当前位置:网站首页>【语音识别】MFCC特征提取
【语音识别】MFCC特征提取
2022-07-17 05:10:00 【Algorismus】
本次笔记主要从原理层面讲述了MFCC特征提取的流程,先是介绍了正弦波的离散化,之后介绍了奈奎斯特采样定理的由来,在讲述傅里叶变换的使用,最后将这些应用于MFCC特征提取算法。
信号与正弦波
高中学过三角函数:
x t = sin(2πf0t)
但是这个图像是连续的,点动成线,而计算机最喜欢处理的就是确切的点,但是一条线上有无数点,需要我们取其中某些点进行计算,而取点就是要考虑到相同间隔,又称:采样频率。
采样周期:ts,其倒数为采样频率fs = 1/ts
而采样点序号为n
从而得到离散化后的公式:
x n = sin(2πf0nts)
这里又会延伸一个新问题,采样频率越高自然越能保留原始波的信息,那么最低可以是多少?
先给结论:采样频率大于信号中最大频率的两倍。
fs/2 ≥ fmax
这就是奈奎斯特采样定理。
即,在原始信号的一个周期内,至少要采样两个点,才能有效杜绝频率混叠问题。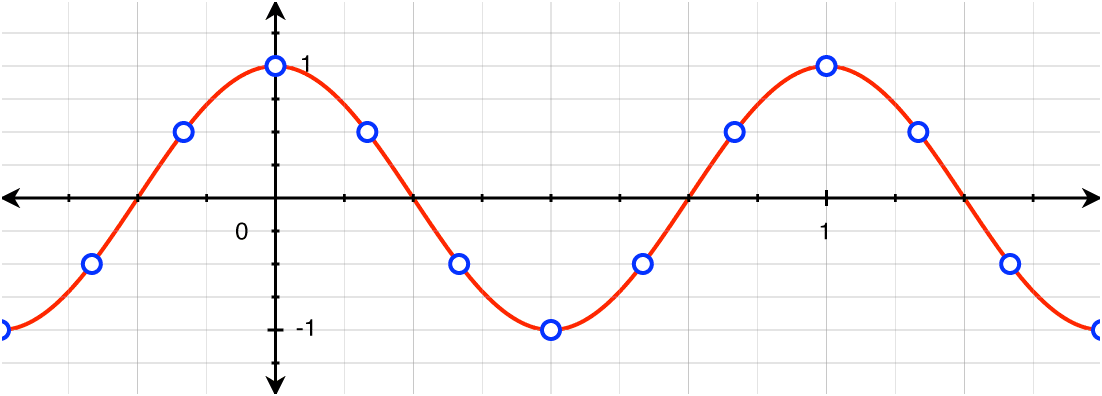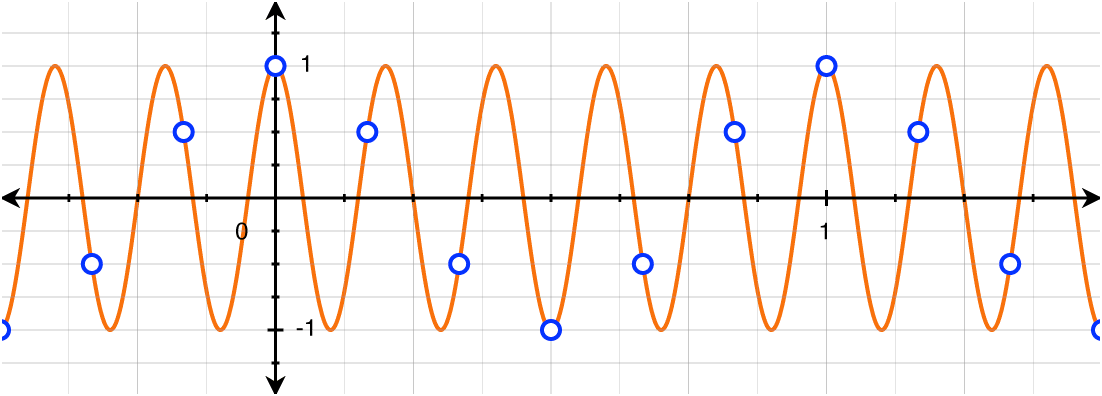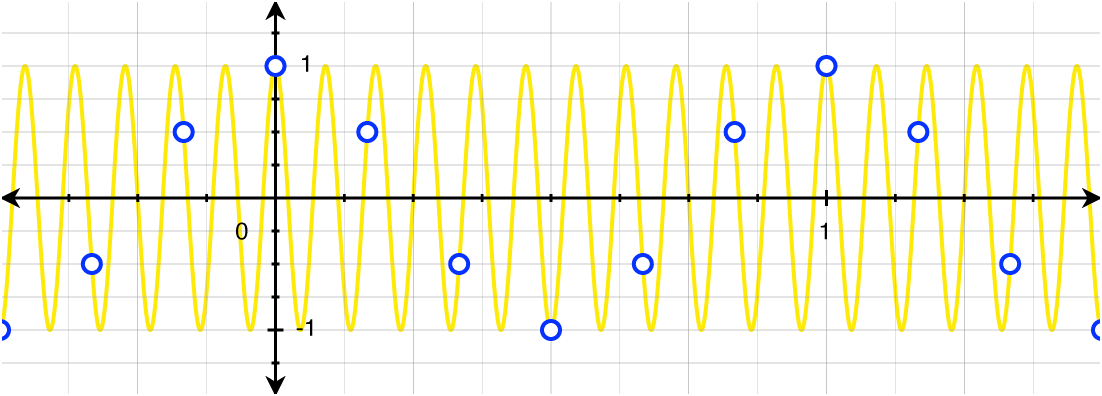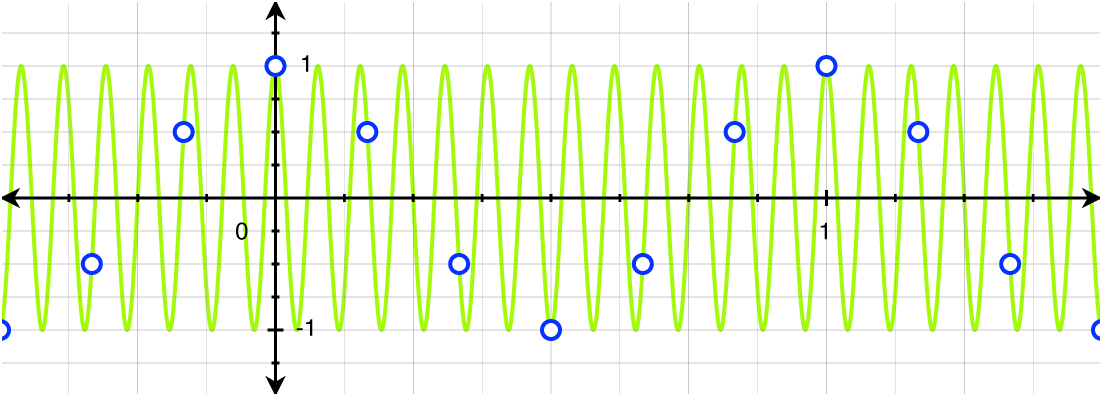
下面思考问题:给出正弦波采样后的离散序列可以恢复之前的正弦波波形吗?
不一定,下图可以直观的表现出来,如果一个周期内采样点少于2,那么会丢失很多信息,最直观的就是周期不同。
这种情况又叫做频率混叠。
离散傅里叶变换
在现实中声音通常是很多正弦波叠加而成,我们看到的波形就像是山水画中的重山叠嶂,如果要分析就需要一点点剥离,这个工作就像是纸雕艺术中剥离一层层的纸。于是我们从正面看要转换到侧面看,也就是从时域转到频域视角,这个操作叫做DFT。
·DFT
定义:给定一个长度为𝑁𝑁的时域离散信号Xn ,对应的离散频域序列Xm 为:
j = −1, e为自然对数底
m = 0,1,2 … ,N − 1, 频率索引
X m 为DFT的第m个输出
根据欧拉公式,DFT的公式还可以为:
DFT本质上是一个线性变换: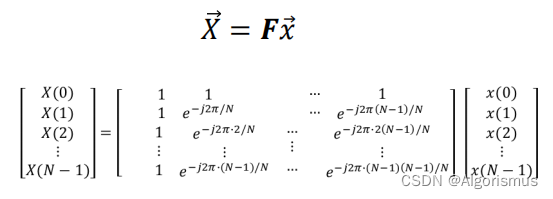
提问:所有信号都可以进行DFT吗?
当然不!只有时域离散且周期的信号才可以。非周期的离散信号需要进行周期延拓后,才可DFT。
这里有一个有意思的现象:
即在一个维度离散在另一个维度就会表现周期,连续则对应非周期。
这个可以从上面的那个DFT公式中得到一个思路,根据DFT的欧拉公式可以发现,当n为整数,那么公式每次加上的都是2π的整数倍,故而呈现周期性。所以任何离散的时域信号,频域都以2pi为周期重复。
当时域上为连续,接上个问题,这时候得到的频域将不会具重复的特征,自然也就不会有周期性。
资料来源:https://www.zhihu.com/question/26448935
·DFT的性质(4个)
1.对称性
图像如下:
证明如下:
实际应用:如图所示,我们只需要获取一半的点就可以获得整个图像的信息,因此只需要保留前N/2+1个点。比如在语音信号特征提取的时候一般使用512点DFT,实际上只需要257个点。
2.X(m)表示谱密度
DFT之后的频域序列X(m)的幅值实际上是一个“密度”的概念,通俗讲,即单位带宽上有多少信号存在。
如果对一个幅度为A实正弦波进行N点DFT,则DFT之后,对应频率上的幅度M和A之间的关系为: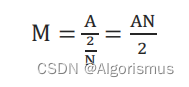
