当前位置:网站首页>Deep learning 7 deep feedforward network
Deep learning 7 deep feedforward network
2022-07-19 08:12:00 【Water W】
This article follows the previous one Deep learning 6 Linear regression realizes 2_ water w The blog of -CSDN Blog
Catalog
2、 A simple network for solving XOR problems
1、 Structure and representation of feedforward neural network :
2、 Hidden units —— Activation function :
4、 Feedforward neural network parameter learning
Deep feedforward network
Artificial neural network
1、 Human brain neural network
The human brain is made up of Neuron 、 Glial cells 、 The nerve stem is thin Cell and blood vessel formNeuron (neuron) Also called nerve cells (nerve cell), It is the most basic unit in the nervous system of the human brainThe nervous system of the human brain contains nearly 860 Billion NeuronsEach neuron has thousands synaptic Connect with other neuronsHuman brain neurons are connected into a huge complex network , The total length can reach Thousands of kilometers

(1) Neuronal structure :

(2) Information transmission between neurons :

(3) Artificial neuron :

(4) Artificial neural network :

2、 A simple network for solving XOR problems
(1) Perceptron solves different 、 or 、 Non and XOR problems :
Input is [𝑥1; 𝑥2] Single layer single neuron ( The input layer is not included in the number of layers ), Adopt step activation function .

(2) Double layer perceptron —— A simple neural network
Input is still [𝑥1; 𝑥2], Let the network contain two layers :

Give a solution to the XOR problem :

explain : Nonlinear space transformation

3、 Neural network structure
(1) Universal approximation theorem :

(2) The universal approximation theorem is applied to Neural Networks :
According to the universal approximation theorem , Those who have Linear output layer and At least one Use “ extrusion ” Property of the activation function Hidden layer A neural network , As long as the number of hidden layer neurons is enough , It can approximate any bounded closed set function defined in real number space with any precision .neural network As a “ universal ” function To use , It can be used for complex feature transformation , Or approximate a complex conditional distribution .

(3) Why depth :
Single hidden layer network Can approximate any function , But it's The scale may be huge* In the worst case , need Exponential hidden units To approximate a function [Barron, 1993]With Increase in depth , Online Indicates that the ability increases exponentially* have 𝑑 Inputs 、 Depth is 𝑙 、 Each hidden layer has 𝑛 A unit deep rectification network can be described The number of linear regions of is , signify, Describe the ability in depth Exponential level
Deeper networks have better generalization ability : The performance of the model continues to improve with the increase of depth
Increase in the number of parameters not necessarily It will definitely improve the effect of the model :Deeper models tend to perform better , Not just because the model is bigger . The function you want to learn should be obtained by compounding many simpler functions .
(4) Common neural network structure :
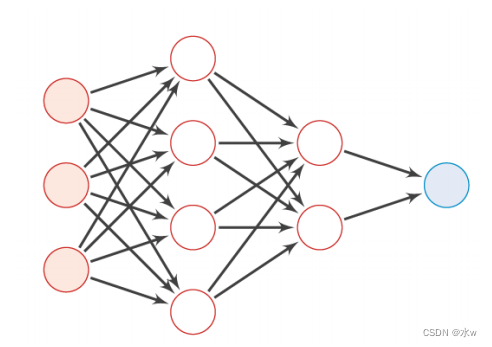


Other structural design considerations : Besides depth and width , The structure of neural network also has diversity in other aspects .
- Change the connection between layers
* Each cell in the previous layer is only connected to a small subset of cells in the next layer* The number of parameters can be greatly reduced* The specific connection mode is highly dependent on the specific problem
- Add jump connection
* From 𝑖 Layer and the first 𝑖 + 2 Establish connections between layers or even higher* It makes it easier for the gradient to flow from the output layer to the layer closer to the input , Conducive to model optimization
Feedforward neural networks
1、 Structure and representation of feedforward neural network :
Feedforward neural networks (Feedforward Neural Network, FNN) Is the first invention of simple artificial neural network feedforward neural network is often called Multilayer perceptron (Multi-Layer Perceptron, MLP), But this name is not very reasonable ( The activation function is usually not a discontinuous step function used by the perceptron );The first 0 Layer is the input layer , The last layer is the output layer , Other intermediate layers are called hidden layers ;The signal propagates unidirectionally from the input layer to the output layer , There is no feedback in the whole network , You can use one Directed acyclic graph Express ;
Symbolic representation of Feedforward Neural Networks :


