当前位置:网站首页>如何保证缓存和数据库的双写一致性?
如何保证缓存和数据库的双写一致性?
2022-07-26 07:20:00 【李小恩恩子】
目前大部分高并发系统都是使用redis+mysql数据库来保证高性能,那么更新缓存和更新数据库的流程到底是怎么实现的呢?
目录
类别
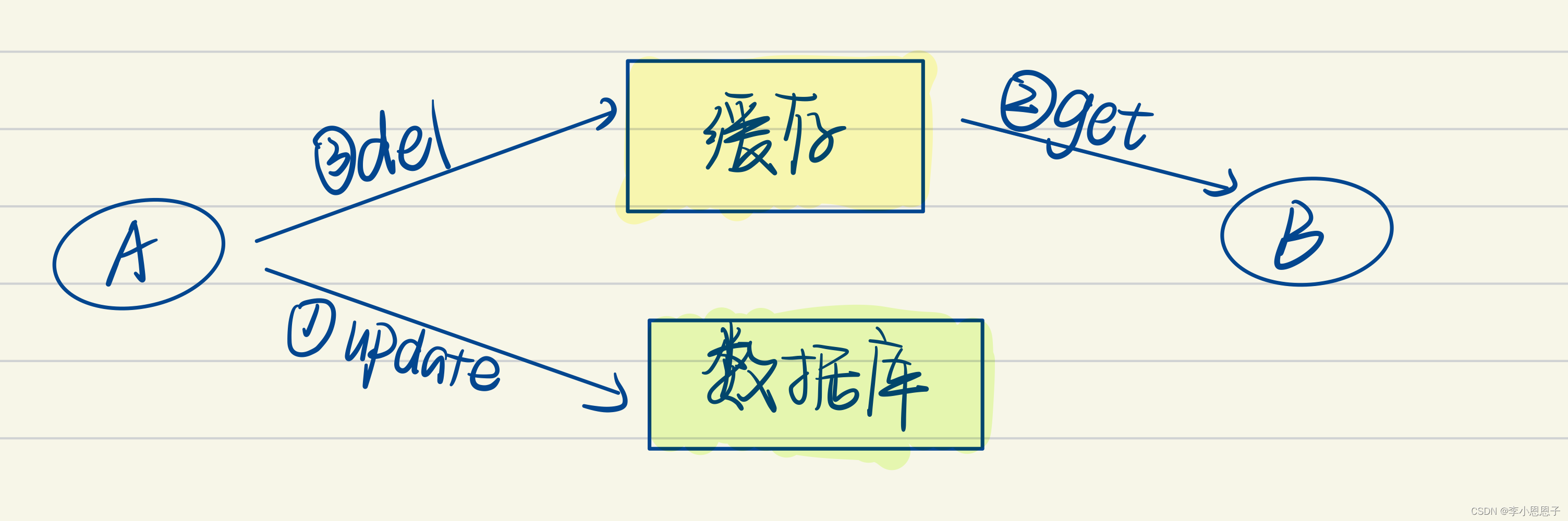
实现缓存与数据库的双写一致性大致有四个类别,分别是:
①先更新缓存,再更新数据库
②先更新数据库,再更新缓存
③先删除缓存,再更新数据库
④先更新数据库,再删除缓存
分析
需要考虑两个问题:①更新缓存与删除缓存哪个更合适?②应该先操作数据库还是先操作缓存?
- 更新缓存和删除缓存哪一个更合适?
更新缓存的优点:每一次的数据变化都更新到缓存里面,所以查询命中率较高。
更新缓存的缺点:更新缓存的消耗比较大。频繁的更新缓存,就会影响数据库性能,如果是写频繁的业务场景,那么可能是频繁的更新缓存但是不怎么读取缓存,那更新缓存并没有什么实际意义。
删除缓存的优点:操作简单,直接将缓存的数据删除即可。
删除缓存的缺点:删除缓存,下一次查询会出现未命中的情况,需要从数据库读入到缓存。
综上,删除缓存会更优。
- 应该先操作数据库还是先操作缓存?
首先对比一下先删除缓存和先删除数据库的失败的情况:
①先删除缓存,再更新数据库

- 进程A删除缓存 - 成功
- 进程A更新数据库 - 失败
- 进程B查询缓存,发现没有,要去查询数据库
- 进程B查询数据库 - 成功
- 进程B更新缓存 - 成功
可以看出,最终缓存和数据库的数据是一致的,但是数据是原来的数据,不是新的。
②先更新数据库,再删除缓存

