当前位置:网站首页>Parallel and distributed framework
Parallel and distributed framework
2022-07-18 20:00:00 【Grass in the crack of the wall】
List of articles
Parallel and distributed framework
Common techniques of parallel computing
Overview of shared memory system and distributed memory system

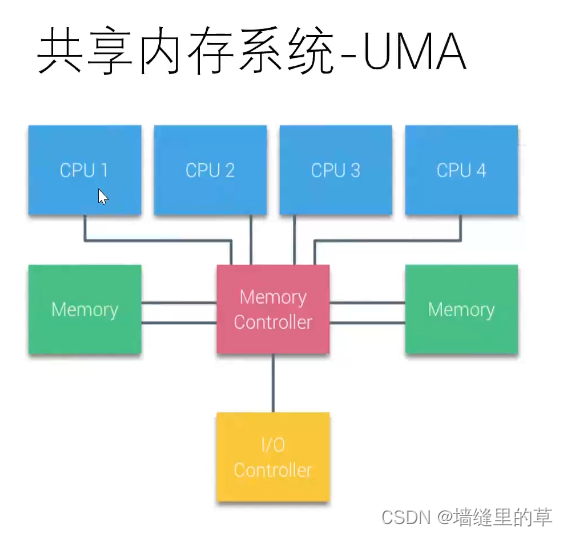

Unified memory access (UMA) System or symmetric multiprocessor (smp)
stay numa Inner multicore cpu according to cpu If the dominant frequency of is different, its affinity will also be different , The higher the dominant frequency, the higher the affinity , The lower the power consumption is .
OPENMP technology
(Open Multi-Processing, Open multiprocessing )
It is mainly used for parallel programming on shared memory computers , Support multi platform shared memory multi processor programming C/C++ and Fortran Language norms and API.
OPENMP Provide high-level abstraction for parallel description , It reduces the difficulty and complexity of the parallel Century City .
OpenMP Programming model
Adopt traditional fork-join Pattern , Memory is shared between control flows executed in parallel .
OpenMP Program single thread execution starts , stay parallel Pseudo instruction call , The main thread produces multiple sub threads 
shortcoming : It is not suitable for complex inter thread communication .
It is not very good to use on non shared memory systems .
OPENMP API constitute
Compile pseudo instructions
Pragma Pseudo instruction : Guide the compiler to process the corresponding code segment through identification , The compiler automatically parallelizes the program according to instructions , And add means such as synchronization and mutual exclusion .
eg:#pragma omp parallel
Runtime functions
eg:int omp_get_num_threads();
environment variable
eg: export OMP_THREAD_LIMIT=8
OpenMP Commonly used instructions
prallel, Used before a code snippet , Multiple threads will execute the code in parallel
for, be used for for Before the cycle , Allocate loops to multiple threads and execute them in parallel , It must be ensured that there is no correlation between each cycle .
prallfor,parallel and for Combination of statements , Also used in a for Before the cycle , Express for The code of the loop will be executed by multiple threads in parallel .
sections, Used before code segments that may be executed in parallel
pallel sctions, parallel and sections two A combination of sentences
citical,, Used before the critical area of a piece of code
singe, Used before a piece of code that is executed by a single thread , Indicates that the following code segment will be executed by a single thread .
brrier, Used for thread synchronization of code in parallel area , All threads execute to barrier Stop when , Until all threads execute to barrier Only then continues to carry on .
atomic, Used to specify that a memory area is updated
master, Used to specify that a block of code is executed by the main thread
ordered, The loops used to specify parallel regions are executed sequentially
thedpivate, Used to specify that a variable is thread private .
OpenMP Common functions
omp_ get_ num_ procs, Returns the number of processors of the multiprocessor running this thread .
omp get_ num_ threads, Returns the number of active threads in the current parallel region .
omp get. thread_ num, Returns the thread number
omp_ set. nugn threads, Set the number of threads when executing code in parallel
omp_ init Jock, Initialization one - A simple lock
omp_ set_ lock , Lock operation
omp_ unset_ lock, Unlock operation , Want to be with omp_ set_ lock Function pairing .
omp_ destroy_ lock ,omp_ init_ _lock Pairing operation function of function , Close a lock
OpenMP environment variable
●OMP NUM_ THREADS: Specify the default number of threads to use when executing parallel regions .
●OMP_ PROC_ BIND: Determines whether threads are allowed to migrate to other processors . Set to True when , The runtime does not migrate threads between processors .
●OMP THREAD_ LIMIT: Appoint The system can create OpenMP The maximum number of threads .
●OMP NESTED: Determines whether nested threads are supported ,True To support .
MPI technology
●MPI It's a cross language communication protocol . Support point-to-point and broadcast .
●MPI yes - - A messaging application interface , Including protocol and semantic description , They indicate how they can use their features in various implementations .
●MPI Our goal is high performance , Large scale , And portability .
● And OpenMP Parallel programs are different ,MPI It is a parallel programming technology based on information transmission .MPI The standard defines a set of portable programming interfaces .
MPI The messaging

