当前位置:网站首页>Regular replace group (n) content
Regular replace group (n) content
2022-07-19 05:41:00 【Spring and autumn of Qin and Han Dynasties】
Regular replacement of specified content should have been a very easy thing , But for some reason , Replace the specified group The content of must be realized by oneself .
Set a requirement first , Put the following string number 1 One of the 01 Switch to 1234, The first 2 individual 01 Switch to 2345, Of course, there may be more 01 Or other strings :
String hex = "00 00 00 01 00 01";
String regex = "[0-9a-zA-Z\\s]{6}[0-9a-zA-Z]{2}\\s([0-9a-zA-Z]{2})\\s[0-9a-zA-Z]{2}\\s([0-9a-zA-Z]{2})";
The parentheses in the regular are the extraction parameters , The purpose is to replace these parameters with something else .
To explore the API
Java Of String Class can be used replaceAll/replaceFirst Regular replacement content , But that's the whole picture , For the entire string ;
//String.java
public String replaceAll(String regex, String replacement) {
return Pattern.compile(regex).matcher(this).replaceAll(replacement);
}
public String replaceFirst(String regex, String replacement) {
return Pattern.compile(regex).matcher(this).replaceFirst(replacement);
}
and Matcher Class appendReplacement/appendTail( In fact, in the above String The two methods of class are also Matcher Class ), To no avail ;
public Matcher appendReplacement(StringBuffer sb, String replacement)
public StringBuffer appendTail(StringBuffer sb)
The former appendReplacement Apply to Differential substitution , That is, the rules used for matching will not match anything else , Otherwise it would be like this :
String hex = "00 00 00 01 00 01";
String regex1 = "[0-9a-zA-Z]{2}";
Pattern pattern = Pattern.compile(regex1);
Matcher matcher = pattern.matcher(hex);
StringBuffer sb = new StringBuffer();
while (matcher.find()){
matcher.appendReplacement(sb, "1234");
}
System.out.println(sb.toString());
Output :
1234 1234 1234 1234 1234 1234
Replace the qualified characters , But it's obviously not possible here ;
the latter appendTail Only the last matching content will be added to StringBuffer in .
So in API I haven't found a suitable method by myself , It can only be realized by itself .
Get index
What to replace , First of all, you need to know the location index of the original content that needs to be replaced , However, where does this index come from ?Matcher How to use group(n) Intercepted string ?
String hex = "00 00 00 01 00 01";
String regex = "[0-9a-zA-Z\\s]{6}[0-9a-zA-Z]{2}\\s([0-9a-zA-Z]{2})\\s[0-9a-zA-Z]{2}\\s([0-9a-zA-Z]{2})";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(hex);
if (matcher.matches()) {
int count = matcher.groupCount();
for (int i = 1; i <= count; i++) {
System.out.println(matcher.group(i));
}
}
Output :
01
01
Don't ask , Asking is group(n) There must be something strange ;
public String group(int group) {
if (first < 0)
throw new IllegalStateException("No match found");
if (group < 0 || group > groupCount())
throw new IndexOutOfBoundsException("No group " + group);
if ((groups[group*2] == -1) || (groups[group*2+1] == -1))
return null;
return getSubSequence(groups[group * 2], groups[group * 2 + 1]).toString();
}
CharSequence getSubSequence(int beginIndex, int endIndex) {
return text.subSequence(beginIndex, endIndex);
}
group It is also intercepting strings internally ,groups What is an array ? Why use group*2 You can get it ?
public final class Matcher implements MatchResult {
/** * The storage used by groups. They may contain invalid values if * a group was skipped during the matching. */
int[] groups;
...// A little
}
This is a non external attribute , either get Method or other methods can achieve , I have to try Reflection ;
/** * Reflect to get group Index * * @param clazz Matcher class * @param matcherInstance Matcher example * @return The index array */
public static int[] getOffsets(Class<Matcher> clazz, Object matcherInstance) {
try {
Field field = clazz.getDeclaredField("groups");
field.setAccessible(true);
return (int[]) field.get(matcherInstance);
} catch (NoSuchFieldException | IllegalAccessException e) {
e.printStackTrace();
}
return null;
}
Let's test it :
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(hex);
matcher.matches();
System.out.println(Arrays.toString(getOffsets(Matcher.class,matcher)));
Output :
[0, 17, 9, 11, 15, 17, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1]
According to our general understanding of regularity , We can know that the second 1 Group "0,17" The actual is group(0) That is, all matching content , That is, the starting index and the ending index in full match ;
that "9,11" Namely group(1) The start index and end index of ;
And so on ;
In this way, we can understand why we should use groups[group * 2], groups[group * 2 + 1] It can be used to intercept strings .
obviously , Regular after match , The corresponding boundary index has been recorded to groups In the array .
Isn't that …?
Implement replacement
Once you get the index , Everything is ready , It only needs to realize the cutting and splicing of strings by itself “ dongfeng ” 了 ;
Then there is
/** * Replace the corresponding group(n) The content of * * @param origin Original string * @param regex Fully matched regular , Add parentheses to the content that needs to be replaced to extract parameters * @param groupIndice group Indexes * @param content The final content array * @return Final content */
public static String replaceMatcherContent(String origin, String regex, int[] groupIndice, String... content) {
if (groupIndice.length != content.length) {
return origin;
}
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(origin);
if (matcher.matches()) {
int count = matcher.groupCount();
String[] resSubArray = new String[count * 2 + 1];
int[] offsets = getOffsets(Matcher.class, matcher);
if (offsets == null) {
return origin;
}
// Separate the parsed content
int lastIndex = 0;
for (int i = 1; i <= count; i++) {
int startIndex = offsets[i * 2];
int endIndex = offsets[i * 2 + 1];
resSubArray[i * 2 - 2] = origin.substring(lastIndex, startIndex);
resSubArray[i * 2 - 1] = origin.substring(startIndex, endIndex);
lastIndex = endIndex;
}
resSubArray[count * 2] = origin.substring(lastIndex);
// Replace the content in the corresponding position
for (int i = 0; i < groupIndice.length; i++) {
resSubArray[groupIndice[i] * 2 - 1] = content[i];
}
// Merge strings
StringBuilder sb = new StringBuilder();
for (String sub : resSubArray) {
sb.append(sub);
}
return sb.toString();
}
return origin;
}
Finally, it is written into a tool class , And then test it :
public static void main(String[] args) {
String hex = "00 00 00 01 00 01";
String regex = "[0-9a-zA-Z\\s]{6}[0-9a-zA-Z]{2}\\s([0-9a-zA-Z]{2})\\s[0-9a-zA-Z]{2}\\s([0-9a-zA-Z]{2})";
System.out.println(TextUtil.replaceMatcherContent(hex, regex, new int[]{
1, 2}, new String[]{
"1234", "2345"}));
}
Output :
00 00 00 1234 00 2345
success .
Maybe there are some small problems I didn't think of , But the basic idea at present is like this .
The code link can be clicked here .
边栏推荐
猜你喜欢