3.线性关系
即可以线性叠加,如果xsum(n)= x1(n) + x2(n),则对应的频域上有:Xsum(m) = X1(m)+ X2(m)
4.时移性
对x(n)左移k个采样点,得到xshift(n) = x(n − k),对xshift(n)进行DFT,有:
扩展:频率轴
频率分辨率:fs/N,表示最小的频率间隔。当N越大时,频率分辨率越高,在频域上,第m个点所表示的分析频率为:
从这个角度,我们可以理解为X(m)的幅值,体现了原信号中频率成分为m/N*fsHz 的信号的强度.
为了提高DFT频率轴的分辨率,而不会影响原始信号的频率成分。我们可以将时域长度为N的信号x(n) 补0,增加信号的长度,从而提高频率轴分辨率。对信号进行补0的操作,不会影响DFT的结果,这在FFT(快速傅里叶变换)中和语音信号分析中非常常见。
Eg.在语音特征提取阶段,对于16k采样率的信号,一帧语音信号长度为400个采样点,为了进行512点的FFT,通常将400个点补0,得到512个采样点,最后只需要前257个点。
快速傅里叶变换(FTT)
基本思想是把原始信号的N点序列,以此分解成一系列的短序列。充分利用DFT计算式中指数因子具有的对称性和周期性,进而求出这些短序列相应的DFT并进行适当组合,达到删除重复计算,减少乘法运算和简化结构的目的。
Fbank和MFCC特征提取
Fbank和MFCC特征目前仍是主要使用的特征,虽然有些工作尝试在语音识别任务上对波形建模,但是效果并没有超过基于频域的特征。流程图如下:
1.预加重
作用:可以提高高频部分的能量。
理由:高频信号在传递过程中,衰减较快,但是高频部分又蕴含很多对语音识别有利的特征,因此,在特征提取部分,需要提高高频部分能量。
预加重滤波器是一个一阶高通滤波器,给定时域输入信号x[n],预加重之后的信号为:
y[n]=x[n]-αx[n]
效果如下图所示:
从公式中可以看出,类似于求导,高频信号的变化率很高,那么在预加重后会大大加强,而低频信号则会被抑制,尤其是α接近1的时候。
2.加窗分帧
为什么需要分帧?
• 语音信号为非平稳信号,其统计属性是随着时间变化的,以汉语为例,一句话中包含很多声母和韵母,不同的拼音,发音的特点很明显是不一样的;
• 但是!语音信号又具有短时平稳的属性,比如汉语里一个声母或者韵母,往往只会持续几十到几百毫秒,在这一个发音单元里,语音信号表现出明显的稳定性,规律性(可以自己使用Audition观察一段语音)
• 在进行语音识别的时候,对于一句话,识别的过程也是以较小的发音单元(音素、字、字节)为单位进行识别,因此用滑动窗来提取短时片段,
Eg.对于采样率为16kHz的信号,帧长、帧移一般为25ms、10ms,即400和160个采样点。
分帧的过程,在时域上,即用一个窗函数和原始信号进行相乘:y[n]=w[n]x[n]
W[n]是窗函数,常见窗函数有:
下面是加窗之后的效果:
可以发现矩形窗主瓣窄,但是旁瓣较大,将其与原始信号的频域进行卷积会导致频率泄露。
加窗的过程实际上是在时域上将信号截断,窗函数与信号在时域相乘,就等于对应的频域表示进行卷积。
3.傅里叶变换
将上一步分帧后的语音帧,由时域变换到频域,取DFT系数的模(即|X(m)|),得到谱特征。
右图展示了语谱图的生成过程:
- 加窗分帧
- 将每一帧信号进行DFT(FFT),如第t帧信号,DFT系数为Xt m ,m = 0,1, … ,N
- 将每一帧DFT的系数按时间顺序排列,得到一个矩阵Y ∈ CT∗N,且Y t,m = Xt(m)
- 语谱图是一个三维图,横轴表示时间(t),纵轴表示频率,颜色的深浅表示当前时频点上幅度的大小|Y[t,m]|

