当前位置:网站首页>UCAS. Deep learning Final review knowledge points summary notes
UCAS. Deep learning Final review knowledge points summary notes
2022-07-19 14:54:00 【Qiao Qing】
- How to calculate convolution kernel on a picture ,padding, Feature map size , Parameter quantity
- Figure convolution network , Given the state of several points , Weight matrices , Perform a graph convolution , Find the result
- Comparison of several activation functions
- sigmoid:
- Sigmoid The output of the function is mapped to (0,1) Between , Monotone continuous , Limited output range , Optimization and stability , Can be used as output layer . It is closest to biological neuron in physical sense .
- It's easy to produce gradients that disappear , Cause problems with training .
- tanh:
- Than Sigmoid Function converges faster .
- comparison Sigmoid function , Its output With 0 Centered .
- Still unchanged Sigmoid The biggest problem with functions —— The gradient due to saturation disappears .
- ReLU:
- ReLU stay SGD It can converge quickly . allegedly , That's because it's linear 、 Unsaturated form .
- It can be implemented more easily .
- It effectively alleviates the problem of gradient disappearance .
- As the training goes on , There may be neuronal death , Where weights cannot be updated .
- Fully connected network , How to find the gradient of loss function relative to network parameters
- Causes and solutions of gradient vanishing explosion
- In the process of back propagation, the derivation of the activation function is needed , If the derivative is greater than 1, As the number of network layers increases, the gradient update will increase in the way of exponential explosion, which is called gradient explosion . Again, if the derivative is less than 1, Then, with the increase of the number of network layers, the gradient update information will decrease exponentially, which is the disappearance of the gradient . therefore , The gradient disappears 、 The explosion , The fundamental reason lies in the back propagation training principle , It's a congenital deficiency .
- On the other hand , If you choose sigmoid Activation function , The derivative is less than 1, It is also easy to cause the gradient to disappear
- Solution :
- Change the activation function :ReLU,leak ReLU
- Batchnorm, Batch normalization , The output signal will be... By normalized operation x Normalized to the mean value of 0, The variance of 1 Ensure the stability of the network . Accelerate the convergence speed of the network , The effect of improving training stability .

- Residual structure : As the network depth increases , Network accuracy is saturated , There's even a drop . Short circuit connection .


- GRU、LSTM, What problem to solve
- Problem solved :RNN The gradient of propagation tends to disappear in many stages ( Most of the time ) Or explosion ( Relatively few ). Compared to short-term interactions ,RNN Difficult to Modeling long-term dependencies . in addition ,RNN It's not always easy to train .LSTM Can solve The gradient disappears problem !
- LSTM: Input gate 、 Output gate 、 Oblivion gate

Bear in mind :Wh+Ux
- GRU: Reset door 、 Update door

- RBM、DBN And GAN、VAE contrast , Advantages, disadvantages and characteristics
- AE: Self coding machine

The feature dimension is reduced in the process ! Learn low dimensional representation , Hopefully, it can be reconstructed losslessly , The reconstruction error is minimum
- RBM Limited Boltzmann machine 、DBN Deep confidence network
RBM You can learn the internal characteristics of data , fitting Discrete distribution , The base In the energy model

DBN Layer by layer unsupervised training RBM, Finally, there is supervision and fine-tuning

- GAN


- VAE
VAE A model is one that contains Hidden variables The generation model of , It uses neural network training to get two functions ( Also known as Inferential network and generative network ), , in turn, Generate data that is not included in the input data . Based on the probability .
VAE The middle hidden layer obeys Gaussian distribution ,AE There is no distribution requirement for the hidden layer in .
During training ,AE Train to get Encoder and Decoder Model , and VAE In addition to getting these two models , The distribution model of hidden layer is also obtained ( The mean and variance of Gaussian distribution )
AE Only input data can be reconstructed X, and VAE Can be generated with Input data new data of some characteristics and parameters .
Compared with traditional machine algorithms ,GAN There are three advantages :
- First GAN The performance of the model is better , Generate clear samples ;
- second GAN The framework is OK Train any kind of generator network ;
- Third GAN For a variable The probability of random occurrence cannot be calculated The situation of .
- Basic ideas of intensive learning 、 Basic elements 、 Application scenarios
The basic idea : agent , Environmental Science , state , action , Reward , Maximize the desired reward , The combination of supervised learning and reinforcement learning
Definition of Markov decision process :![]() , state , action , Reward , Transfer probability , Reward decay factor
, state , action , Reward , Transfer probability , Reward decay factor
Behrmann optimality of state estimation function , Bellman's equation :
 , Don't forget the weight attenuation factor !
, Don't forget the weight attenuation factor !
- Several kinds of attention
The attention mechanism is right Enter the weight assigned Focus on , The attention mechanism was first used in the encoder - decoder (encoder-decoder) in , The attention mechanism obtains the input variables of the next layer by weighted averaging the hidden states of all time steps of the encoder .
- soft attention: Easy to implement : Generate a distribution at the input location , Reweighting properties And as an input feed , Use a space transformer network Follow any input position
- hard attention: Choose one according to probability , Focus on a single input location , Cannot use gradient descent ! Intensive learning is needed !
- Cyclic neural network :RNN Structure 、 Optimize