Custom components of wechat applet

1.东软跨境电商数仓需求规格说明文档
5.1数据采集通道搭建之业务数据采集通道搭建

软件过程与管理总复习

Using Flink SQL to fluidize market data 2: intraday var

2. Technology selection of Neusoft cross border e-commerce data warehouse project

gradle自定义插件

5. Business analysis of data acquisition channel construction

LiveData浅析
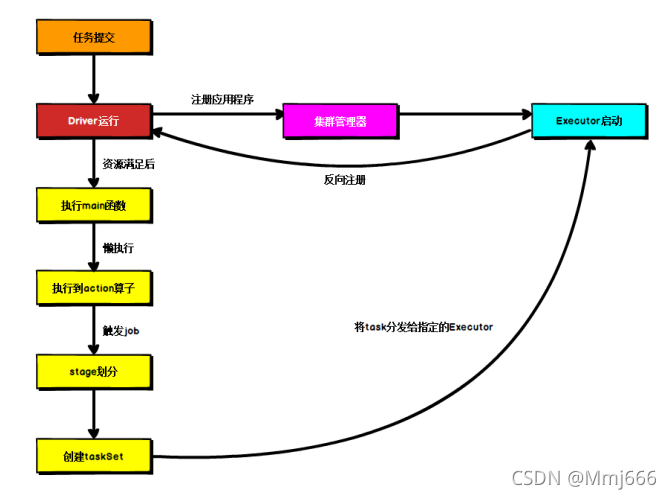
Spark核心编程(4)--Spark运行架构
随机推荐
sqlalchemy的两种方法详解
3.东软跨境电商数仓项目架构设计
Spark核心编程(4)--Spark运行架构
ES6 adds -let and const (disadvantages of VaR & let and const)
5. Spark核心编程(1)
10 question 10 answer: do you really know thread pools?
MySQL--触发器与视图
尝试解决YOLOv5推理rtsp有延迟的一些方法
12. Ads layer construction of data warehouse construction
Advanced operation of C language
Mysql逗号分隔的数据进行分行
12.数据仓库搭建之ADS层搭建
运行基于MindSpore的yolov5流程记录
Minor problems of GCC compiling C language in ubantu
typedef
SQL time comparison
Ambari cluster expansion node + expansion service operation
throttle/debounce应用及原理
Use of MySQL
7.数据仓库搭建之数据仓库环境准备