4.梅尔滤波器组和对数操作
DFT得到了每个频带上信号的能量,但是人耳对频率的感知不是等间隔的,近似于对数函数
将线性频率转化为梅尔频率,梅尔频率和线性频率的转换关系:
梅尔三角滤波器组:根据起始频率、中间频率和截止频率,确定各滤波器系数:
梅尔滤波器组设计
• 确定滤波器组个数P
• 根据采样率fs,DFT点数N,滤波器个数P,在梅尔域上等间隔的产生每个滤波器的起始频率、中间频率和截至频率,注意,上一个滤波器的中间频率为下一个滤波器的起始频率(存在overlap)
• 将梅尔域上每个三角滤波器的起始、中间和截止频率转换线性频率域,并对DFT之后的谱特征进行滤波,得到P个滤波器组能量,进行log 操作,得到Fbank特征
MFCC特征在Fbank特征基础上继续进行IDFT变换等操作
倒谱 (Cepstral)
Inverse Fourier transform of logarithm of spectrum
倒谱分析分为四步,第一步信号加窗,第二步频谱分析,第三步频谱取对数,第四步傅里叶变换。它主要的功能是可以线性分离经卷积后的两个或多个分别的信号。


注意:取log有两个目的:
- 人耳对信号感知是近似对数的
- 对数使特征对输入信号的扰动不敏感
5.动态特征计算
一阶差分(Delta, Δ),类比速度,最简单的一阶差分计算方法:
二阶差分(Delta delta, ΔΔ),类比加速度,简单计算方法:
6.能量计算
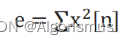
总结
MFCC特征总结
一般常用的MFCC特征维39维,包括:
• 12维原始MFCC
• 12维Δ
• 12维Δ Δ
• 1维能量
• 1维能量Δe
• 1维能量Δ Δe
MFCC特征一般用于对角GMM训练,各维度之间相关性小
Fbank特征一般用于DNN训练
阅读推荐:
《语音与语言处理:自然语言处理、计算机语言学和语音识别导论》Daniel Jurafsky;James H. Martin / 人民邮电出版社 / 2010-12
《Theory and Applications of Digital Speech Processing》Lawrence R. Rabiner, Ronald W. Schafer/电子工业出版社/2011-1
《understanding digital signal processing》Richard G. Lyons
关于作业的MFCC特征提取的GitHub地址:
https://github.com/MIRROR116/ASR-and-STT/blob/main/mfcc.py
边栏推荐
- 微信小程序之计算器
- C语言文件的操作
- replace限制文本框只能输入数字,数字和字母等的正则表达式
- Use of MySQL
- mysql的事务
- MySQL installation and configuration tutorial (super detailed)
- 【Bug解决】org.apache.ibatis.type.TypeException: The alias ‘xxxx‘ is already mapped to the value ‘xxx‘
- Wxml template syntax in wechat applet
- Coap在Andorid中的简单应用
- MySQL basic grammar dictionary
猜你喜欢

