark , It means network address . 2:url form : The partial , It's usually http agreement ,https agreement , These two are common . 3 : The host address of the server , Can be domain name , Host name ,ip Address , Popular speaking , It's a sign . 4 : port : This is set by the server ,url It may not include ports , Because it is generally the default of the server , So the user is accessing url You can link without indicating the port number . 5 : route , Of course, access the directory where the resource is located . 6: Some other parameters : This can actually be combined with the path .
Two : Source code parameters are related
1 : network: Used to view network requests Let's look at the picture :
We can get the request method , This includes get() Methods and post() Method Let's click on one of them Name, Let's look at the picture :
Here you can get Requested URL link ; Requested method ; Status code 200, there 200 On behalf of a successful visit , In the crawler , If the status code obtained is not 200, Then the access fails ; Remote address ; When you launch a http request , In the request header referrer Field indicates which page you initiated the request from ;Referrer-Policy The function of is to control the referrer The content of . Let's see Request URL: https://csdnimg.cn/public/common/libs/jquery/jquery-1.9.1.min.js?1597541613398 Request Method: GET Status Code: 200 Remote Address: 45.116.153.103:443 Referrer Policy: no-referrer-when-downgrade
Let's look at the response head Response Headers : accept-ranges: bytes access-control-allow-origin: * age: 23048929 ali-swift-global-savetime: 1543387296 cache-control: max-age=31536000 content-encoding: gzip content-length: 32828 content-md5: ODdx7xaSv8w/K2kXyphXeA== content-type: application/x-javascript date: Sat, 23 Nov 2019 07:04:44 GMT eagleid: 2d74991c15975416132412717e etag: “383771EF1692BFCC3F2B6917CA985778” expires: Thu, 28 Jun 2018 11:27:53 GMT last-modified: Thu, 21 Jun 2018 06:51:02 GMT server: Tengine status: 200 timing-allow-origin: * vary: Accept-Encoding via: cache44.l2nu20-3[0,200-0,H], cache44.l2nu20-3[0,0], cache5.cn1517[0,200-0,H], cache8.cn1517[1,0] x-cache: HIT TCP_MEM_HIT dirn:2:318540869 x-oss-hash-crc64ecma: 2216235094704600209 x-oss-object-type: Normal x-oss-request-id: 5DD8DA0CEA872639388535FC x-oss-server-time: 8 x-oss-storage-class: Standard x-swift-cachetime: 31104000 x-swift-savetime: Fri, 14 Feb 2020 13:31:49 GMT There's a lot of information here , Let's briefly introduce some accept : Are allowed parameters , Such as accept-ranges : bytes Accept byte content -encoding : gzip This is the encoding of the text content-length : 32828 This is the length date : Sat,23… This is the response time record There's some other information , I will not introduce you here
Let's look at the request head :authority: csdnimg.cn :method: GET :path: /public/common/libs/jquery/jquery-1.9.1.min.js?1597541613398 :scheme: https accept: / accept-encoding: gzip, deflate, br accept-language: zh-CN,zh;q=0.9 referer: https://editor.csdn.net/md?articleId=108031780 sec-fetch-dest: script sec-fetch-mode: no-cors sec-fetch-site: cross-site user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36 Be careful : Some of the information here can reflect what we use requests() Methodical , our get() perhaps post() The method can be seen here ; In addition, the way you visit the website is recorded here , It depends on whether it's a browser or a crawler , If it's a reptile , Websites can choose to deny access . So we can change the request header user-agent, We can simulate a browser . There's other information here , Are some relevant instructions . query string parameter Query string parameters , This is not very important to our reptiles , We personally don't need much attention .
Two : Powerful Scrapy frame :
1:Scrapy The framework is introduced : This framework relies on more libraries , Adopt asynchronous framework , Realize efficient network acquisition . It can be called the most powerful framework at present , Not one of them. , Ha ha ha , Male god frame . 2: Operation principle : I'll show you a picture , Graphics can well describe the relevant principles . Look at the picture .