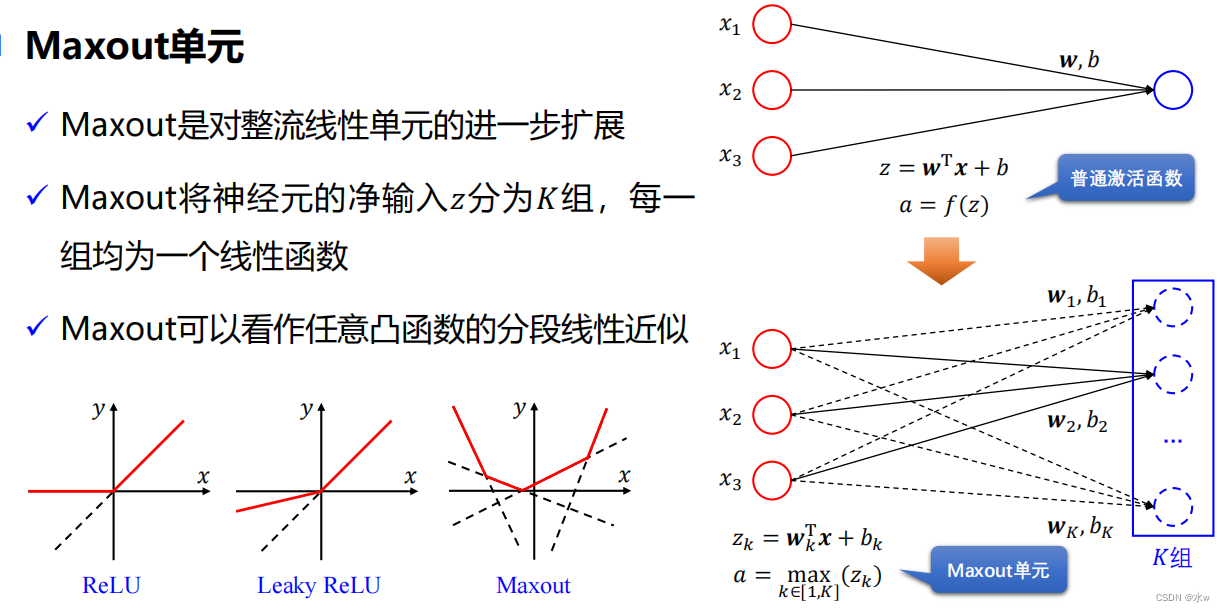
2、 Hidden units —— Activation function :
The design of hidden units is a very active research field , But there is no clear guiding principle at presentThe nature of the activation function requires :* Continuous and derivable ( A few points are allowed to be non derivable ) Of nonlinear function . The differentiable activation function can directly use numerical optimization method to learn network parameters .* The activation function and its derivative should be as simple as possible , It can improve the efficiency of network computing .* Activate the The value range of derivative function should be in a suitable interval , It can't be too big or too small , Otherwise, it will affect the efficiency and stability of training .
(1)Sigmoid Type of function :

Rectifier linear unit (ReLU) Functions and their extensions :


Other activation functions :

3、 output unit
Linear output unit ![]()
* Linear output units are often used to generate The mean of conditional Gaussian distribution* fit Continuous value prediction ( Return to ) problem* Based on Gaussian distribution , Maximize likelihood ( Minimize negative log likelihood ) Equivalent to Minimizing mean square error , Therefore, the linear output unit can adopt the mean square error loss function :among 𝑦(𝑛) For real value , 𝑛 For the predicted value , 𝑁 Sample size .
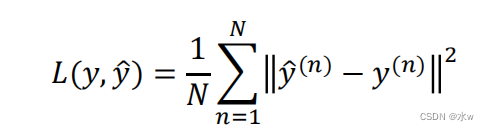


* Sigmoid Output units are often used to output Bernoulli Distribution* It is suitable for the problem of dichotomy* Sigmoid The output unit can adopt Cross entropy loss function :