跨域和处理跨域

4. Neusoft cross border e-commerce data warehouse project - user behavior data acquisition channel construction of data acquisition channel construction (2022.6.1-2022.6.4)
Data Lakehouse的未来-开放

How can the thread pool be monitored to help developers quickly locate online errors?

Pointer array & array pointer
![[first launch in the whole network] automatic analysis of JVM performance problems](/img/be/fb47c05b5d9410d4df7df25ed3aad0.png)
[first launch in the whole network] automatic analysis of JVM performance problems

利用IDE打jar包

C language & bit field

微信小程序中的WXML模板语法

Composants communs des applets Wechat
随机推荐
关于Kotlin泛型遇到的问题
Constants and constant pointers
共用(联合)体
利用IDE打jar包
Talk about 20 negative teaching materials for writing code
Idea import local package
Ambari2.7.5 integration es6.4.2
配置tabBar和request网络数据请求
关于线程池中终止任务
List and map
2.东软跨境电商数仓项目技术选型
Online software testing training institutions lemon class and itest AI platform achieves strategic cooperation
微信小程序之计算器
Development progress of Neusoft cross border e-commerce warehouse
Pointer function of C language
Minor problems of GCC compiling C language in ubantu
Is the software testing training of lemon class reliable? This successful case of counter attack from the training class tells you
SQL time comparison
Coap在Andorid中的简单应用
9.数据仓库搭建之DIM层搭建