当前位置:网站首页>Seq2seq and attention model learning notes
Seq2seq and attention model learning notes
2022-07-26 08:19:00 【I am I】
Sequence to Sequence (seq2seq) and Attention Link to the original text
seq2seq It is the application of sequence to sequence , In order to solve the problem of unequal length of output and output , Now it has been widely used in, for example Machine translation , Man machine Q & A , Picture text description Wait for content generation . The sequence length of input and output is variable !!

encoder-decoder frame :

condetional language models( Conditional language model )
In the original language model, input and output is a type of data , And in the CLM Can be other source information , For example, picture information , Language , Voice information, etc .
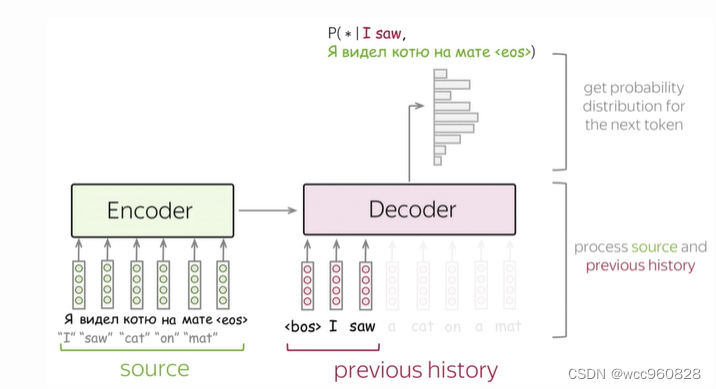
The specific work flow is as follows :
Input the source word and the previously generated target word into the network ;
Get the vector representation of the context from the network decoder ( Source and previous target );
According to this vector , Forecast next token Probability distribution of

decoder The resulting vector passes through a linear layer after softmax Function to the next token Probability .
Simple model : With two RNNs Composed of Encoder and Decoder
The simplest encoder - The decoder model consists of two RNN (LSTM) form : One for encoder , The other is for decoder . Encoder RNN Read source sentence , The final state is as decoder RNN Initial state of . Hope it is the final encoder state “ code ” All the information about the source , The decoder can generate the target sentence based on this vector .
This model can be modified differently : for example , Encoder and decoder can have several layers . for example , stay Sequence to Sequence Learning with Neural Networks This multi-layer model is used in this paper - This is one of the first attempts to solve sequence to sequence tasks using neural networks .
In the same paper , The author looked at the last encoder status and visualized several examples - As shown below . Interestingly , The expressions of sentences with similar meanings but different structures are very similar !
cross-entropy loss( Cross entropy loss function )
The standard loss function is the cross entropy loss function , The target distribution is p*, The predicted distribution is p

because pi* It's not equal to 0, So we get :

At every step , We maximize the probability that the model assigns to the correct tag . See the illustration of a single time step .

For the whole example, the loss will be −∑t=1->n log(p(yt|y<t,x)). Look at the illustration of the training process (the illustration is for the RNN model, but the model can be different).

Attention attention
The Problem of Fixed Encoder Representation
In the model we see so far , The encoder compresses the entire source statement into a vector . It's very hard. —— The number of possible meanings of the source is infinite . When the encoder is forced to put all the information into a single vector (512) In the middle of the day , It is likely to forget something .
Not only is it difficult for the encoder to put all the information into one vector —— This is also difficult for the decoder . The decoder can only see a representation of the source . however , In each generation step , Different parts of the source may be more useful than others . But in the current situation , The decoder must extract relevant information from the same fixed representation —— It's not an easy thing .

Attention mechanism is part of neural network . In each decoder step , It determines which source parts are more important . In this setting , The encoder does not have to compress the entire source into a single vector - It provides representation for all source tags ( for example , all RNN Status, not the last ).
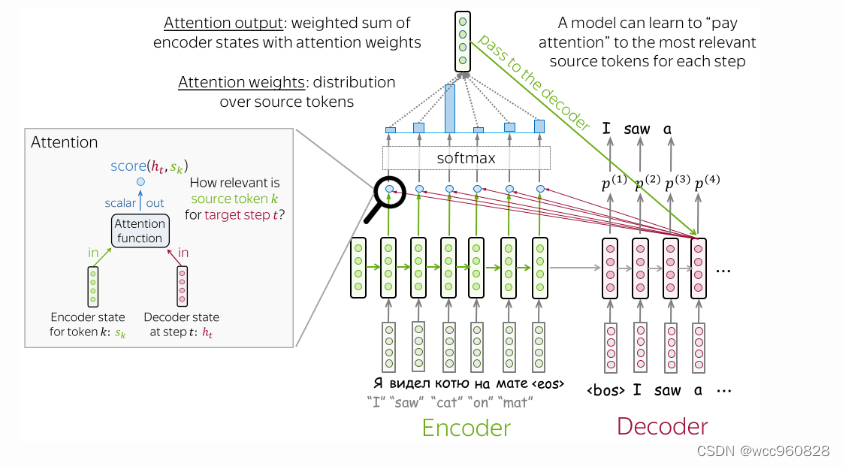
The calculation scheme is as follows :

How to calculate the attention score : There are several ways


The most popular way to calculate attention scores is :
Dot product - The easiest way ;
Bilinear functions ( also called “Luong attention”)—— For papers Effective Approaches to Attention-based Neural Machine Translation;
Multilayer perceptron ( also called “Bahdanau attention”)—— The method proposed in the original paper .
边栏推荐
- Share high voltage ultra low noise LDO test results
- vscode国内的镜像服务器加速
- This is a picture
- General Dao interface design
- Ten thousand words long article | deeply understand the architecture principle of openfeign
- 正则表达式作业
- Let's talk about the three core issues of concurrent programming.
- JSP built-in object (implicit object)
- 2022-7-5 personal qualifying 2 competition experience
- Bee guitar score high octave and low octave
猜你喜欢

2022-7-7 personal qualifying 4 competition experience
R language foundation

日常一记(11)--word公式输入任意矩阵

要不你给我说说什么是长轮询吧?

One click deployment lamp and LNMP architecture

BGP routing principle

Burp suite Chapter 6 how to use burp spider

Matplotlib learning notes

Burp suite Chapter 8 how to use burp intruder

Basic introduction of JDBC
随机推荐
一点一点理解微服务
Exam summary on June 27, 2022
matplotlib学习笔记
Regular expression job
Storage of drawings (refined version)
C# 获取选择文件信息
An empirical study on urban unemployment in Guangxi (Macroeconomics)
[endnote] detailed explanation of document template layout syntax
OSPF总结
Day 3 homework
Let's talk about the three core issues of concurrent programming.
Matplotlib learning notes
flex三列布局
Burp suite Chapter 4 advanced options for SSL and proxy
Burp suite Chapter 9 how to use burp repeater
Basic introduction of JDBC
Template summary
美女裸聊一时爽,裸聊结束火葬场!
Traversal mode of list, set, map, queue, deque, stack
Basic configuration of BGP