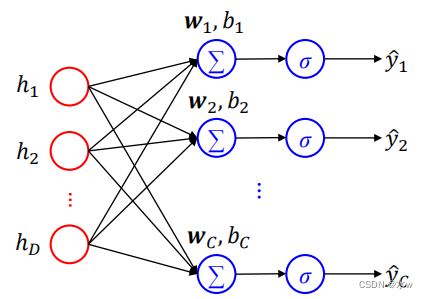
Softmax unit :
* Softmax Output units are often used to output Multinoulli Distribution* Suitable for multi classification problems* Softmax The output unit can adopt Cross entropy loss function :

4、 Feedforward neural network parameter learning
Learning rules* Suppose that the neural network adopts the cross entropy loss function , For a sample (𝒙, 𝑦), Its Loss function by
gradient descent* Based on learning criteria and training samples , Network parameters can be learned by gradient descent method ,* The partial derivative of each parameter can be obtained one by one through the chain rule , But it's inefficient ;* It is often used in the training of Neural Networks Back propagation algorithm To calculate the gradient efficiently ;

Back propagation algorithm
1、 Differential chain rule


2、 Back propagation algorithm
Given a sample (𝒙, 𝒚), Suppose the output of neural network is y^, The loss function is 𝐿(𝒚, 𝒚^), The gradient descent method requires calculation The partial derivative of the loss function with respect to each parameter .
How to calculate the partial derivatives of parameters in feedforward neural network —— Back propagation (Back Propagation,BP) Algorithm
Consider seeking the third 𝑙 Parameters in the layer 𝑾(𝑙) and 𝒃(𝑙) Partial derivative of , because 𝒛(𝑙) = 𝑾(𝑙)𝒂(𝑙−1) + 𝒃(𝑙), According to the chain rule :




 Code process :
Code process :

边栏推荐
- 代码学习(DeamNet)CVPR | Adaptive Consistency Prior based Deep Network for Image Denoising
- Csp-2020-6- role authorization
- Will it be a little late to realize your "wonderful" 360?
- Kingbasees can realize any of MySQL by constructing an aggregate function_ Value function.
- redis集群
- 深度学习之 7 深度前馈网络2
- Interview question: outer margin folding problem (bug of block level elements in ordinary document flow)
- [C classes and objects] - Methods and class and object programming in C
- “韭菜”是怎么把钱送给“镰刀”的? 2020-03-07
- How to use curl in Jenkins pipeline and process response results
猜你喜欢

DP dynamic planning enterprise level template analysis (Digital triangle, rising sequence, knapsack, state machine, compressed DP)
![Paddleserving服务化部署 tensorrt报错, shape of trt subgraph is [-1,-1,768],](/img/15/5dde91261a44fcfeda4d8436bb8559.png)
Paddleserving服务化部署 tensorrt报错, shape of trt subgraph is [-1,-1,768],
DP动态规划企业级模板分析(数字三角,上升序列,背包,状态机,压缩DP)

Bean、

深圳保诚笔试记录
真实案例:系统上线后Cpu使用率飙升如何排查?
Yolov5 label and establish your own data set

Array exercise 3
![[MySQL] transaction: basic knowledge of transaction, implementation principle of MySQL transaction, detailed explanation of transaction log redolog & undo](/img/88/282a6ddfb37944e9cacc62c202364d.png)
[MySQL] transaction: basic knowledge of transaction, implementation principle of MySQL transaction, detailed explanation of transaction log redolog & undo

redis缓存雪崩、穿透、击穿
随机推荐
redis6新功能
Is there any cumulative error in serial communication and the requirements for clock accuracy
Ku115 FPGA high performance 10G Optical fiber network hardware accelerator card / 2-way 10G Optical fiber data accelerator card
xgboos-hperopt
175. Combine two tables (MySQL database connection)
Will it be a little late to realize your "wonderful" 360?
the max_ iter was reached which means the coef_ did not converge “the coef_ did not converge“
DP dynamic planning enterprise level template analysis (Digital triangle, rising sequence, knapsack, state machine, compressed DP)
Standard Version (release and changelog Automation)
Is it necessary to buy pension insurance? What are the pension products suitable for the elderly?
[C# 变量常量关键字]- C# 中的变量常量以及关键字
【C语言】自定义类型详解:结构体、枚举、联合
Conversation technology [dark horse introduction series]
cad填充转多段线脚本
通过Dao投票STI的销毁,SeekTiger真正做到由社区驱动
Use of fiddler packet capturing tool
Bean、
Jira --- workflow call external api
First experience of openvino machine learning
csp-2020-6-《角色授权》