- 进程A更新数据库 - 成功
- 进程A删除数据库 - 失败
- 进程B查询缓存 - 成功 由于删除缓存失败,得到的数据是旧的数据
可以看出,最终的数据库和缓存数据是不一致的。
因为它们失败的时候都存在着问题,不知道哪一个会更好,但是出现第二步失败的情况下,我们都会进行重试机制解决操作失败的问题。重试机制一般会将操作加入消息队列,然后进行异步更新。
采取重试机制后,然后我们再来对比一下它们没有出现失败的情况下可能出现的问题:
①先删除缓存,再更新数据库

- 进程A删除缓存 - 成功
- 进程B查询缓存,发现没有,要去数据库查询
- 进程B查询数据库 - 成功,得到旧的数据
- 进程B更新缓存 - 成功,将旧的数据更新到缓存里面
- 进程A更新数据库 - 成功,将新的数据更新到数据库里面
我们发现,由于两个进程之间并发操作,进程A的两步操作均成功,在这两步之间,进程B访问了缓存。最终结果是,缓存中存储了旧的数据,而数据库中存储了新的数据,二者数据不一致。
②先更新数据库,再删除缓存
- 进程A更新数据库 - 成功
- 进程B查询缓存 - 成功,但是读到的是旧数据
- 进程A删除缓存 - 成功
可见,最终缓存与数据库的数据是一致的,并且都是最新的数据。但进程B在这个过程里读到了旧的数据,可能还有其他进程也像进程B一样,在这两步之间读到了缓存中旧的数据,但因为这两步的执行速度会比较快,所以影响不是很大。对于这两步之后,其他进程再读取缓存数据的时候,就不会出现类似于进程B的问题了。
总结
先更新数据库、再删除缓存是影响更小的方案。如果第二步出现失败的情况,则可以采用重试机制来解决问题。
拓展-延时双删
由于刚刚上面说的情况,先删除缓存,再更新数据库没有出现错误的情况下,也可能出现数据不一致的情况,采用延时双删解决:
- 删除缓存
- 更新数据库
- sleep n 毫秒
- 删除缓存
阻塞一段时间之后,再次删除缓存,就可以把这个过程中缓存中不一致的数据删除掉。而具体的时间,要评估你这项业务的大致时间具体设置。
而且对于先更新数据库,再删除缓存没有出现错误的情况下,也存在一种可能性:
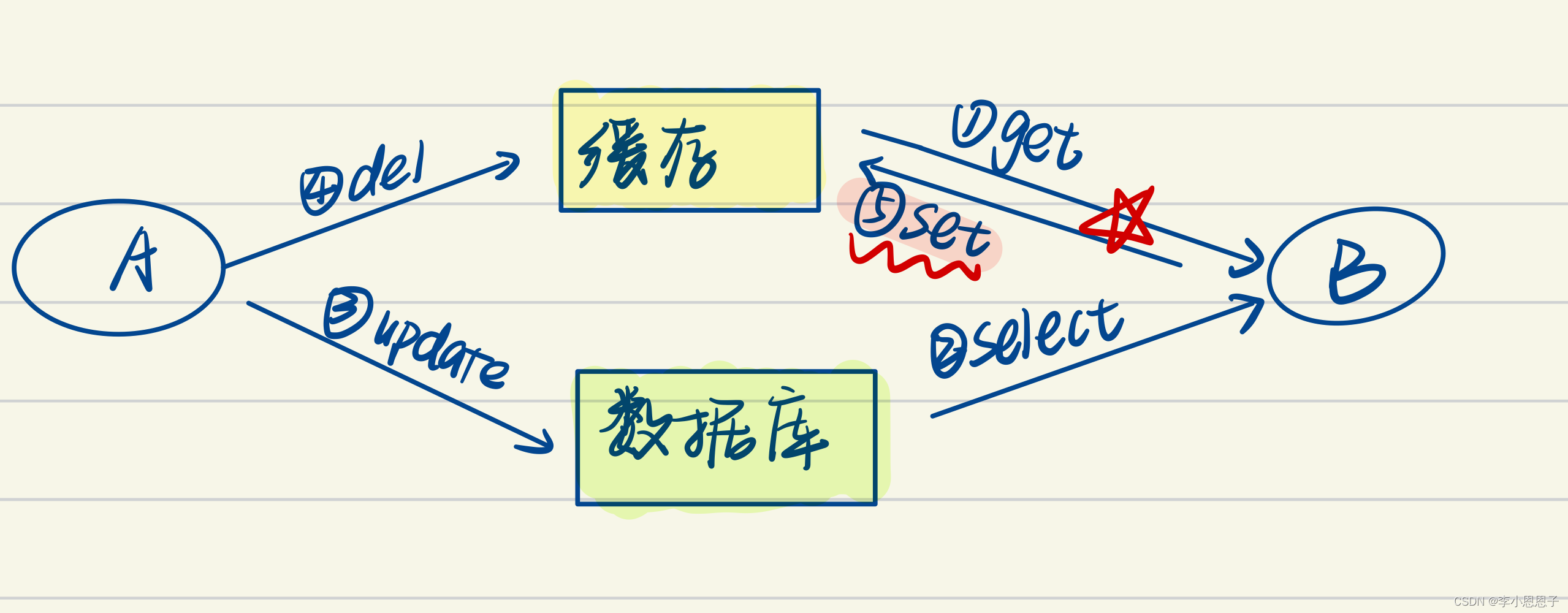
这种情况发生的概率很低,首先是缓存刚好失效的那一刻有读请求,并且这个读请求回写缓存的时间大于更新数据库的时间,正常的话回写缓存是比更新数据库要快的。
如果这种极端情况出现,那也需要采用延时双删策略,更新数据库后会删除缓存,此时新开一个线程等待n毫秒后再删除一次缓存,或将删除请求放入消息队列,保证缓存是新数据,或者使用消息队列定时消息,延时删除。
边栏推荐
- hot100 哈希
- Data platform scheduling upgrade and transformation | operation practice from Azkaban smooth transition to Apache dolphin scheduler
- PR字幕制作
- Become an Apache contributor, so easy!
- Compose Canvas line chart
- Linux c SQLite database usage
- 6. Combined data type
- Drools (2): drools quick start
- Summer Challenge harmonyos - hamster game based on arkui (JS)
- NFT digital collection system development: activating digital cultural heritage
猜你喜欢