Notice the three weight matrices !U、V、W

It depends on the input and the output of the previous moment
- Back propagation :BPTT
Losses and gradients are for all t Add up !
U、V、W Is Shared !
- For machine translation :
边栏推荐
- Codeforces Round #808 (Div. 1)(A~C)
- Explain the operation of C language file in detail
- Code runner for vs code, with more than 40million downloads! Support more than 50 languages
- How to quickly realize Zadig single sign on on authoring?
- [Luogu p3220] and not (construction) (digit DP) (inference)
- MongoDB分片集群搭建
- Excellent jar package startup shell script collection
- The first step of agile: turn "iteration" into "sprint" and start!
- 【MQTT从入门到提高系列 | 07】MQTT3.1.1之链路保活及断开
- 模块1 作业
猜你喜欢

Deployment principle

定时任务,vim直接创建修改用户
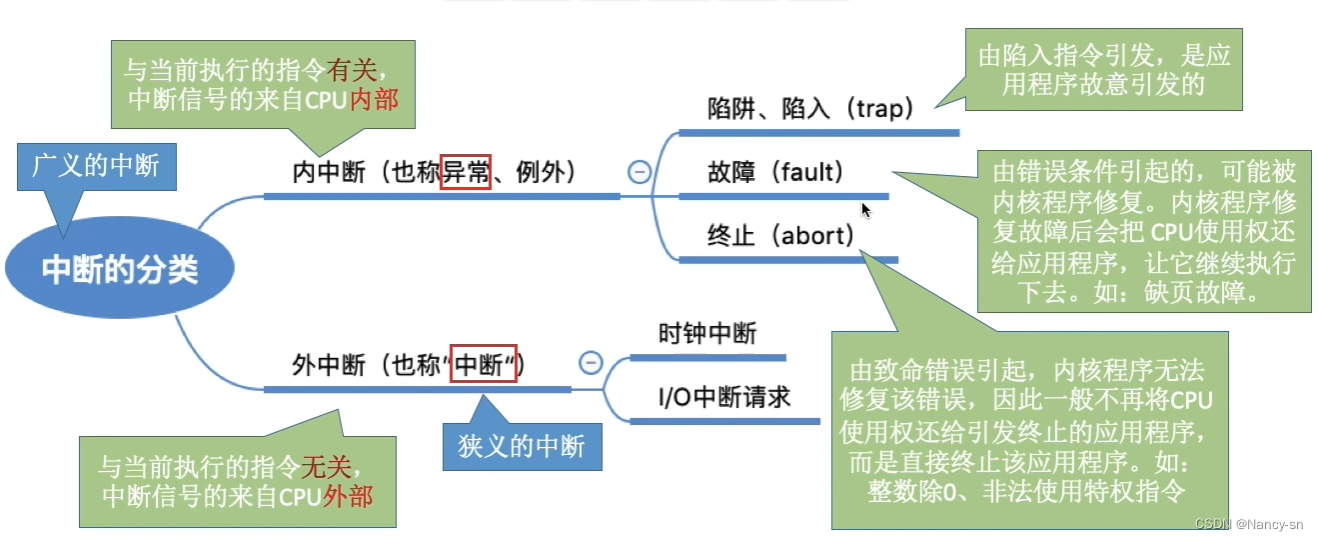
中断的分类
Scheduled tasks, VIM directly creates and modifies users

Integrated video processing card based on Fudan micro FPGA + Huawei hisilic hi3531dv200 + Mji innovative MCU

Explain the operation of C language file in detail

Comparison of two virtual machines
QChartView添加在QGridLayout中时覆盖了之前的控件

【萌新解题】四数之和

kube-proxy & Service & Endpoint
随机推荐
揭开服务网格~Istio Service Mesh神秘的面纱
[Axi] interpret the additional signals of the Axi protocol (QoS signal, region signal, and user signal)
Unveil the mystery of service grid istio service mesh
Load Objective-C at runtime
06--- characteristics of light in media
分布式事务总结
Display module in pyGame
Read the paper: temporary graph networks for deep learning on dynamic graphs
MySQL read / write separation
Classification of blocks
Codeforces Round #808 (Div. 1)(A~C)
MySQL CPU usage is soaring. How to locate who is occupying it
ospf-LSA
[Luogu p3220] and not (construction) (digit DP) (inference)
MySQL index (III)
2021 年全国职业院校技能大赛 网络搭建与应用赛项
Integrated video processing card based on Fudan micro FPGA + Huawei hisilic hi3531dv200 + Mji innovative MCU
Explain C language dynamic memory management in detail
[cute new problem solving] sum of four numbers
[flask introduction series] exception handling