MPI There are three phases in the messaging discipline :
1. The message assembly takes the sending data out of the sending buffer and adds the message envelope to form a complete message
2. Message passing passes the assembled message from the sender to the receiver
3. Message disassembly takes data from the received message and sends it to the receiving buffer
communicator
● Communicator defines ← Groups of processes that can send messages to each other . In this process , Each process will be assigned a large sequence number , It's called rank (rank)- Six processes communicate explicitly by specifying rank .
● Communication is based on sending and receiving operations between different processes .J– A process can pass . Specify another - The rank of processes and a unique message tag (tag) To send a message to another process . The recipient of a specific request can send a tag ( Or you can ignore the label completely , Receive any message ), Then process the received data in turn . A communication like this involving a sender and a receiver is called , Point to point (point-to-point) signal communication .
Nvidia NCCL technology
●NCCL yes Nvidia Collective multi-GPU Communication Library For short , It is an implementation of multiple GPU Of collective communication signal communication (all-gather, reduce, broadcast) library ,Nvidia do A lot of optimization , In the PCle、Nvlink、 InfiniBand. High communication speed is realized on .



边栏推荐
- 12.快速排序
- [200 opencv routines] 232 Spectral method of feature description
- Interview micro service
- Nc20566 [scoi2010] games
- Payment transaction snark in Mina
- 【读书会第13期】+FFmpeg命令
- wallys/QCA9880/ WiFi 5 (802.11ac) mini PCIe cards deliver higher Tx power and performance (Sponsored
- The difference between synchronized and lock
- Zkapp transaction snark in Mina
- An Amway note taking tool -- Obsidian
猜你喜欢

电力系统经济调度(Matlab完整代码实现)

leetcode 43. 字符串相乘 (字符串+模拟)

虚拟化架构

Full marks for all! The Chinese team IMO won four consecutive titles, leading the second place South Korea by a big score

Interview micro service

Chapter I FPGA digital signal processing_ Digital mixing (NCO and DDS)

OpenGL ES学习(4)——投影和绘制

老外还停留在20年前

Deadlock prevention, deadlock avoidance, deadlock detection
![[200 opencv routines] 232 Spectral method of feature description](/img/54/77f420654cc49723fbdbe845023ec8.png)
[200 opencv routines] 232 Spectral method of feature description
随机推荐
学生管理系统(简易低配版)
【OpenCV 例程200篇】232. 特征描述之頻譜方法
【word】公式排版问题
6. Violent recursion to dynamic planning
5. Thread separation
Vivado ROM IP core
Payment transaction snark in Mina
An Amway note taking tool -- Obsidian
Full marks for all! The Chinese team IMO won four consecutive titles, leading the second place South Korea by a big score
1.线程与进程
【MySql项目实战优化】多行数据转化为同一行多列显示
Horizon 8 测试环境部署(6): UAG 负载均衡配置-2
处理数字用中文表示
1.2.2-SQL注入-SQL注入语法类型-报错注入
第二篇 FPGA数字信号处理_并行FIR滤波器Verilog设计
简单介绍 MySQL 四类日志
[chance enlightenment -45]: Guiguzi - Chapter 9 - because people talk, like them
2.创建线程
Virtualization architecture
BUCK 电路PSIM仿真模型搭建之二 (传递函数模块的使用)