The picture above shows how he works , You can think of it as a system . Let's describe the principle like this , Use dialogue . Look at . 1 engine :Hi!Spider, Which website are you dealing with ? 2 Spider: Boss asked me to deal with xxxx.com. 3 engine : You put the first one that needs to be dealt with URL Give me! . 4 Spider: Here you are. , first URL yes xxxxxxx.com. 5 engine :Hi! Scheduler , I have request Please help me to rank and join the team . 6 Scheduler : well , Just a minute . 7 engine :Hi! Scheduler , Take care of yourself request Please give me . 8 Scheduler : Here you are. , This is what I took care of request 9 engine :Hi! Downloader , You can download this for me according to the download middleware settings of the boss request request 10 Downloader : well ! Here you are. , This is a good download .( If you fail :sorry, This request Download failed . The engine then tells the scheduler , This request Download failed , You take notes , We'll download it later ) 11 engine :Hi!Spider, This is a good download , And it has been handled according to the download middleware of the boss , Deal with it yourself ( Be careful ! here responses The default is to def parse() This function handles ) 12 Spider:( For those who need to follow up after processing the data URL),Hi! engine , I have two results here , This is what I need to follow up URL, And this is what I got Item data . 13 engine :Hi ! The Conduit I have one here item You take care of it for me ! Scheduler ! This is a need to follow up URL You take care of it for me . Then start the loop at step 4 , Until we get all the information we need . 14 Pipeline scheduler : well , Do it now ! 3: Installation mode : First , Upgrade your pip, The version is too low . Console input command , pip install --upgrade pip then : use pip install Scrapy frame , Console input pip install Scrapy Be careful : If there is an error here –>VC++14.0 Twisted problem , You need to install Twisted. Mind offline installation . But I don't have this problem , The lucky ones . 4 operation : First of all , New projects Be careful , You need to be clear about the path you want to build the project Console input scrapy startproject + Project name After setting up the project , Let's go in and browse scrapy.cfg: The configuration file for the project . mySpider/: Project Python modular , The code will be referenced from here . mySpider/items.py: The project's target file . mySpider/pipelines.py: Pipeline files for the project . mySpider/settings.py: The setup file for the project . mySpider/spiders/: Store crawler code directory . second , Create crawler In the project Spider Build crawler under path , Be sure to find the right one . Console input command : crapy genspider + Reptile name "+ Crawled domain name Now let me show you the effect , Slowly enter and see
Here are some directories I created Be careful __pycache__ This file will not be used for the time being , But don't delete , The reason I'll talk about later , When we deal with reptiles , Don't operate on him . We open the file of the created crawler
import scrapy
class JgdabcSpider(scrapy.Spider): name = ‘jgdabc’ allowed_domains = [‘itcast.cn’] start_urls = [‘https://www.itcast.cn/’]
def parse(self, response):
filename = "spider.text"
open(filename,"wb").write(response.body)The code inside is as follows name Represents your reptile name ; allow_domains Represents the domain name you are allowed to crawl , In fact, this can be commented out start_urls Represents the website def parse(self,response) Represents some of the processing you have to do . Here I write the crawled things into the file "spider.text" Of course, you can do other operations . In fact, we can handle pipeline files , Let's not talk about . 5 : Execution procedure : Please enter our root directory Then enter it on the console :scrapy crawl + Reptile name is enough
Ape friends are welcome to give advice and comments notes : Please respect csdn agreement , Violation of rights will be prosecuted . Blogger :jgdabc, Blogger link click here
边栏推荐
- Quickly build an e-commerce platform based on Amazon cloud technology server free service - Deployment
- C # network application programming, experiment 1: WPF exercise
- Notes on scribbling questions in moher College -- SQL manual injection vulnerability test (mongodb database)
- Tableqa technology of Ali Dharma academy makes tables speak
- Solution to Chinese garbled code in response results of burpsuite tool
- As a time series database, how does tdengine realize and open source its distributed clustering function?
- 学习记录:FSMC—扩展外部SRAM
- 3D point cloud course (III) -- clustering
- EF core learning notes: one to many relationship configuration
- What if the work of product evaluators is repetitive and cumbersome? Can it be automated?
猜你喜欢

