当前位置:网站首页>Flink introduction to practice - phase II (illustrated runtime architecture)
Flink introduction to practice - phase II (illustrated runtime architecture)
2022-07-19 07:45:00 【Top master cultivation plan】
System architecture

Submit the workflow
Advanced Abstract Perspective

Independent mode

Yarn colony
Conversational mode
1. First for yarn Apply for one JobManager

2.JobManager Processing tasks

Single operation mode

Data flow chart

Parallelism
flow chart

experiment
public class FlinkSoctet {
public static void main(String[] args) throws Exception {
// Get the execution environment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> initData = env.socketTextStream("master",9997);
SingleOutputStreamOperator<Tuple2<String, Integer>> map = initData.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String item, Collector<String> out) throws Exception {
String[] resItem = item.split(" ");
for (String s : resItem) {
out.collect(s);
}
}
}).setParallelism(1).map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String item) throws Exception {
return Tuple2.of(item, 1);
}
}).setParallelism(2);
// For the stream data of the resulting tuple , Group aggregation
map.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> value) throws Exception {
return value.f0;
}
}).sum(1).setParallelism(3).print();
// Because it is a stream handler , So here we need to constantly implement
env.execute();
}
}The result

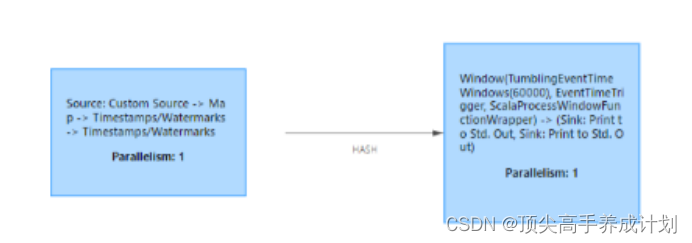
Conclusion
- It can be seen that Flink Parallelism and Spark The concept of repartition is very similar to
Chain of operators
experiment
public class FlinkSoctet {
public static void main(String[] args) throws Exception {
// Get the execution environment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> initData = env.socketTextStream("master",9997);
env.setParallelism(1);
SingleOutputStreamOperator<Tuple2<String, Integer>> map = initData.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String item, Collector<String> out) throws Exception {
String[] resItem = item.split(" ");
for (String s : resItem) {
out.collect(s);
}
}
}).map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String item) throws Exception {
return Tuple2.of(item, 1);
}
});
// For the stream data of the resulting tuple , Group aggregation
map.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> value) throws Exception {
return value.f0;
}
}).sum(1).print();
// Because it is a stream handler , So here we need to constantly implement
env.execute();
}
}result

Conclusion
- You can see the operators of one-to-one relationship. They execute in a task
- If it's one to many , Then it is to separate two tasks
- This and Spark Inside Shuffle Split Stage It's like
Execution diagram


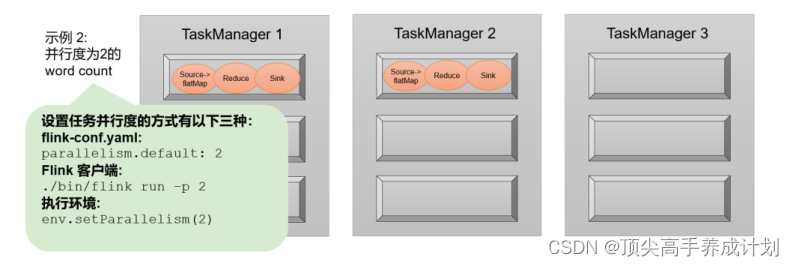
Mission (Tasks) And task slots (Task Slots)
theory
Task to task slot sharing

The following is an example of allocation Relationship between task slot and parallelism




experiment
Preparation
The current situation is 3 individual task slots, If we set the parallelism to 5 What's the situation

Experimental code
public class FlinkSoctet {
public static void main(String[] args) throws Exception {
// Get the execution environment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> initData = env.socketTextStream("master",9997);
env.setParallelism(5);
SingleOutputStreamOperator<Tuple2<String, Integer>> map = initData.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String item, Collector<String> out) throws Exception {
String[] resItem = item.split(" ");
for (String s : resItem) {
out.collect(s);
}
}
}).map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String item) throws Exception {
return Tuple2.of(item, 1);
}
});
// For the stream data of the resulting tuple , Group aggregation
map.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> value) throws Exception {
return value.f0;
}
}).sum(1).print();
// Because it is a stream handler , So here we need to constantly implement
env.execute();
}
}result

Report errors

Task scheduling
According to your own requirements , To distribute reasonably task In different taskslots, Understanding can , because taskslots Sharing is an optimization of task execution
边栏推荐
- Introduction to arm development environment
- 解决Mysql (1064) 错误: 1064 - You have an error in your SQL syntax;
- Prevent blackmail attacks through data encryption schemes
- Spark3.x entry to mastery - stage 7 (spark dynamic resource allocation)
- Review of 4705 NLP
- Development board training: multi task program under stm32
- 修改checkbox样式
- Cracking Metric/Business Case/Product Sense Problems
- nodejs
- Spark3.x entry to proficiency - stage 6 (RDD advanced operator explanation & Illustration & shuffle tuning)
猜你喜欢

Review of 4705 NLP

High concurrency day02 (concurrent package)
实时数据仓库-从0到1实时数据仓库设计&实现(SparkStreaming3.x)

解决Mysql (1064) 错误: 1064 - You have an error in your SQL syntax;

Summary of Statistics for Interview

AB Testing Review

MongoDB 索引

What is the difference between SD NAND and nandflash?

Hypothesis testing
京东购买意向预测(三)
随机推荐
CAN FD如何应用Vector诊断工具链?
Network knowledge-04 network layer IPv4 protocol
Configuration and use of cookies and sessions
Solution to the conflict between security automatic login and anti CSRF attack
Flink entry to practice - phase I (cluster installation & use)
Gnome installs the extension (version 40.1, openSUSE tumblefeed).
Spark3.x-mysql method of actual combat to achieve Kafka precise one-time consumption
Discussion on blackmail virus protection
Freebsd12 install gnome3 graphical interface
Spark3.x-practical double flow join (window and redis implementation method and template code)
Read gptp in a quarter of an hour
Pytorch随记(1)
Flink entry to actual combat - phase III (datastream API)
shader入门之基础光照知识
RNN卷积神经网络
MySql
Telnet installation
修改checkbox样式
How does Jenkins set the mailbox to automatically send mail?
SQL skimming summary SQL leetcode review