WCF 入门教程二

Opencv learning drawing shapes and text

NFT数字藏品开发:数字藏品与NFT的六大区别

NFT digital collection system development: digital collections give new vitality to brands
![Rgb-t tracking - [dataset benchmark] gtot / rgbt210 / rgbt234 / vot-2019-2020 / laser / VTUAV](/img/10/40d02da10a6f6779635dc820c074c6.png)
Rgb-t tracking - [dataset benchmark] gtot / rgbt210 / rgbt234 / vot-2019-2020 / laser / VTUAV

NFT数字藏品开发:数字藏品助力企业发展

QT: list box, table, tree control

数据平台调度升级改造 | 从Azkaban 平滑过度到 Apache DolphinScheduler 的操作实践
RGB-T追踪——【数据集基准】GTOT / RGBT210 / RGBT234 / VOT-2019-2020 / LasHeR / VTUAV

Opencv learning warp Perspective
随机推荐
数据平台调度升级改造 | 从Azkaban 平滑过度到 Apache DolphinScheduler 的操作实践
NFT数字藏品开发:数字藏品助力企业发展
Idea -- use @slf4j to print logs
此章节用于补充
Leetcode 1184: distance between bus stops
又是一年开源之夏,1.2万项目奖金等你来拿!
Data platform scheduling upgrade and transformation | operation practice from Azkaban smooth transition to Apache dolphin scheduler
MySQL安装教程-手把手教你安装
In July, glassnode data showed that the open position of eth perpetual futures contract on deribit had just reached a one month high of $237959827.
ModuleNotFoundError: No module named ‘pip‘解决办法
如何对C盘进行扩容重新分区?
Talent column | can't use Apache dolphin scheduler? The most complete introductory tutorial written by the boss in one month [3]
Download and install the free version of typora
Apache DolphinScheduler&TiDB联合Meetup | 聚焦开源生态发展下的应用开发能力
This section is intended to supplement
NFT digital collection system development: the collision of literature + Digital Collections
QT: list box, table, tree control
Solve the problem that Chrome browser is tampered with by drug bullies
pycharm常用快捷键
0动态规划 LeetCode1567. 乘积为正数的最长子数组长度