Original Rexroth proportional valve 4wrba10w64-2x/g24n9z4/m

万字详解C语言文件

Leetcode -- intersection of two arrays 2

ospf综合实验

【百度飞桨】手写数字识别模型部署Paddle Inference

ImportError: cannot import name ‘Imputer‘ from ‘sklearn. preprocessing‘

Picasso, an efficient search generalization sparse training solution

Dialogue with machines, Ali Dharma academy challenges the new generation of man-machine dialogue Technology

C # find perfect numbers, output daffodils and use of classes
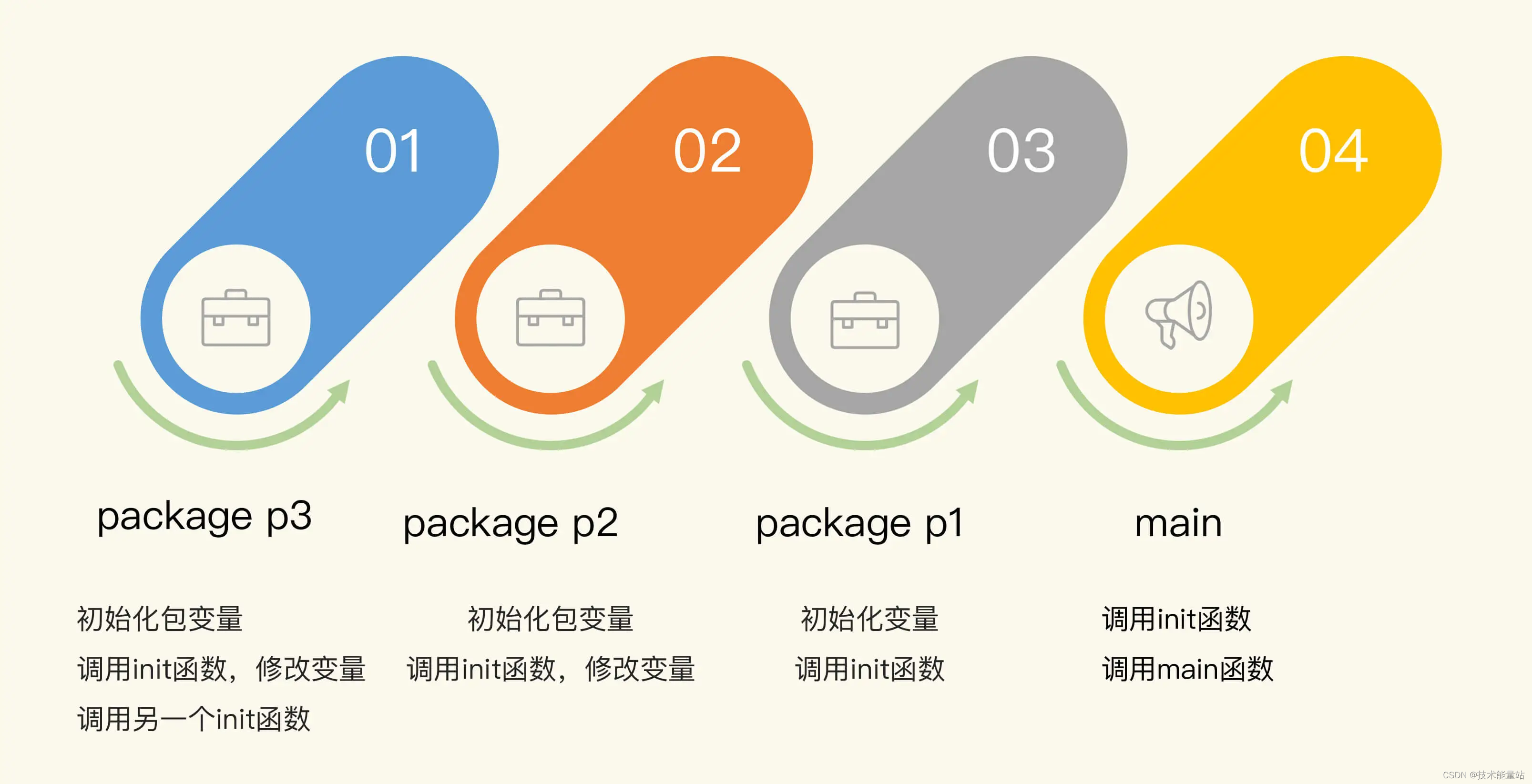
Go如何保证并发读写的顺序?—内存模型
随机推荐
Huada 110 clock calibration
开发到底要不要转行软件测试?一篇足以 最全方位分析
C language custom types: structure, enumeration, union
Configure SSH login for Huawei switches
[noip2006 popularity group] clear random number
Siemens module 6dd1661-0ae1
Error: the solution of diamond operator is not supported in -source 1.6
Programmer growth Article 20: what should I pay attention to when I am just promoted to manager?
How is your MySQL server? More than 3.6 million units worldwide have been exposed to the Internet...
Generate multiple databases at the same time based on multiple data sources and zero code, add, delete, modify and check restful API interfaces - mysql, PostgreSQL, Oracle, Microsoft SQL server multip
[image editing software] FastStone Photo Resizer supports batch conversion and batch renaming
ImportError: cannot import name ‘Imputer‘ from ‘sklearn.preprocessing‘
[CVPR2019] On Stabilizing Generative Adversarial Training with Noise
ADB common entry instructions
MySQL related commands
The difference between NPM and NPX
【远程桌面】rustdesk开源的远程桌面,TeamViewer 和向日葵的替代品
C # network application programming, experiment 2: IP address translation and domain name resolution exercises
[NOIP2006普及组]明明的随机数
Cloud native: docker's practical experience (IV) deploying redis three master and three slave clusters on docker